

Computational approaches to natural product discovery
- PMID: 26284671
- PMCID: PMC5024737
- DOI: 10.1038/nchembio.1884
Computational approaches to natural product discovery
Abstract
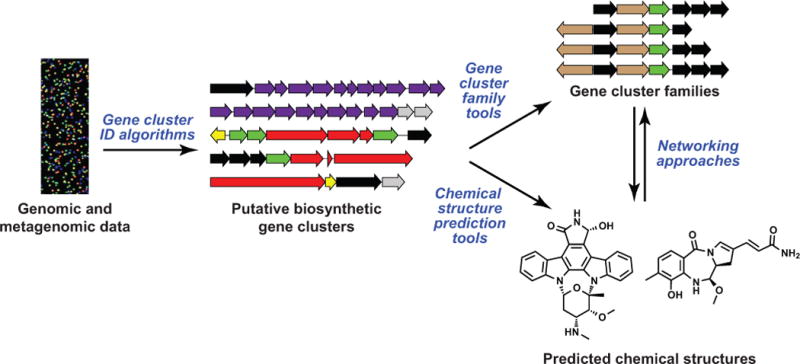
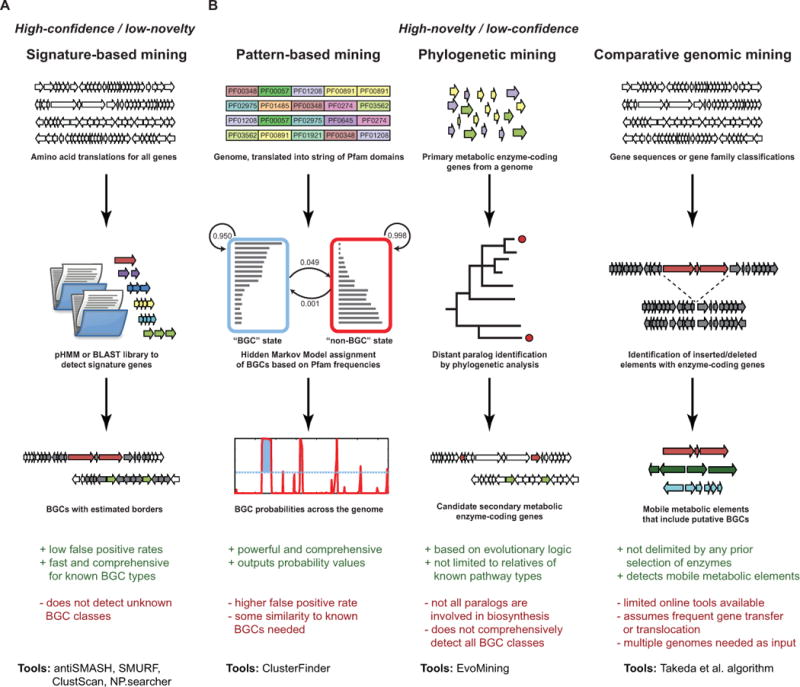
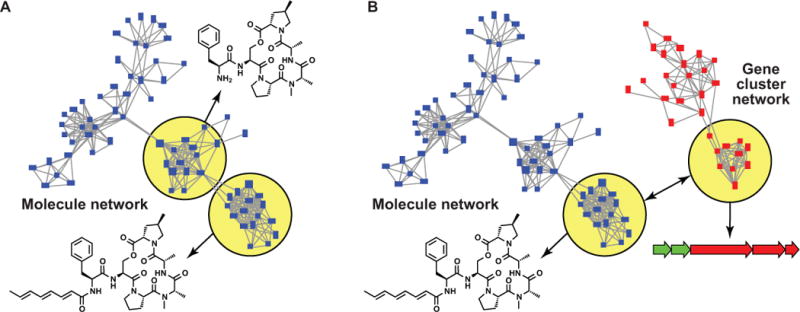
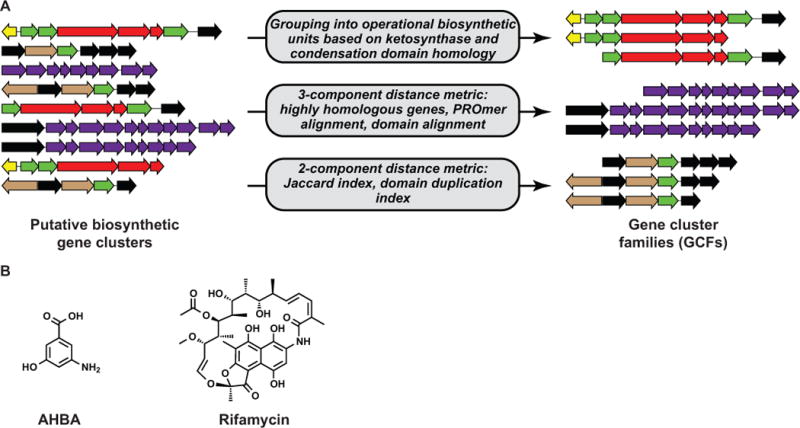
Starting with the earliest Streptomyces genome sequences, the promise of natural product genome mining has been captivating: genomics and bioinformatics would transform compound discovery from an ad hoc pursuit to a high-throughput endeavor. Until recently, however, genome mining has advanced natural product discovery only modestly. Here, we argue that the development of algorithms to mine the continuously increasing amounts of (meta)genomic data will enable the promise of genome mining to be realized. We review computational strategies that have been developed to identify biosynthetic gene clusters in genome sequences and predict the chemical structures of their products. We then discuss networking strategies that can systematize large volumes of genetic and chemical data and connect genomic information to metabolomic and phenotypic data. Finally, we provide a vision of what natural product discovery might look like in the future, specifically considering longstanding questions in microbial ecology regarding the roles of metabolites in interspecies interactions.
Conflict of interest statement
M.A.F. is on the scientific advisory boards of NGM Biopharmaceuticals and Warp Drive Bio.
Figures
References
-
- Bentley SD, et al. Complete genome sequence of the model actinomycete Streptomyces coelicolor A3 (2) Nature. 2002;417:141–147. - PubMed
-
- Ikeda H, et al. Complete genome sequence and comparative analysis of the industrial microorganism Streptomyces avermitilis. Nat Biotechnol. 2003;21:526–531. - PubMed
-
- Medema MH, Breitling R, Bovenberg R, Takano E. Exploiting plug-and-play synthetic biology for drug discovery and production in microorganisms. Nat Rev Microbiol. 2011;9:131–7. - PubMed
-
- Krug D, Müller R. Secondary metabolomics: the impact of mass spectrometry-based approaches on the discovery and characterization of microbial natural products. Nat Prod Rep. 2014;31:768–83. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
