

Reinforcement learning in multidimensional environments relies on attention mechanisms
- PMID: 26019331
- PMCID: PMC4444538
- DOI: 10.1523/JNEUROSCI.2978-14.2015
Reinforcement learning in multidimensional environments relies on attention mechanisms
Abstract
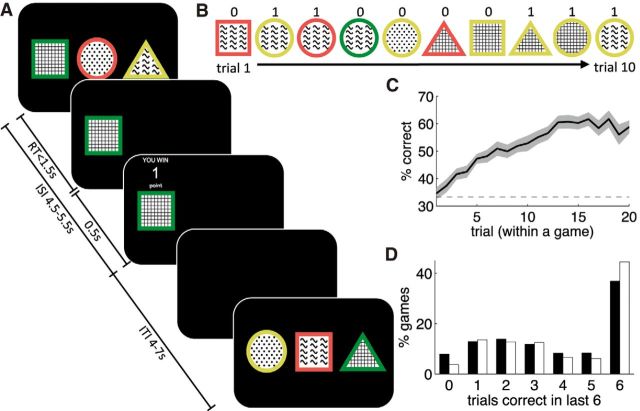
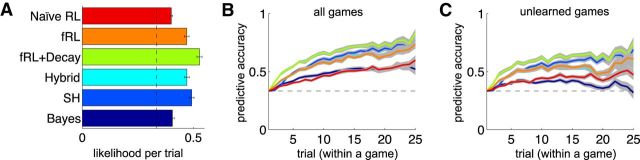
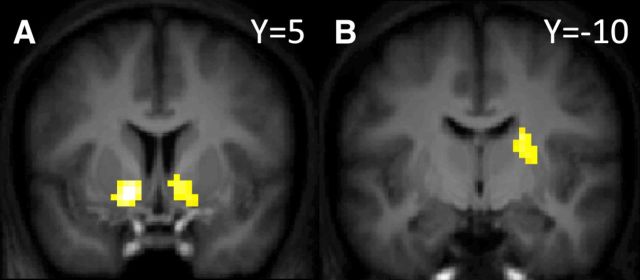
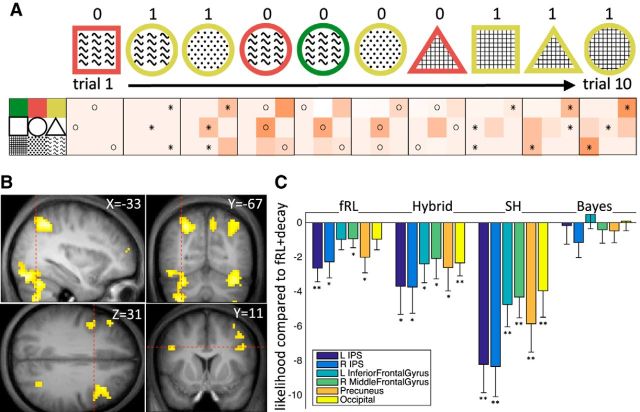
In recent years, ideas from the computational field of reinforcement learning have revolutionized the study of learning in the brain, famously providing new, precise theories of how dopamine affects learning in the basal ganglia. However, reinforcement learning algorithms are notorious for not scaling well to multidimensional environments, as is required for real-world learning. We hypothesized that the brain naturally reduces the dimensionality of real-world problems to only those dimensions that are relevant to predicting reward, and conducted an experiment to assess by what algorithms and with what neural mechanisms this "representation learning" process is realized in humans. Our results suggest that a bilateral attentional control network comprising the intraparietal sulcus, precuneus, and dorsolateral prefrontal cortex is involved in selecting what dimensions are relevant to the task at hand, effectively updating the task representation through trial and error. In this way, cortical attention mechanisms interact with learning in the basal ganglia to solve the "curse of dimensionality" in reinforcement learning.
Keywords: attention; fMRI; frontoparietal network; model comparison; reinforcement learning; representation learning.
Copyright © 2015 the authors 0270-6474/15/358145-13$15.00/0.
Figures
Comment in
-
Neural Mechanisms for Undoing the "Curse of Dimensionality".J Neurosci. 2015 Sep 2;35(35):12083-4. doi: 10.1523/JNEUROSCI.2428-15.2015. J Neurosci. 2015. PMID: 26338319 Free PMC article. No abstract available.
References
-
- Bar-Gad I, Havazelet-Heimer G, Goldberg JA, Ruppin E, Bergman H. Reinforcement-driven dimensionality reduction-a model for information processing in the basal ganglia. J Basic Clin Physiol Pharmacol. 2000;11:305–320. - PubMed
-
- Barto AG. Adaptive critic and the basal ganglia. In: Houk JC, Davis JL, Beiser DG, editors. Models of information processing in the basal ganglia. Cambridge, MA: MIT; 1995. pp. 215–232.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources