

Annotating longitudinal clinical narratives for de-identification: The 2014 i2b2/UTHealth corpus
- PMID: 26319540
- PMCID: PMC4978170
- DOI: 10.1016/j.jbi.2015.07.020
Annotating longitudinal clinical narratives for de-identification: The 2014 i2b2/UTHealth corpus
Abstract
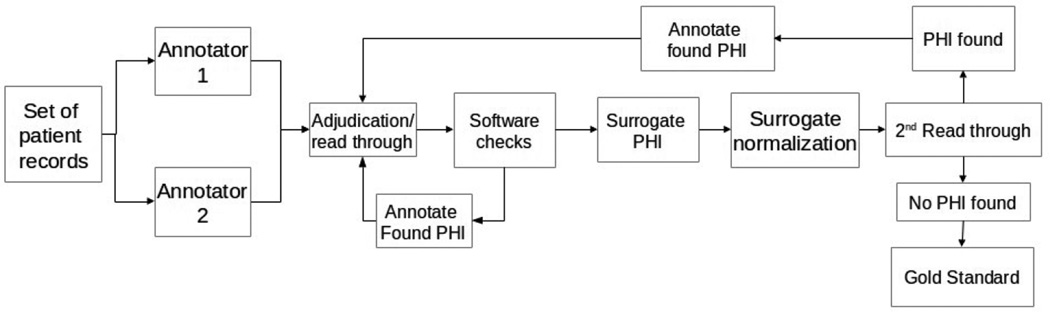
The 2014 i2b2/UTHealth natural language processing shared task featured a track focused on the de-identification of longitudinal medical records. For this track, we de-identified a set of 1304 longitudinal medical records describing 296 patients. This corpus was de-identified under a broad interpretation of the HIPAA guidelines using double-annotation followed by arbitration, rounds of sanity checking, and proof reading. The average token-based F1 measure for the annotators compared to the gold standard was 0.927. The resulting annotations were used both to de-identify the data and to set the gold standard for the de-identification track of the 2014 i2b2/UTHealth shared task. All annotated private health information were replaced with realistic surrogates automatically and then read over and corrected manually. The resulting corpus is the first of its kind made available for de-identification research. This corpus was first used for the 2014 i2b2/UTHealth shared task, during which the systems achieved a mean F-measure of 0.872 and a maximum F-measure of 0.964 using entity-based micro-averaged evaluations.
Keywords: Annotation; De-identification; HIPAA; Natural language processing.
Copyright © 2015 Elsevier Inc. All rights reserved.
Figures


References
-
- Carroll RJ, Thompson WK, Eyler AE, Mandelin AM, Cai T, Zink RM, Pacheco JA, Boomershine CS, Lasko TA, Xu H, Karlson EW, Perez RG, Gainer VS, Murphy SN, Ruderman EM, Pope RM, Plenge RM, Ngo Kho A, Liao KP, Denny JC. Portability of an algorithm to identify rheumatoid arthritis in electronic health records. Journal of the American Informatics Association. 2012 Jun;19(e1):e162–e169. - PMC - PubMed
-
- Goldberger AL, Amaral LAN, Glass L, Hausdorff JM, Ivanov PCh, Mark RG, Mietus JE, Moody GB, Peng C-K, Stanley HE. PhysioBank, PhysioToolkit, and Physionet: Components of a New Research Resource for Complex Physiologic Signals. Circulation. 2000 Jun 13;101(23):e215–e220. [Circulation Electronic Pages; http://circ.ahajournals.org/cgi/content/full/101/23/e215] - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
