

Simple Learned Weighted Sums of Inferior Temporal Neuronal Firing Rates Accurately Predict Human Core Object Recognition Performance
- PMID: 26424887
- PMCID: PMC4588611
- DOI: 10.1523/JNEUROSCI.5181-14.2015
Simple Learned Weighted Sums of Inferior Temporal Neuronal Firing Rates Accurately Predict Human Core Object Recognition Performance
Abstract
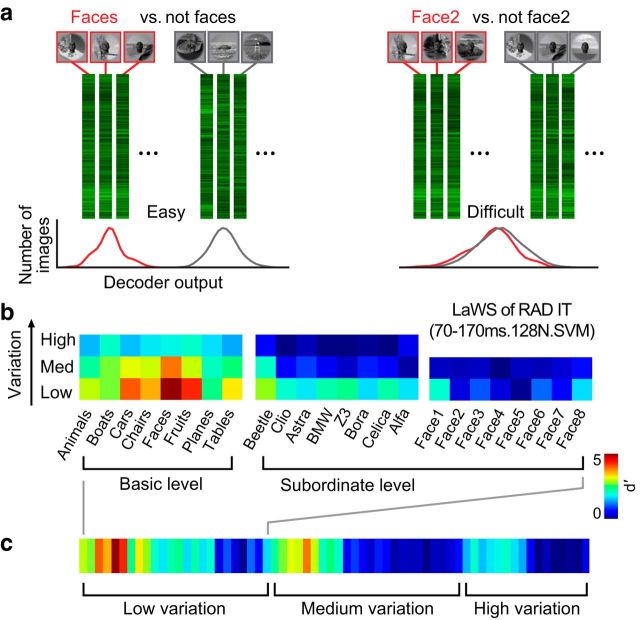
To go beyond qualitative models of the biological substrate of object recognition, we ask: can a single ventral stream neuronal linking hypothesis quantitatively account for core object recognition performance over a broad range of tasks? We measured human performance in 64 object recognition tests using thousands of challenging images that explore shape similarity and identity preserving object variation. We then used multielectrode arrays to measure neuronal population responses to those same images in visual areas V4 and inferior temporal (IT) cortex of monkeys and simulated V1 population responses. We tested leading candidate linking hypotheses and control hypotheses, each postulating how ventral stream neuronal responses underlie object recognition behavior. Specifically, for each hypothesis, we computed the predicted performance on the 64 tests and compared it with the measured pattern of human performance. All tested hypotheses based on low- and mid-level visually evoked activity (pixels, V1, and V4) were very poor predictors of the human behavioral pattern. However, simple learned weighted sums of distributed average IT firing rates exactly predicted the behavioral pattern. More elaborate linking hypotheses relying on IT trial-by-trial correlational structure, finer IT temporal codes, or ones that strictly respect the known spatial substructures of IT ("face patches") did not improve predictive power. Although these results do not reject those more elaborate hypotheses, they suggest a simple, sufficient quantitative model: each object recognition task is learned from the spatially distributed mean firing rates (100 ms) of ∼60,000 IT neurons and is executed as a simple weighted sum of those firing rates. Significance statement: We sought to go beyond qualitative models of visual object recognition and determine whether a single neuronal linking hypothesis can quantitatively account for core object recognition behavior. To achieve this, we designed a database of images for evaluating object recognition performance. We used multielectrode arrays to characterize hundreds of neurons in the visual ventral stream of nonhuman primates and measured the object recognition performance of >100 human observers. Remarkably, we found that simple learned weighted sums of firing rates of neurons in monkey inferior temporal (IT) cortex accurately predicted human performance. Although previous work led us to expect that IT would outperform V4, we were surprised by the quantitative precision with which simple IT-based linking hypotheses accounted for human behavior.
Keywords: IT cortex; V4; categorization; identification; invariance; object recognition.
Copyright © 2015 the authors 0270-6474/15/3513402-17$15.00/0.
Figures









References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources