

Metabolite profiling stratifies pancreatic ductal adenocarcinomas into subtypes with distinct sensitivities to metabolic inhibitors
- PMID: 26216984
- PMCID: PMC4538616
- DOI: 10.1073/pnas.1501605112
Metabolite profiling stratifies pancreatic ductal adenocarcinomas into subtypes with distinct sensitivities to metabolic inhibitors
Abstract
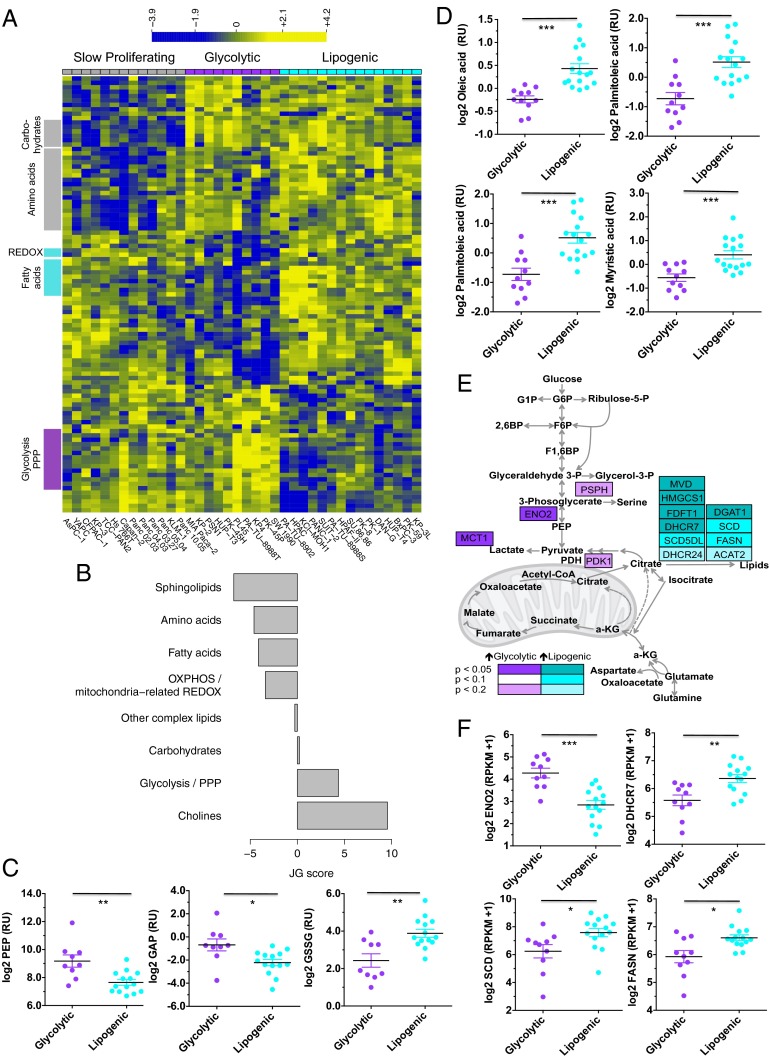
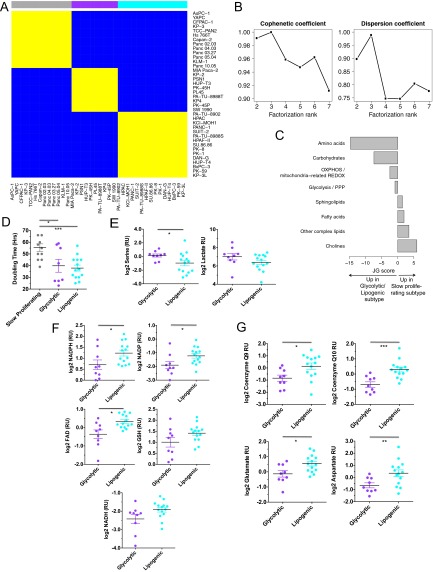
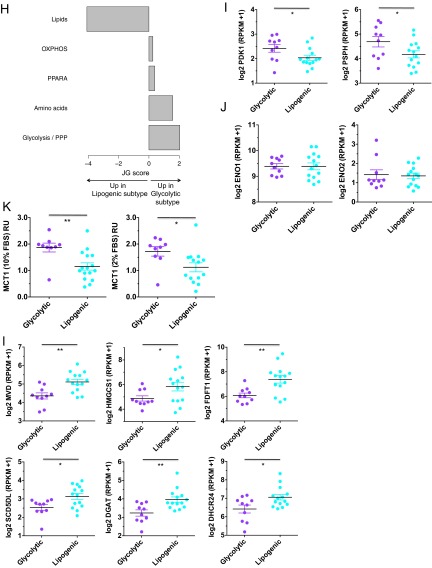
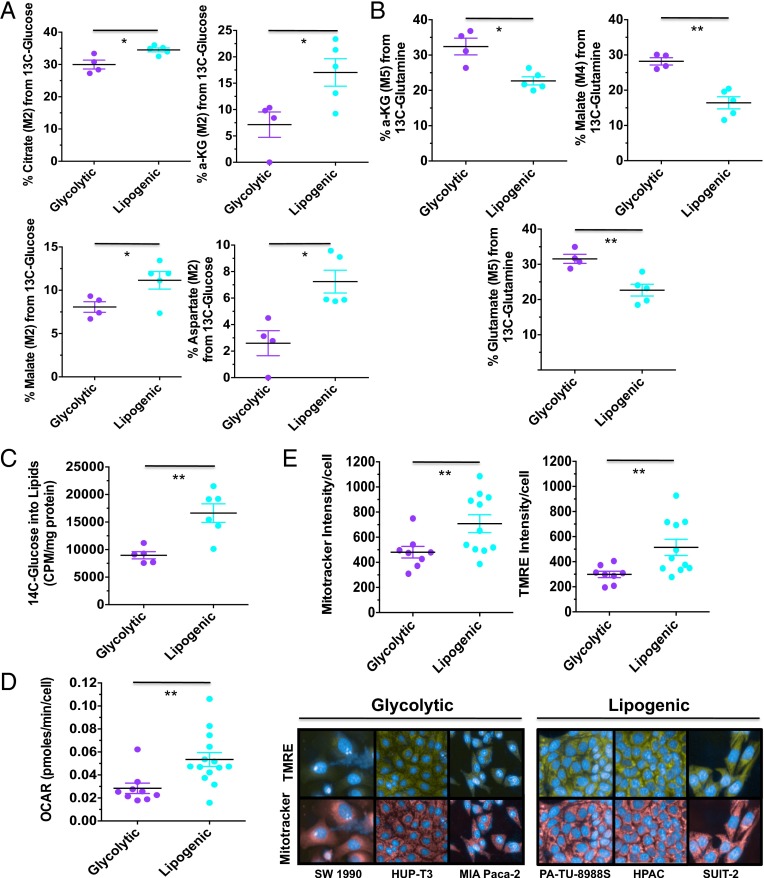
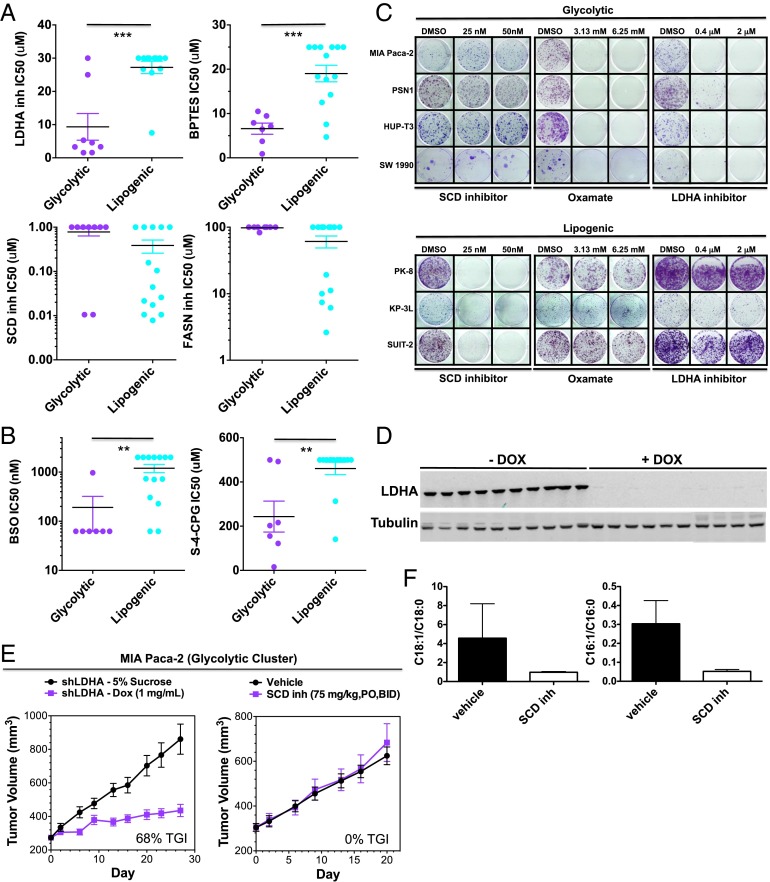
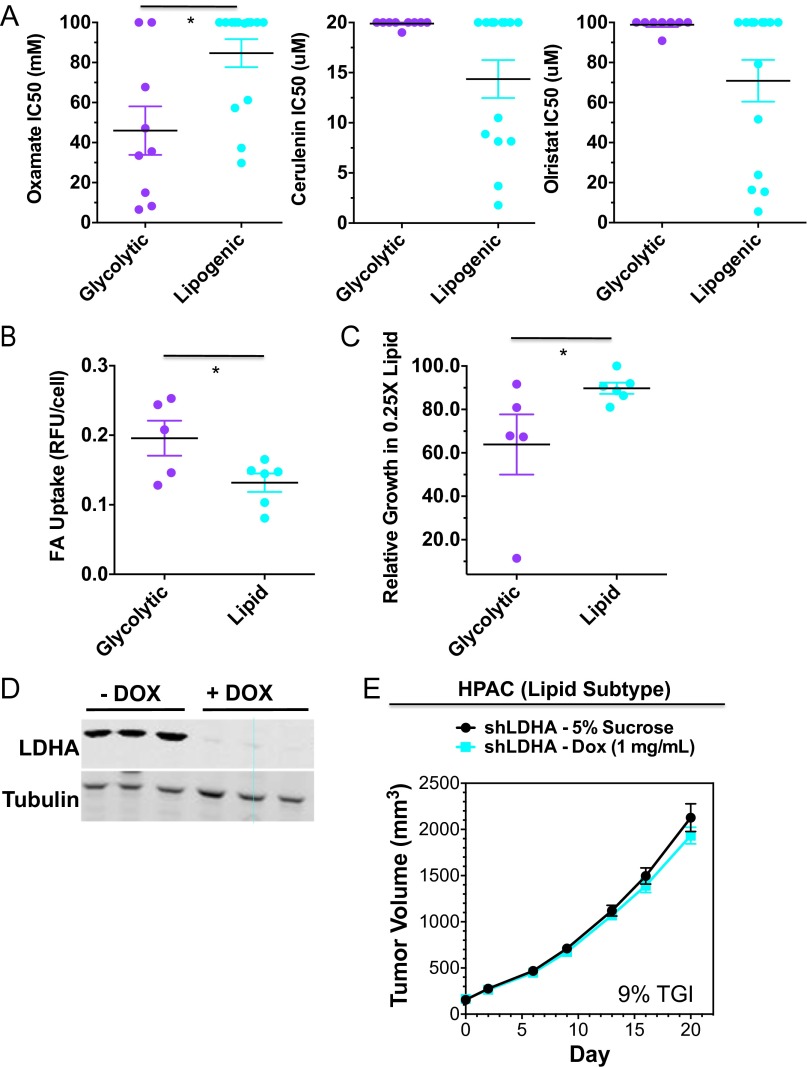
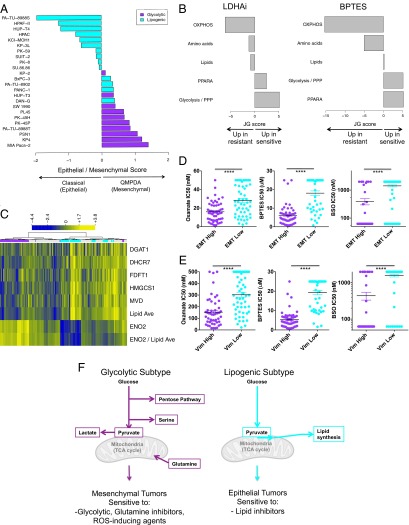
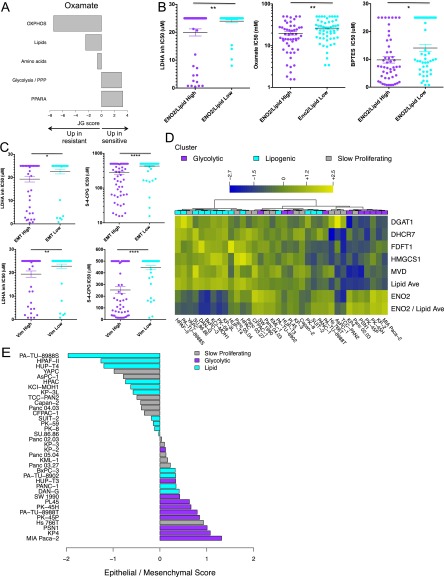
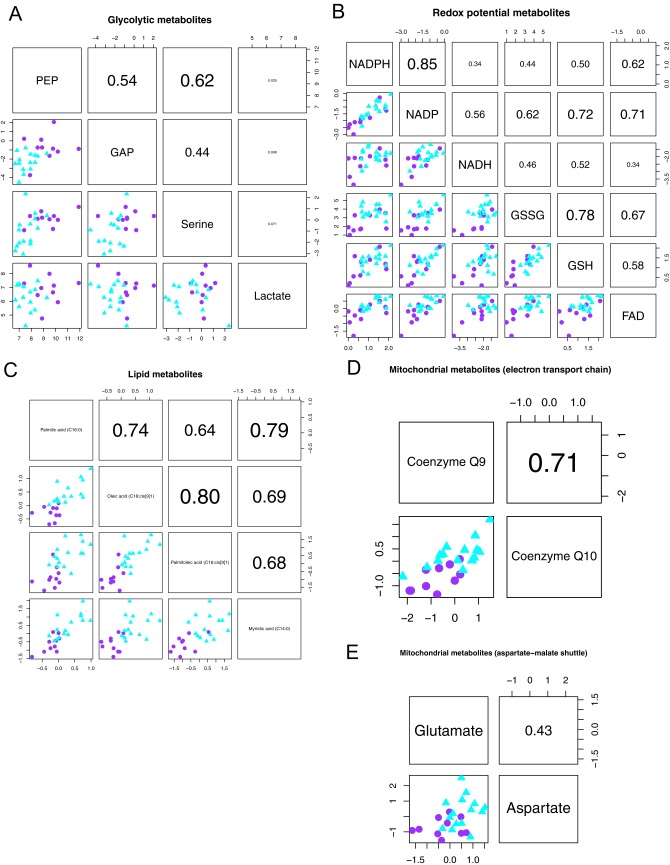
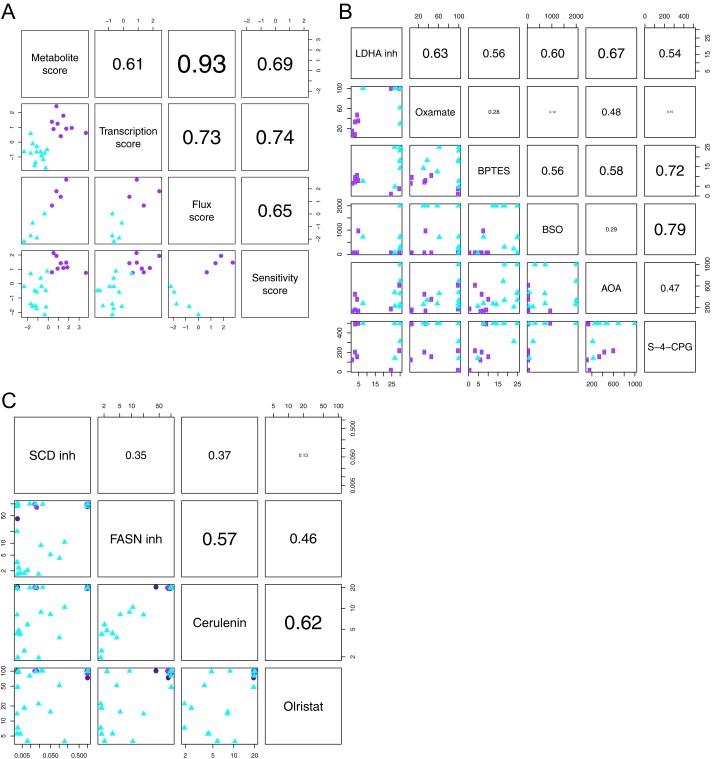
Although targeting cancer metabolism is a promising therapeutic strategy, clinical success will depend on an accurate diagnostic identification of tumor subtypes with specific metabolic requirements. Through broad metabolite profiling, we successfully identified three highly distinct metabolic subtypes in pancreatic ductal adenocarcinoma (PDAC). One subtype was defined by reduced proliferative capacity, whereas the other two subtypes (glycolytic and lipogenic) showed distinct metabolite levels associated with glycolysis, lipogenesis, and redox pathways, confirmed at the transcriptional level. The glycolytic and lipogenic subtypes showed striking differences in glucose and glutamine utilization, as well as mitochondrial function, and corresponded to differences in cell sensitivity to inhibitors of glycolysis, glutamine metabolism, lipid synthesis, and redox balance. In PDAC clinical samples, the lipogenic subtype associated with the epithelial (classical) subtype, whereas the glycolytic subtype strongly associated with the mesenchymal (QM-PDA) subtype, suggesting functional relevance in disease progression. Pharmacogenomic screening of an additional ∼ 200 non-PDAC cell lines validated the association between mesenchymal status and metabolic drug response in other tumor indications. Our findings highlight the utility of broad metabolite profiling to predict sensitivity of tumors to a variety of metabolic inhibitors.
Keywords: biomarkers for metabolic inhibitors; glycolysis; lipid synthesis; metabolic subtypes in PDAC; metabolite profiling.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Warburg O, Posener K, Negelein E. On the metabolism of carcinoma cells. Biochem Z. 1924;152:309–344.
-
- Hsu PP, Sabatini DM. Cancer cell metabolism: Warburg and beyond. Cell. 2008;134(5):703–707. - PubMed
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
