

Large-scale extraction of gene interactions from full-text literature using DeepDive
- PMID: 26338771
- PMCID: PMC4681986
- DOI: 10.1093/bioinformatics/btv476
Large-scale extraction of gene interactions from full-text literature using DeepDive
Abstract
Motivation: A complete repository of gene-gene interactions is key for understanding cellular processes, human disease and drug response. These gene-gene interactions include both protein-protein interactions and transcription factor interactions. The majority of known interactions are found in the biomedical literature. Interaction databases, such as BioGRID and ChEA, annotate these gene-gene interactions; however, curation becomes difficult as the literature grows exponentially. DeepDive is a trained system for extracting information from a variety of sources, including text. In this work, we used DeepDive to extract both protein-protein and transcription factor interactions from over 100,000 full-text PLOS articles.
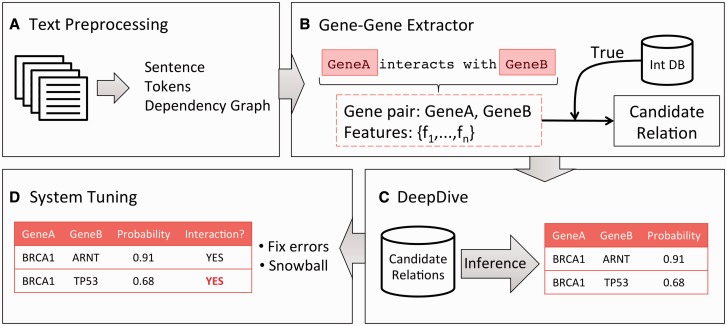
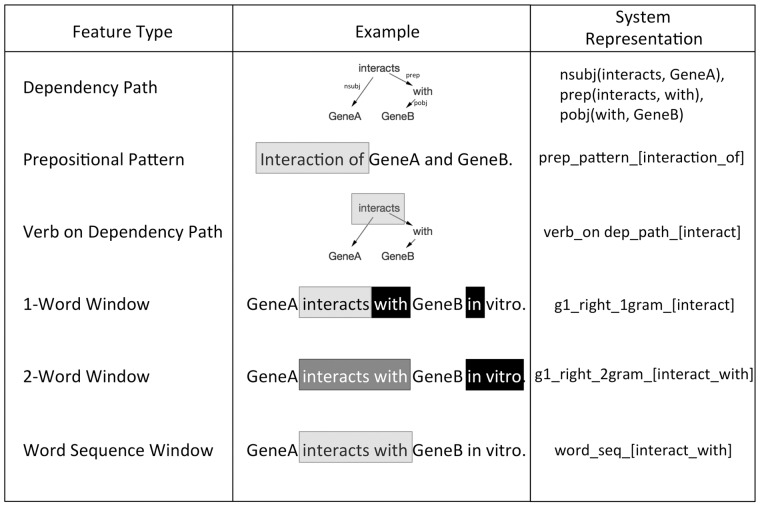
Methods: We built an extractor for gene-gene interactions that identified candidate gene-gene relations within an input sentence. For each candidate relation, DeepDive computed a probability that the relation was a correct interaction. We evaluated this system against the Database of Interacting Proteins and against randomly curated extractions.
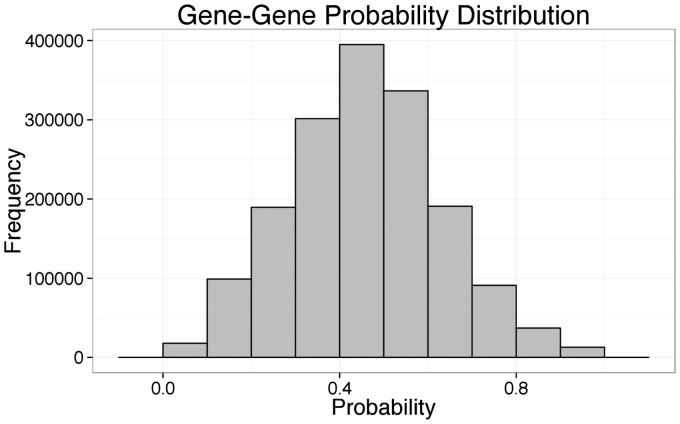
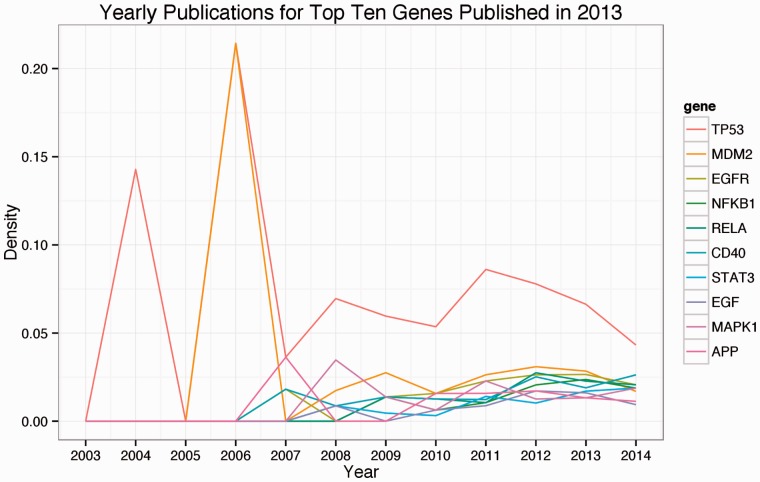
Results: Our system achieved 76% precision and 49% recall in extracting direct and indirect interactions involving gene symbols co-occurring in a sentence. For randomly curated extractions, the system achieved between 62% and 83% precision based on direct or indirect interactions, as well as sentence-level and document-level precision. Overall, our system extracted 3356 unique gene pairs using 724 features from over 100,000 full-text articles.
Availability and implementation: Application source code is publicly available at https://github.com/edoughty/deepdive_genegene_app
Contact: russ.altman@stanford.edu
Supplementary information: Supplementary data are available at Bioinformatics online.
© The Author 2015. Published by Oxford University Press.
Figures
References
-
- Chen Y., et al. (2014) An ensemble self-training protein interaction article classifier. Biomed. Mater. Eng., 24, 1323–1332. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
