

A Scalable Approach for Protein False Discovery Rate Estimation in Large Proteomic Data Sets
- PMID: 25987413
- PMCID: PMC4563723
- DOI: 10.1074/mcp.M114.046995
A Scalable Approach for Protein False Discovery Rate Estimation in Large Proteomic Data Sets
Abstract
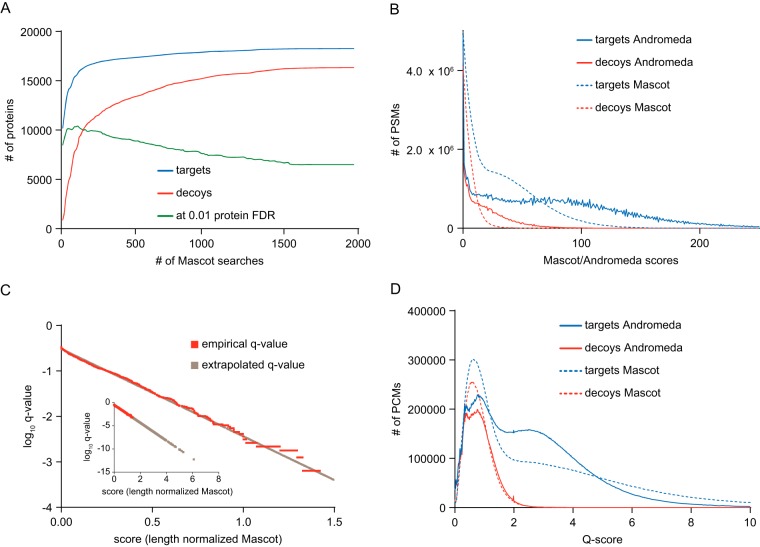
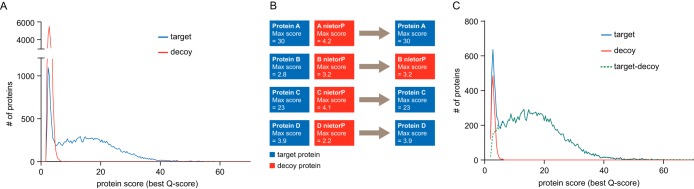
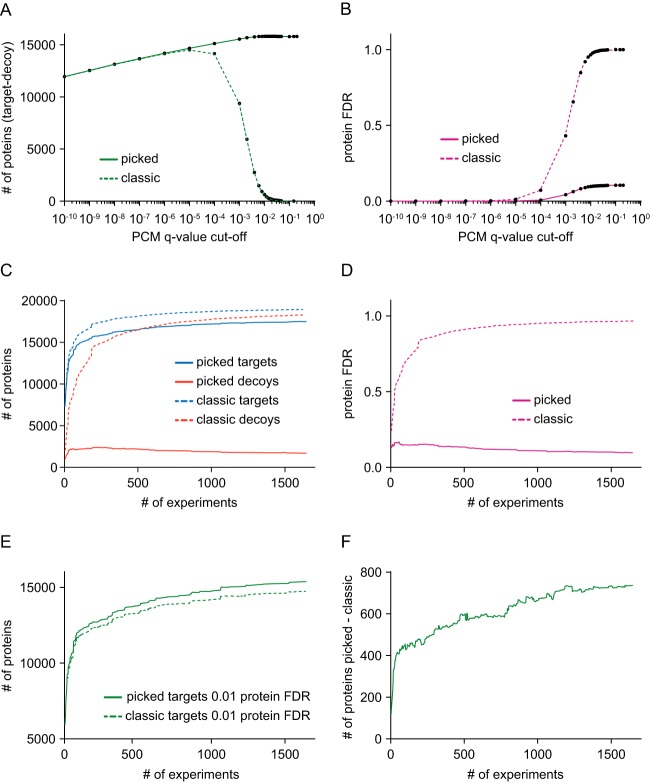
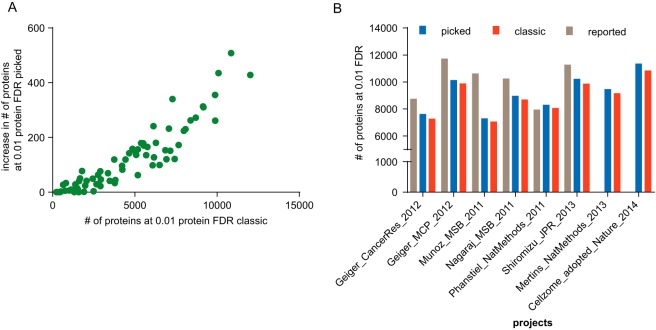
Calculating the number of confidently identified proteins and estimating false discovery rate (FDR) is a challenge when analyzing very large proteomic data sets such as entire human proteomes. Biological and technical heterogeneity in proteomic experiments further add to the challenge and there are strong differences in opinion regarding the conceptual validity of a protein FDR and no consensus regarding the methodology for protein FDR determination. There are also limitations inherent to the widely used classic target-decoy strategy that particularly show when analyzing very large data sets and that lead to a strong over-representation of decoy identifications. In this study, we investigated the merits of the classic, as well as a novel target-decoy-based protein FDR estimation approach, taking advantage of a heterogeneous data collection comprised of ∼19,000 LC-MS/MS runs deposited in ProteomicsDB (https://www.proteomicsdb.org). The "picked" protein FDR approach treats target and decoy sequences of the same protein as a pair rather than as individual entities and chooses either the target or the decoy sequence depending on which receives the highest score. We investigated the performance of this approach in combination with q-value based peptide scoring to normalize sample-, instrument-, and search engine-specific differences. The "picked" target-decoy strategy performed best when protein scoring was based on the best peptide q-value for each protein yielding a stable number of true positive protein identifications over a wide range of q-value thresholds. We show that this simple and unbiased strategy eliminates a conceptual issue in the commonly used "classic" protein FDR approach that causes overprediction of false-positive protein identification in large data sets. The approach scales from small to very large data sets without losing performance, consistently increases the number of true-positive protein identifications and is readily implemented in proteomics analysis software.
© 2015 by The American Society for Biochemistry and Molecular Biology, Inc.
Figures
References
-
- Scheltema R. A., Hauschild J. P., Lange O., Hornburg D., Denisov E., Damoc E., Kuehn A., Makarov A., Mann M. (2014) The Q Exactive hf, a benchtop mass spectrometer with a prefilter, high performance Quadrupole, and an ultra-high field Orbitrap analyzer. Mol. Cell. Proteomics 13, 3698–3708 - PMC - PubMed
-
- Kelstrup C. D., Jersie-Christensen R. R., Batth T. S., Arrey T. N., Kuehn A., Kellmann M., Olsen J. V. (2014) Rapid and deep proteomes by faster sequencing on a benchtop Quadrupole ultra-high-field Orbitrap mass spectrometer. J. Proteome Res. 3, 6187–95 - PubMed
-
- Helm D., Vissers J. P., Hughes C. J., Hahne H., Ruprecht B., Pachl F., Grzyb A., Richardson K., Wildgoose J., Maier S. K., Marx H., Wilhelm M., Becher I., Lemeer S., Bantscheff M., Langridge J. I., Kuster B. (2014) Ion mobility tandem mass spectrometry enhances performance of bottom-up proteomics. Mol. Cell. Proteomics 13, 3709–3715 - PMC - PubMed
-
- Yamana R., Iwasaki M., Wakabayashi M., Nakagawa M., Yamanaka S., Ishihama Y. (2013) Rapid and deep profiling of human induced pluripotent stem cell proteome by one-shot NanoLC-MS/MS analysis with meter-scale monolithic silica columns. J. Proteome Res. 12, 214–221 - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
