

Flexible gating of contextual influences in natural vision
- PMID: 26436902
- PMCID: PMC4624479
- DOI: 10.1038/nn.4128
Flexible gating of contextual influences in natural vision
Abstract
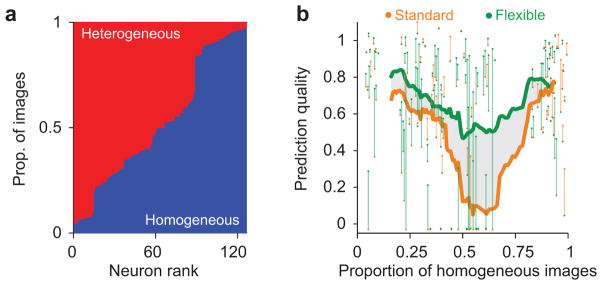
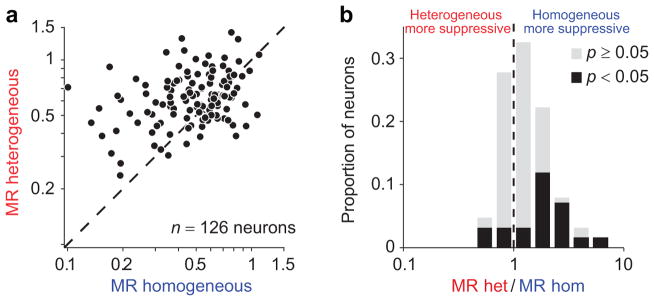
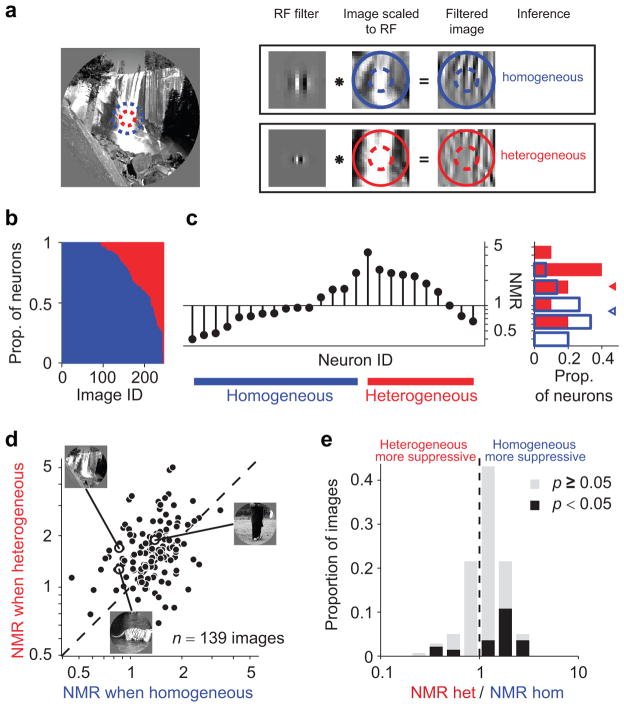
Identical sensory inputs can be perceived as markedly different when embedded in distinct contexts. Neural responses to simple stimuli are also modulated by context, but the contribution of this modulation to the processing of natural sensory input is unclear. We measured surround suppression, a quintessential contextual influence, in macaque primary visual cortex with natural images. We found that suppression strength varied substantially for different images. This variability was not well explained by existing descriptions of surround suppression, but it was predicted by Bayesian inference about statistical dependencies in images. In this framework, surround suppression was flexible: it was recruited when the image was inferred to contain redundancies and substantially reduced in strength otherwise. Thus, our results reveal a gating of a basic, widespread cortical computation by inference about the statistics of natural input.
Conflict of interest statement
Figures
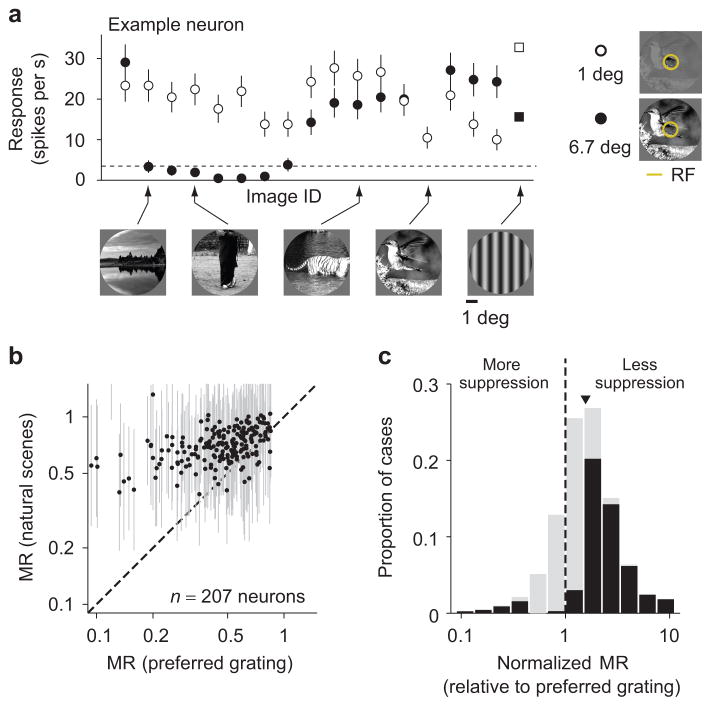
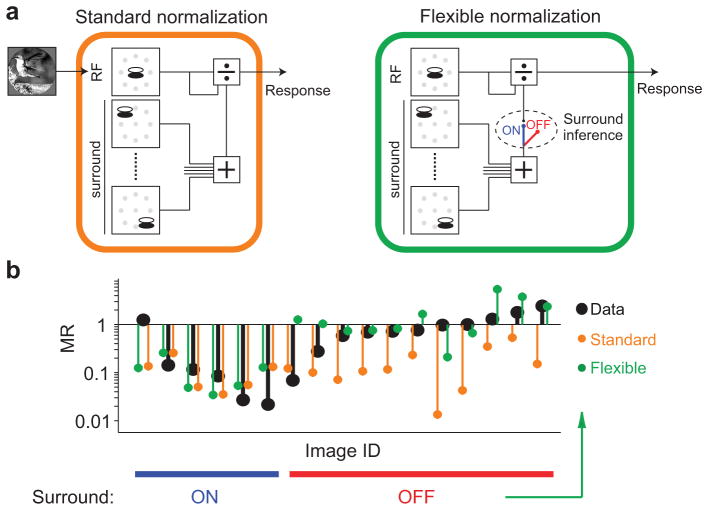
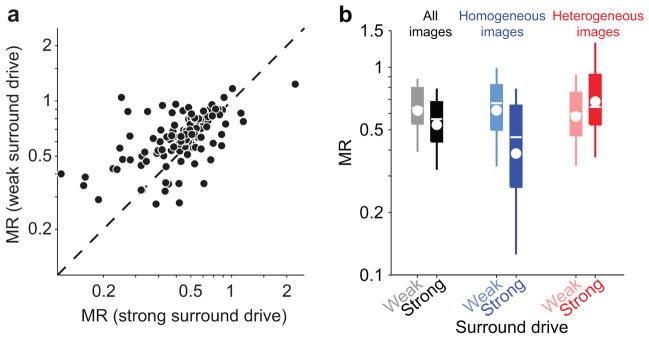
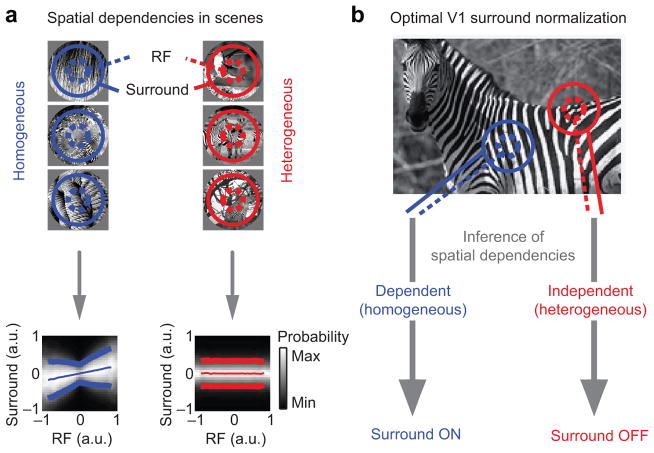
References
-
- Schwartz O, Hsu A, Dayan P. Space and time in visual context. Nat Rev Neurosci. 2007;8:522–535. - PubMed
-
- Kohn A. Visual Adaptation: Physiology, Mechanisms, and Functional Benefits. J Neurophysiol. 2007;97:3155–3164. - PubMed
-
- Itti L, Koch C. Computational modelling of visual attention. Nat Rev Neurosci. 2001;2:194–203. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
