

Automatic detection of protected health information from clinic narratives
- PMID: 26231070
- PMCID: PMC4989090
- DOI: 10.1016/j.jbi.2015.06.015
Automatic detection of protected health information from clinic narratives
Abstract
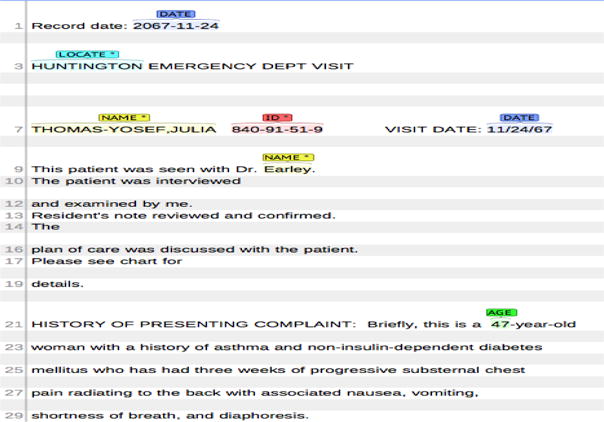
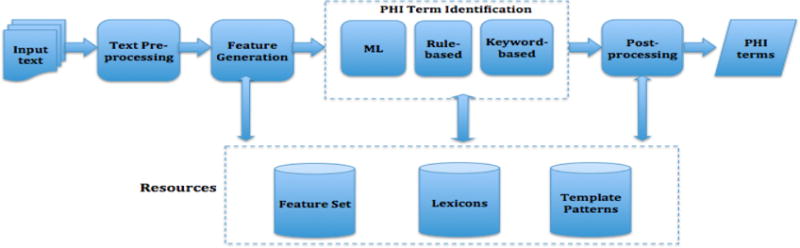
This paper presents a natural language processing (NLP) system that was designed to participate in the 2014 i2b2 de-identification challenge. The challenge task aims to identify and classify seven main Protected Health Information (PHI) categories and 25 associated sub-categories. A hybrid model was proposed which combines machine learning techniques with keyword-based and rule-based approaches to deal with the complexity inherent in PHI categories. Our proposed approaches exploit a rich set of linguistic features, both syntactic and word surface-oriented, which are further enriched by task-specific features and regular expression template patterns to characterize the semantics of various PHI categories. Our system achieved promising accuracy on the challenge test data with an overall micro-averaged F-measure of 93.6%, which was the winner of this de-identification challenge.
Keywords: Clinical text mining; De-identification; Hybrid model; Natural language processing; Protected Health Information (PHI).
Copyright © 2015 Elsevier Inc. All rights reserved.
Figures
References
-
- Aberdeen J, Bayer S, Yeniterzi R, et al. The MITRE Identification Scrubber Toolkit: design, training, and assessment. Int J Med Inform. 2010;79:849–59. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
