

Massive integration of diverse protein quality assessment methods to improve template based modeling in CASP11
- PMID: 26369671
- PMCID: PMC4792798
- DOI: 10.1002/prot.24924
Massive integration of diverse protein quality assessment methods to improve template based modeling in CASP11
Abstract
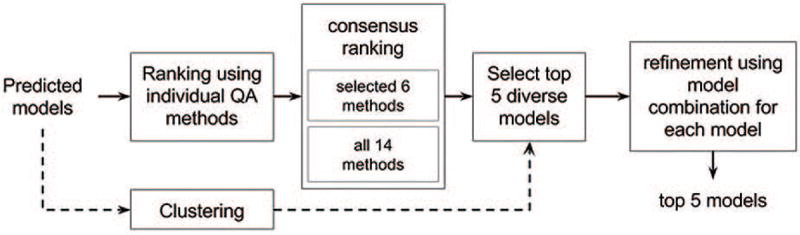
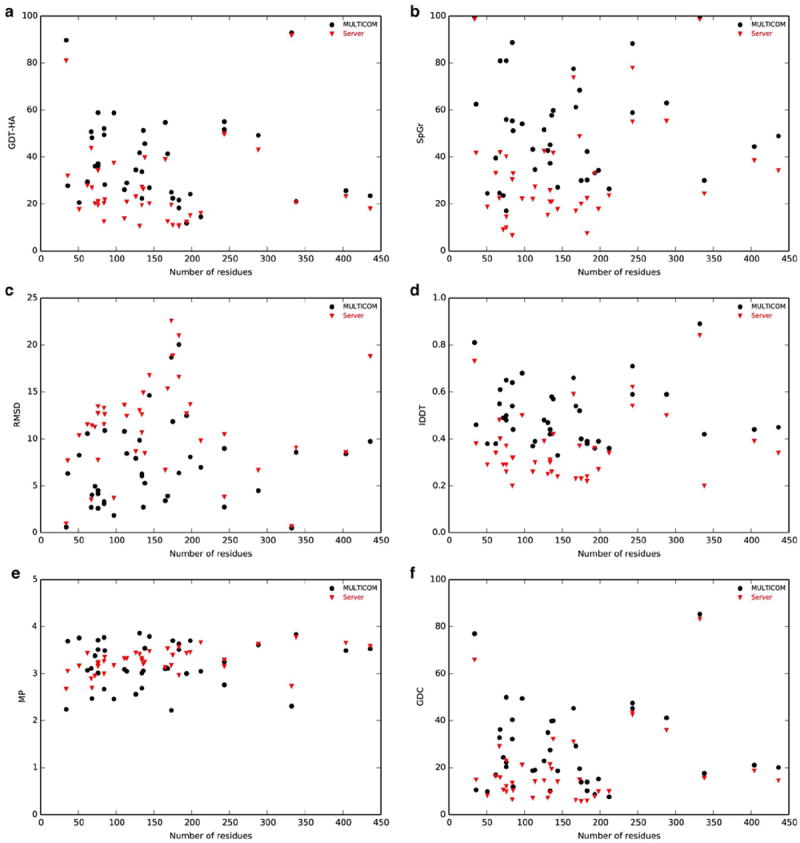
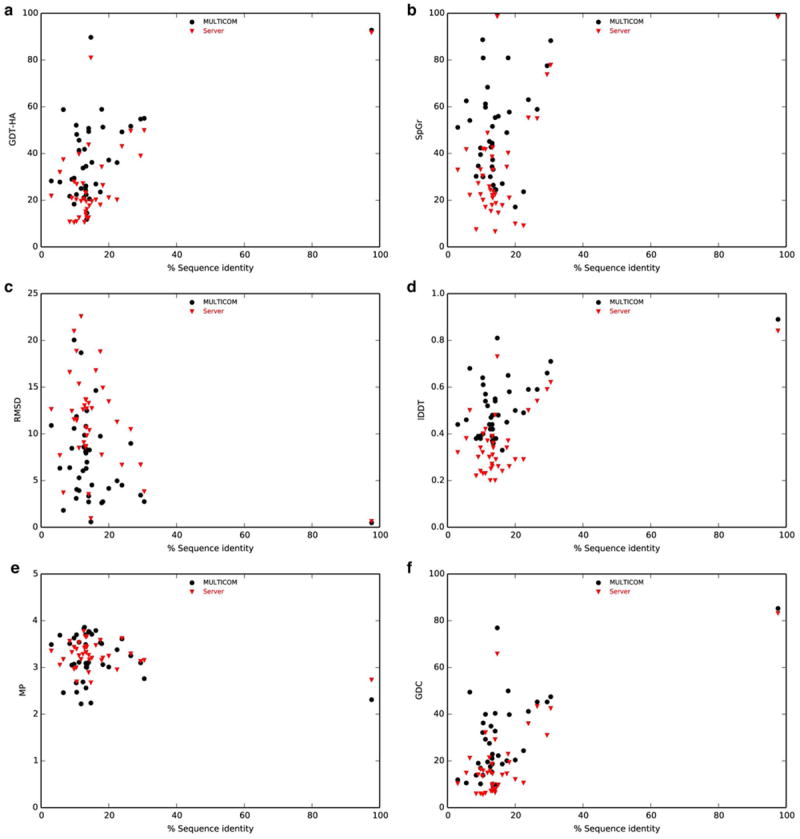
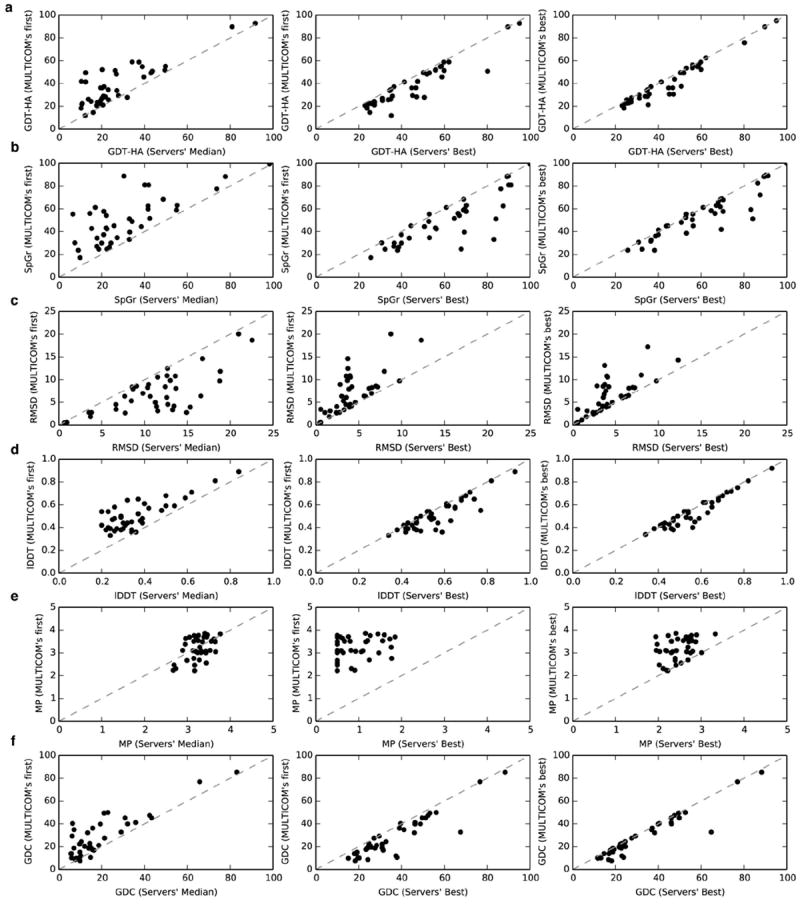
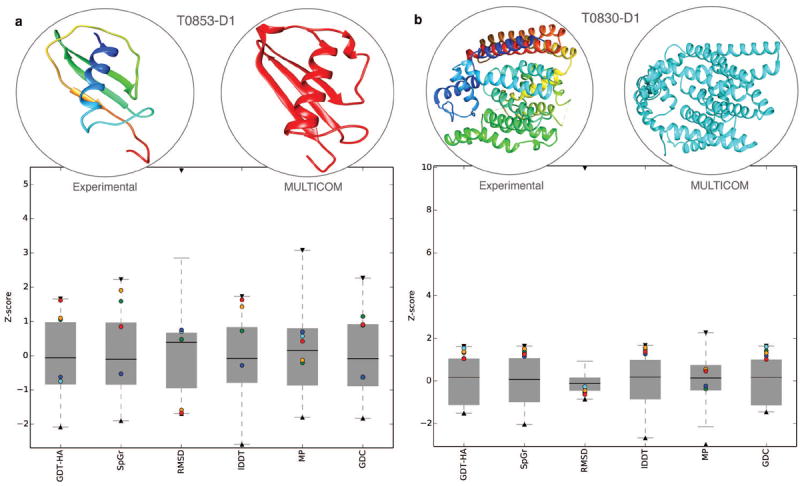
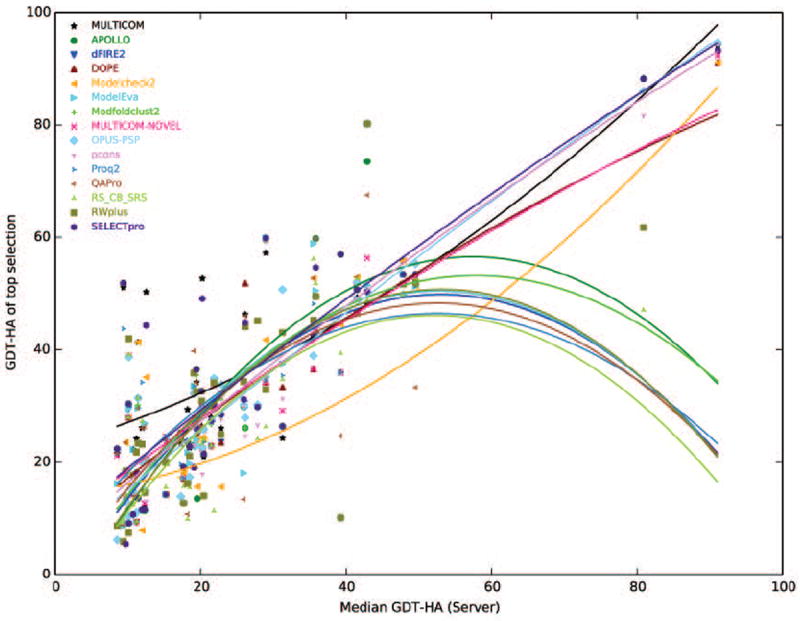
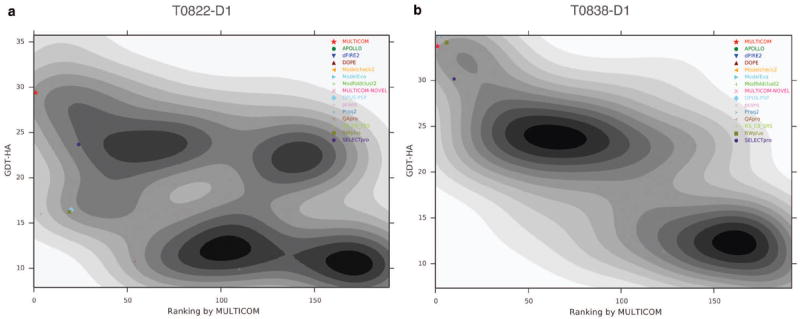
Model evaluation and selection is an important step and a big challenge in template-based protein structure prediction. Individual model quality assessment methods designed for recognizing some specific properties of protein structures often fail to consistently select good models from a model pool because of their limitations. Therefore, combining multiple complimentary quality assessment methods is useful for improving model ranking and consequently tertiary structure prediction. Here, we report the performance and analysis of our human tertiary structure predictor (MULTICOM) based on the massive integration of 14 diverse complementary quality assessment methods that was successfully benchmarked in the 11th Critical Assessment of Techniques of Protein Structure prediction (CASP11). The predictions of MULTICOM for 39 template-based domains were rigorously assessed by six scoring metrics covering global topology of Cα trace, local all-atom fitness, side chain quality, and physical reasonableness of the model. The results show that the massive integration of complementary, diverse single-model and multi-model quality assessment methods can effectively leverage the strength of single-model methods in distinguishing quality variation among similar good models and the advantage of multi-model quality assessment methods of identifying reasonable average-quality models. The overall excellent performance of the MULTICOM predictor demonstrates that integrating a large number of model quality assessment methods in conjunction with model clustering is a useful approach to improve the accuracy, diversity, and consequently robustness of template-based protein structure prediction. Proteins 2016; 84(Suppl 1):247-259. © 2015 Wiley Periodicals, Inc.
Keywords: CASP; integration; model quality assessment; protein structure prediction; template-based modeling.
© 2015 Wiley Periodicals, Inc.
Conflict of interest statement
The authors declare there is no conflict of interest.
Figures
References
-
- Eisenhaber F, Persson B, Argos P. Protein structure prediction: recognition of primary, secondary, and tertiary structural features from amino acid sequence. Critical reviews in biochemistry and molecular biology. 1995;30(1):1–94. - PubMed
-
- Rost B. Protein structure prediction in 1D, 2D, and 3D. The Encyclopaedia of Computational Chemistry. 1998;3:2242–2255.
-
- Floudas C. Computational methods in protein structure prediction. Biotechnology and bioengineering. 2007;97(2):207–213. - PubMed
-
- Shah M, Passovets S, Kim D, Ellrott K, Wang L, Vokler I, LoCascio P, Xu D, Xu Y. A computational pipeline for protein structure prediction and analysis at genome scale. Bioinformatics. 2003;19(15):1985. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
