

Musical training, individual differences and the cocktail party problem
- PMID: 26112910
- PMCID: PMC4481518
- DOI: 10.1038/srep11628
Musical training, individual differences and the cocktail party problem
Erratum in
-
Erratum: Musical training, individual differences and the cocktail party problem.Sci Rep. 2015 Sep 25;5:14401. doi: 10.1038/srep14401. Sci Rep. 2015. PMID: 26403289 Free PMC article. No abstract available.
Abstract
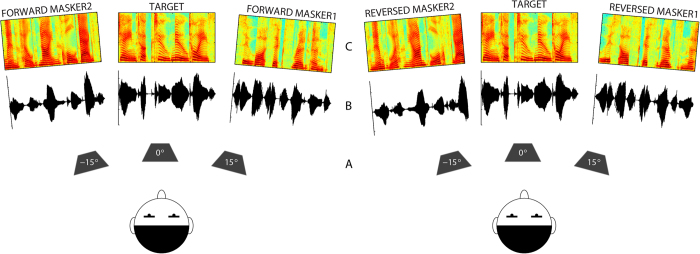
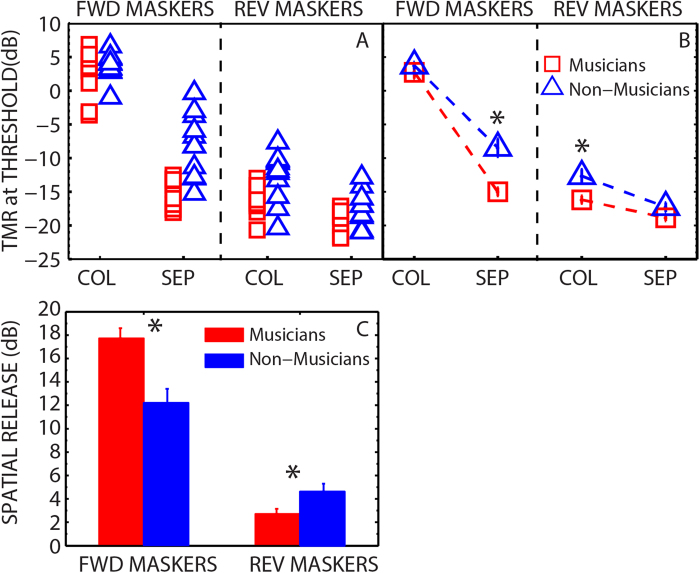
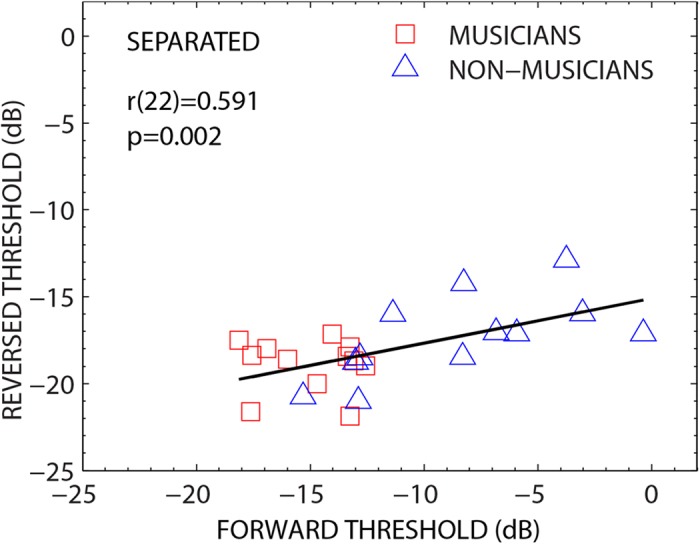
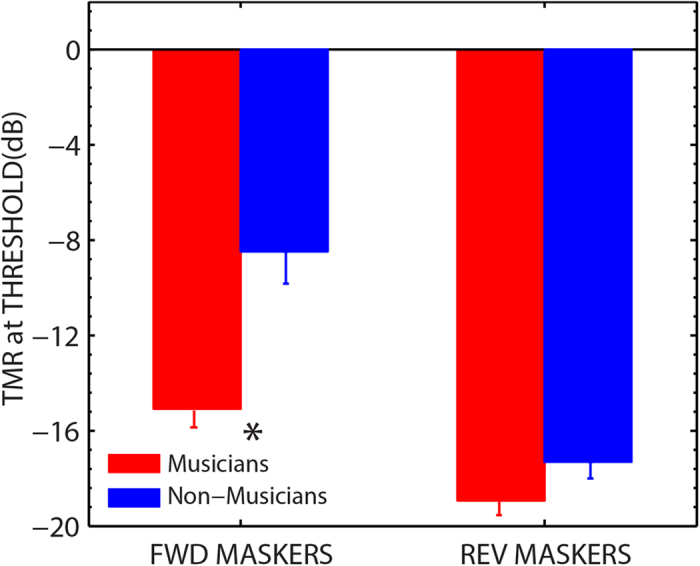
Are musicians better able to understand speech in noise than non-musicians? Recent findings have produced contradictory results. Here we addressed this question by asking musicians and non-musicians to understand target sentences masked by other sentences presented from different spatial locations, the classical 'cocktail party problem' in speech science. We found that musicians obtained a substantial benefit in this situation, with thresholds ~6 dB better than non-musicians. Large individual differences in performance were noted particularly for the non-musically trained group. Furthermore, in different conditions we manipulated the spatial location and intelligibility of the masking sentences, thus changing the amount of 'informational masking' (IM) while keeping the amount of 'energetic masking' (EM) relatively constant. When the maskers were unintelligible and spatially separated from the target (low in IM), musicians and non-musicians performed comparably. These results suggest that the characteristics of speech maskers and the amount of IM can influence the magnitude of the differences found between musicians and non-musicians in multiple-talker "cocktail party" environments. Furthermore, considering the task in terms of the EM-IM distinction provides a conceptual framework for future behavioral and neuroscientific studies which explore the underlying sensory and cognitive mechanisms contributing to enhanced "speech-in-noise" perception by musicians.
Figures
Similar articles
-
Executive Function, Visual Attention and the Cocktail Party Problem in Musicians and Non-Musicians.PLoS One. 2016 Jul 6;11(7):e0157638. doi: 10.1371/journal.pone.0157638. eCollection 2016. PLoS One. 2016. PMID: 27384330 Free PMC article.
-
Musicians and non-musicians are equally adept at perceiving masked speech.J Acoust Soc Am. 2015 Jan;137(1):378-87. doi: 10.1121/1.4904537. J Acoust Soc Am. 2015. PMID: 25618067 Free PMC article.
-
Effect of priming on energetic and informational masking in a same-different task.Ear Hear. 2012 Jan-Feb;33(1):124-33. doi: 10.1097/AUD.0b013e31822b5bee. Ear Hear. 2012. PMID: 21841488 Free PMC article.
-
Speech-in-noise perception in musicians: A review.Hear Res. 2017 Sep;352:49-69. doi: 10.1016/j.heares.2017.02.006. Epub 2017 Feb 14. Hear Res. 2017. PMID: 28213134 Review.
-
Are musical activities associated with enhanced speech perception in noise in adults? A systematic review and meta-analysis.Curr Res Neurobiol. 2023 Mar 24;4:100083. doi: 10.1016/j.crneur.2023.100083. eCollection 2023. Curr Res Neurobiol. 2023. PMID: 37397808 Free PMC article. Review.
Cited by
-
Executive Function, Visual Attention and the Cocktail Party Problem in Musicians and Non-Musicians.PLoS One. 2016 Jul 6;11(7):e0157638. doi: 10.1371/journal.pone.0157638. eCollection 2016. PLoS One. 2016. PMID: 27384330 Free PMC article.
-
Neurophysiological improvements in speech-in-noise task after short-term choir training in older adults.Aging (Albany NY). 2021 Apr 6;13(7):9468-9495. doi: 10.18632/aging.202931. Epub 2021 Apr 6. Aging (Albany NY). 2021. PMID: 33824226 Free PMC article.
-
The role of rhythm in perceiving speech in noise: a comparison of percussionists, vocalists and non-musicians.Cogn Process. 2016 Feb;17(1):79-87. doi: 10.1007/s10339-015-0740-7. Epub 2015 Oct 7. Cogn Process. 2016. PMID: 26445880 Free PMC article.
-
A test of model classes accounting for individual differences in the cocktail-party effect.J Acoust Soc Am. 2020 Dec;148(6):4014. doi: 10.1121/10.0002961. J Acoust Soc Am. 2020. PMID: 33379927 Free PMC article.
-
Temporal Fine-Structure Coding and Lateralized Speech Perception in Normal-Hearing and Hearing-Impaired Listeners.Trends Hear. 2016 Sep 5;20:2331216516660962. doi: 10.1177/2331216516660962. Trends Hear. 2016. PMID: 27601071 Free PMC article.
References
-
- Angulo-Perkins A. et al. Music listening engages specific cortical regions within the temporal lobes: Differences between musicians and non-musicians. Cortex 59, 126–137 (2014). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
