

Automating the generation of lexical patterns for processing free text in clinical documents
- PMID: 25977405
- PMCID: PMC4986670
- DOI: 10.1093/jamia/ocv012
Automating the generation of lexical patterns for processing free text in clinical documents
Abstract
Objective: Many tasks in natural language processing utilize lexical pattern-matching techniques, including information extraction (IE), negation identification, and syntactic parsing. However, it is generally difficult to derive patterns that achieve acceptable levels of recall while also remaining highly precise.
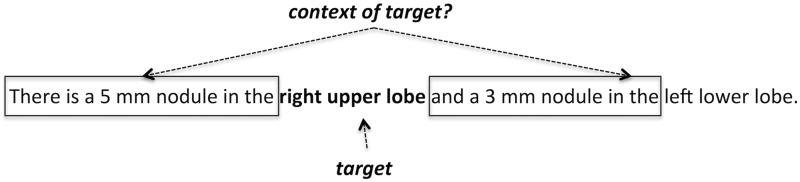
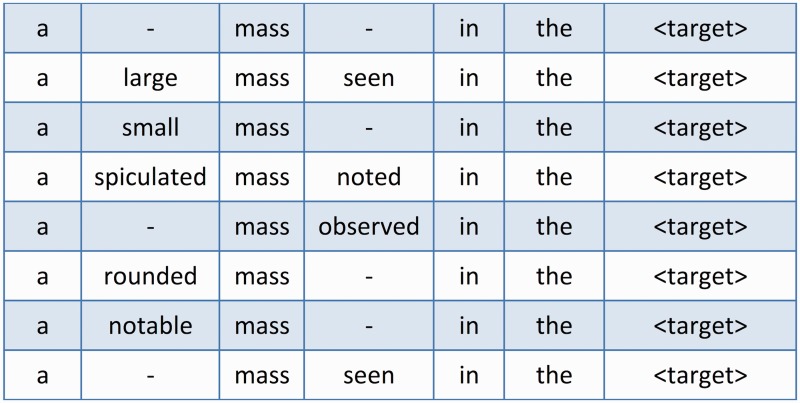
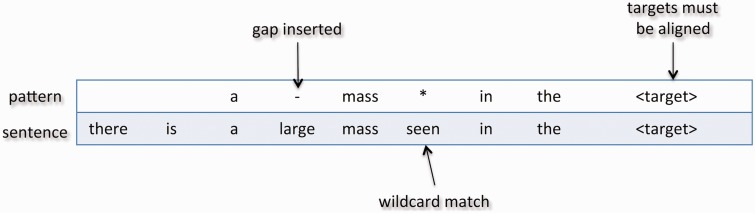
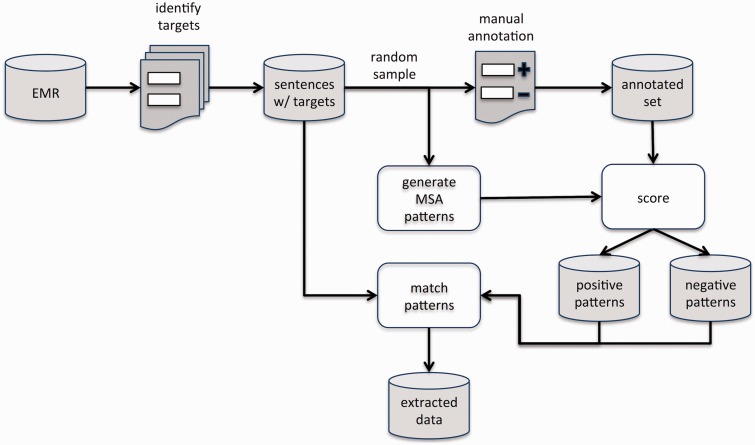
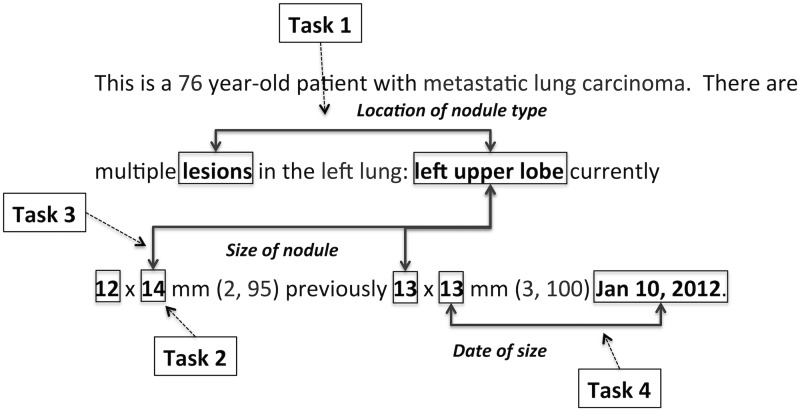
Materials and methods: We present a multiple sequence alignment (MSA)-based technique that automatically generates patterns, thereby leveraging language usage to determine the context of words that influence a given target. MSAs capture the commonalities among word sequences and are able to reveal areas of linguistic stability and variation. In this way, MSAs provide a systemic approach to generating lexical patterns that are generalizable, which will both increase recall levels and maintain high levels of precision.
Results: The MSA-generated patterns exhibited consistent F1-, F.5-, and F2- scores compared to two baseline techniques for IE across four different tasks. Both baseline techniques performed well for some tasks and less well for others, but MSA was found to consistently perform at a high level for all four tasks.
Discussion: The performance of MSA on the four extraction tasks indicates the method's versatility. The results show that the MSA-based patterns are able to handle the extraction of individual data elements as well as relations between two concepts without the need for large amounts of manual intervention.
Conclusion: We presented an MSA-based framework for generating lexical patterns that showed consistently high levels of both performance and recall over four different extraction tasks when compared to baseline methods.
Keywords: information extraction; natural language processing; text mining.
© The Author 2015. Published by Oxford University Press on behalf of the American Medical Informatics Association. All rights reserved. For Permissions, please email: journals.permissions@oup.com.
Figures

Similar articles
-
Active learning for ontological event extraction incorporating named entity recognition and unknown word handling.J Biomed Semantics. 2016 Apr 27;7:22. doi: 10.1186/s13326-016-0059-z. eCollection 2016. J Biomed Semantics. 2016. PMID: 27127603 Free PMC article.
-
A generalizable NLP framework for fast development of pattern-based biomedical relation extraction systems.BMC Bioinformatics. 2014 Aug 23;15(1):285. doi: 10.1186/1471-2105-15-285. BMC Bioinformatics. 2014. PMID: 25149151 Free PMC article.
-
A knowledge engineering approach to recognizing and extracting sequences of nucleic acids from scientific literature.Annu Int Conf IEEE Eng Med Biol Soc. 2010;2010:1081-4. doi: 10.1109/IEMBS.2010.5627316. Annu Int Conf IEEE Eng Med Biol Soc. 2010. PMID: 21096556
-
Natural Language Processing Technologies in Radiology Research and Clinical Applications.Radiographics. 2016 Jan-Feb;36(1):176-91. doi: 10.1148/rg.2016150080. Radiographics. 2016. PMID: 26761536 Free PMC article. Review.
-
Approaches to verb subcategorization for biomedicine.J Biomed Inform. 2013 Apr;46(2):212-27. doi: 10.1016/j.jbi.2012.12.001. Epub 2012 Dec 28. J Biomed Inform. 2013. PMID: 23276747 Review.
Cited by
-
Named Entity Recognition in Prehospital Trauma Care.Stud Health Technol Inform. 2019 Aug 21;264:1586-1587. doi: 10.3233/SHTI190547. Stud Health Technol Inform. 2019. PMID: 31438244 Free PMC article.
-
Clinical Natural Language Processing in 2015: Leveraging the Variety of Texts of Clinical Interest.Yearb Med Inform. 2016 Nov 10;(1):234-239. doi: 10.15265/IY-2016-049. Yearb Med Inform. 2016. PMID: 27830256 Free PMC article.
-
Enhanced Quality Measurement Event Detection: An Application to Physician Reporting.EGEMS (Wash DC). 2017 May 30;5(1):5. doi: 10.13063/2327-9214.1270. EGEMS (Wash DC). 2017. PMID: 29881731 Free PMC article.
References
-
- Chiticariu L, Li Y, Reiss F. Rule-Based Information Extraction is Dead! Long Live Rule-Based Information Extraction Systems! EMNLP. 2013:827–832.
-
- Yarowsky D. Unsupervised word sense disambiguation rivaling supervised methods. In: proceedings of the 33rd annual meeting on Association for Computational Linguistics (ACL '95). Association for Computational Linguistics; 1995:189–196; Stroudsburg, PA, USA
-
- Ko Y. A study of term weighting schemes using class information for text classification. In: proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval (SIGIR '12). ACM; 2012:1029–1030; New York, NY, USA.
-
- Carrillo M, López-López A. Concept based representations as complement of bag of words in information retrieval. AIAI, volume 339 of IFIP Advances in Information and Communication Technology, Springer; 2010:154–161.
-
- Tandon N, de Melo G. Information Extraction from Web-Scale N-Gram Data (2010). In: Proc. Web N-gram Workshop at SIGIR 2010:59-63;Association for Computing Machinery (ACM).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
