

Prospective Optimization with Limited Resources
- PMID: 26367309
- PMCID: PMC4569291
- DOI: 10.1371/journal.pcbi.1004501
Prospective Optimization with Limited Resources
Abstract
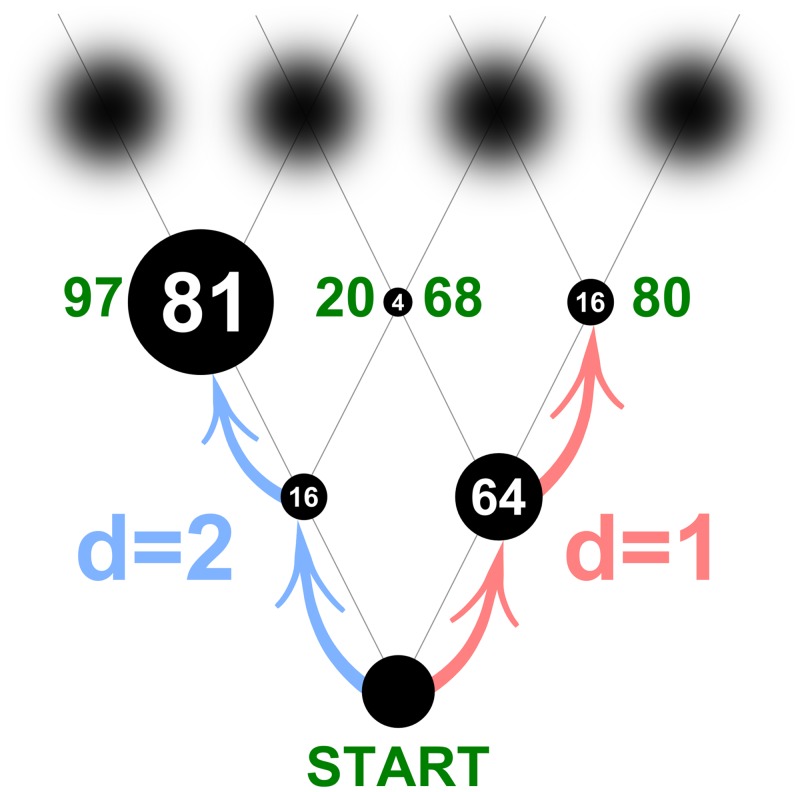
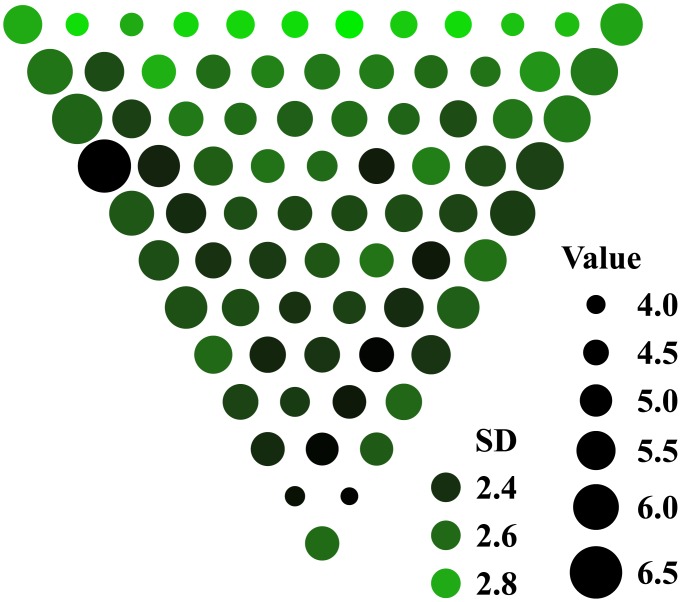
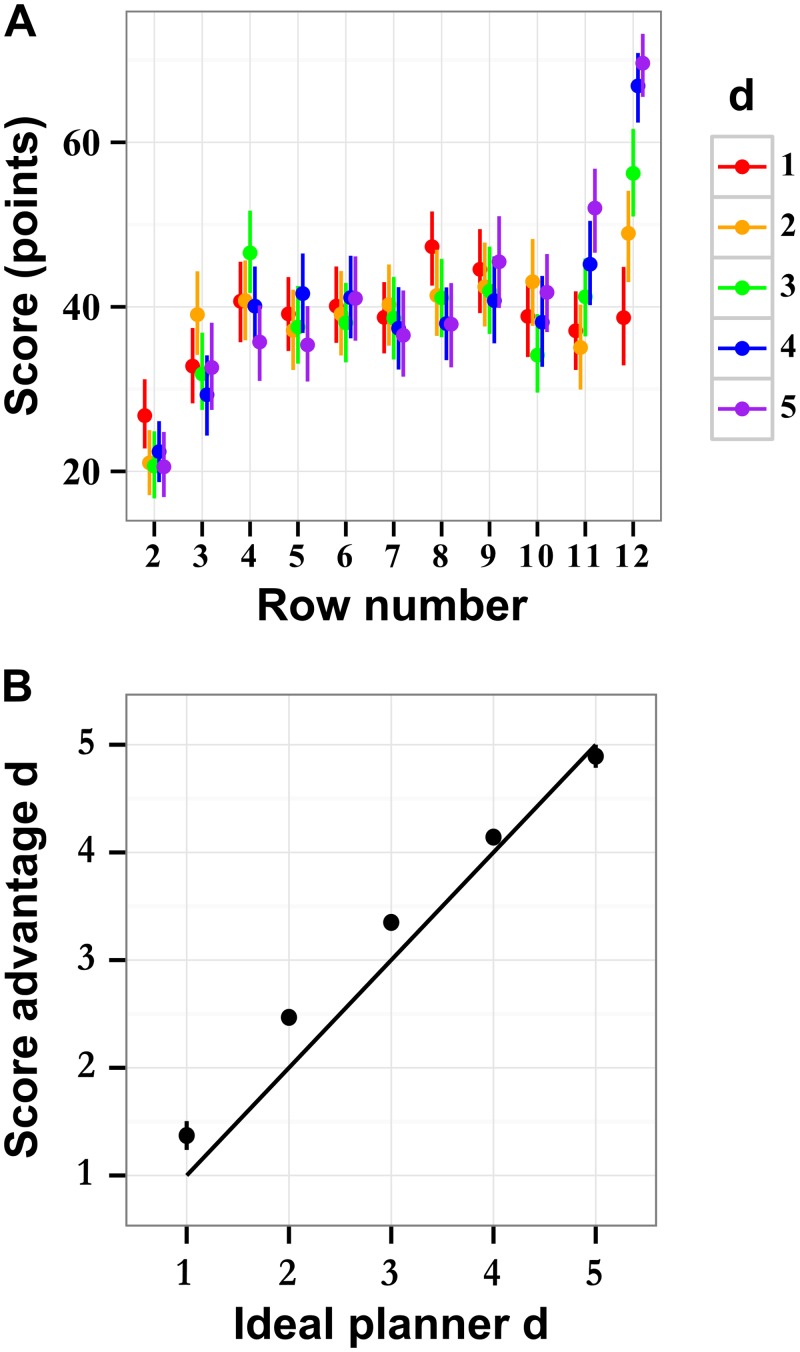
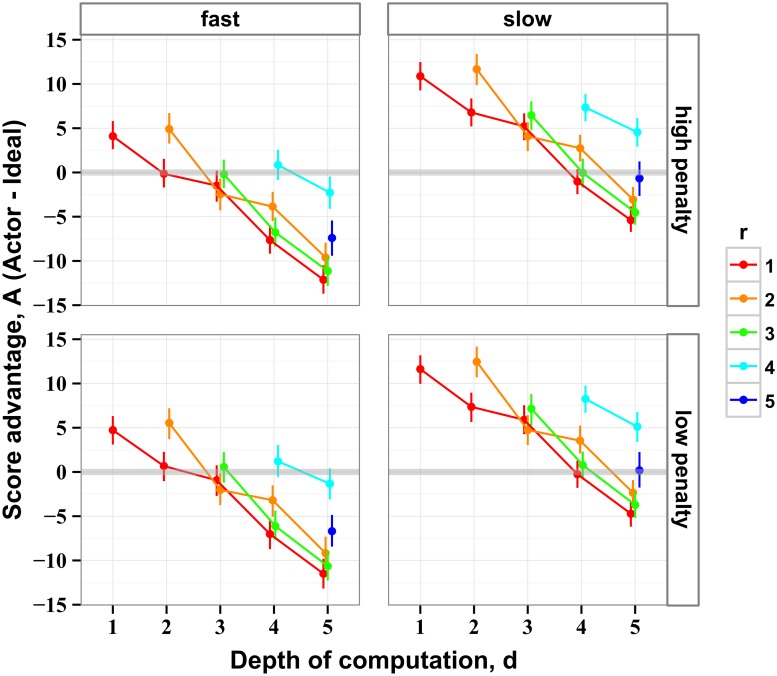
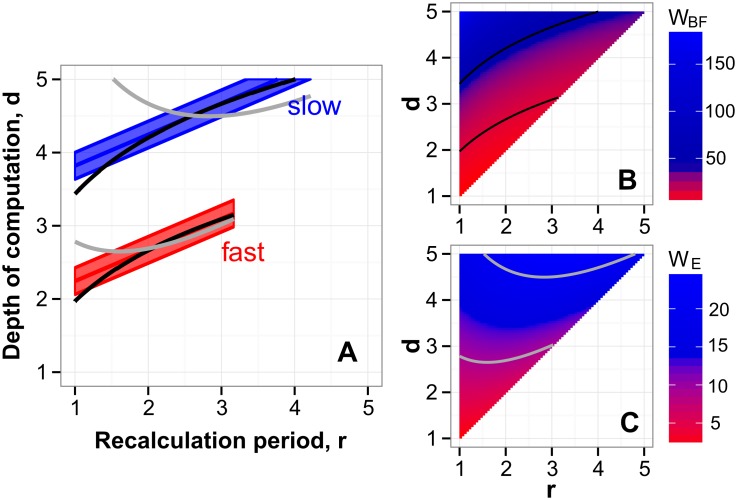
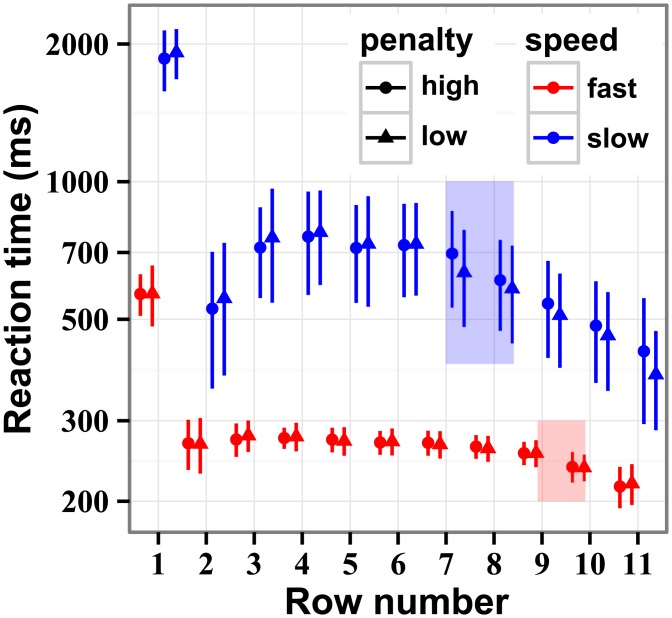
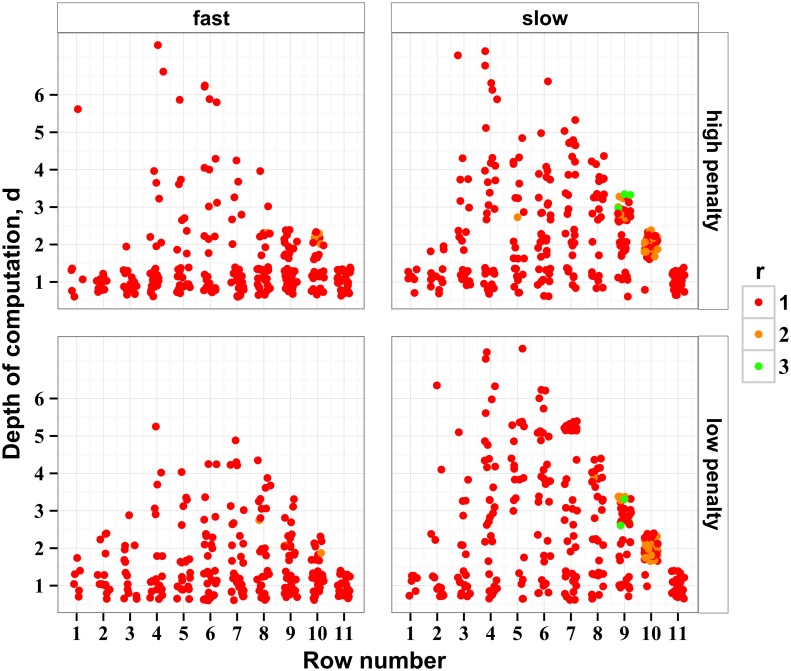
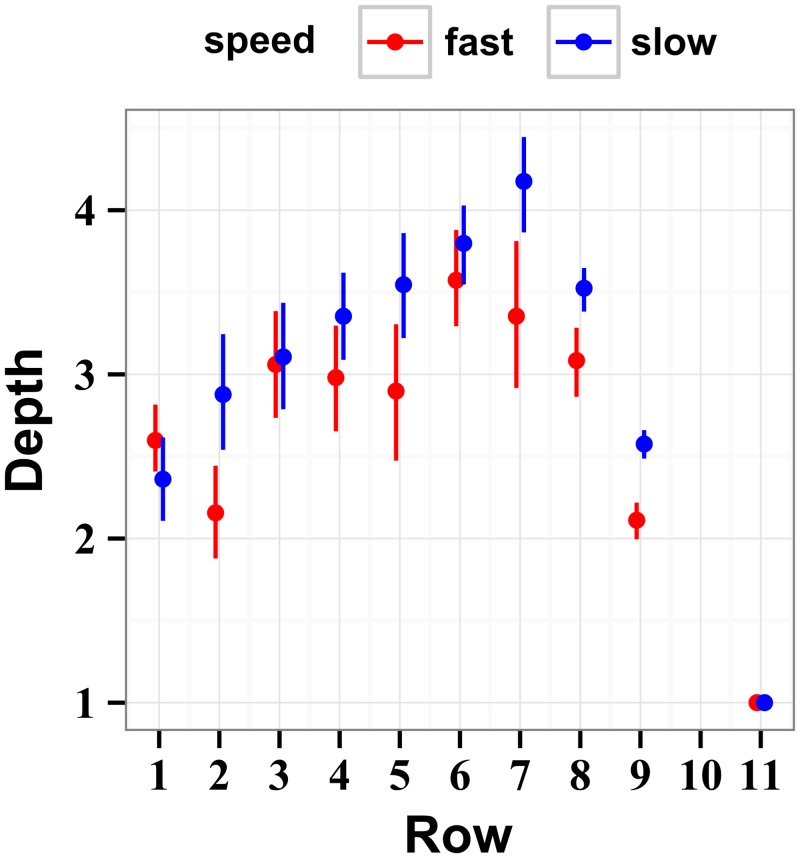
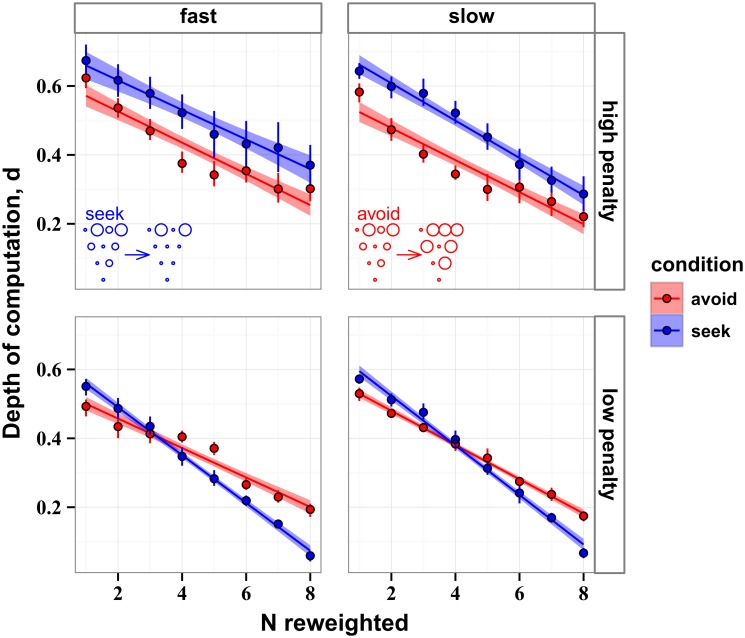
The future is uncertain because some forthcoming events are unpredictable and also because our ability to foresee the myriad consequences of our own actions is limited. Here we studied how humans select actions under such extrinsic and intrinsic uncertainty, in view of an exponentially expanding number of prospects on a branching multivalued visual stimulus. A triangular grid of disks of different sizes scrolled down a touchscreen at a variable speed. The larger disks represented larger rewards. The task was to maximize the cumulative reward by touching one disk at a time in a rapid sequence, forming an upward path across the grid, while every step along the path constrained the part of the grid accessible in the future. This task captured some of the complexity of natural behavior in the risky and dynamic world, where ongoing decisions alter the landscape of future rewards. By comparing human behavior with behavior of ideal actors, we identified the strategies used by humans in terms of how far into the future they looked (their "depth of computation") and how often they attempted to incorporate new information about the future rewards (their "recalculation period"). We found that, for a given task difficulty, humans traded off their depth of computation for the recalculation period. The form of this tradeoff was consistent with a complete, brute-force exploration of all possible paths up to a resource-limited finite depth. A step-by-step analysis of the human behavior revealed that participants took into account very fine distinctions between the future rewards and that they abstained from some simple heuristics in assessment of the alternative paths, such as seeking only the largest disks or avoiding the smaller disks. The participants preferred to reduce their depth of computation or increase the recalculation period rather than sacrifice the precision of computation.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures


References
-
- Caplin A, Dean M, Martin D (2011) Search and satisficing. The American Economic Review 101: 2899–2922. 10.1257/aer.101.7.2899 - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
