

Genomes to natural products PRediction Informatics for Secondary Metabolomes (PRISM)
- PMID: 26442528
- PMCID: PMC4787774
- DOI: 10.1093/nar/gkv1012
Genomes to natural products PRediction Informatics for Secondary Metabolomes (PRISM)
Abstract
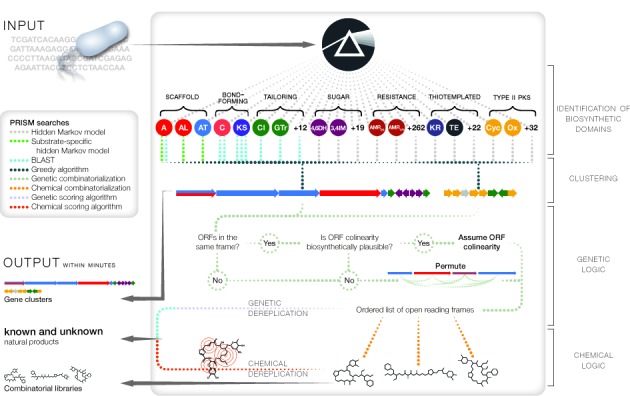
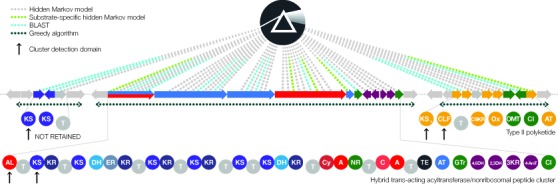
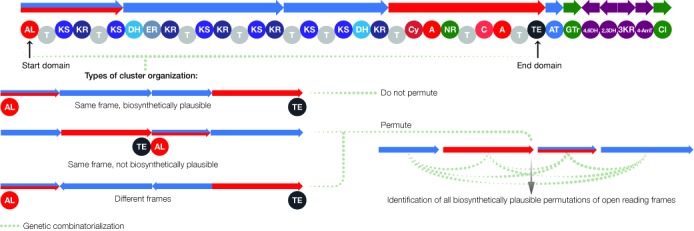
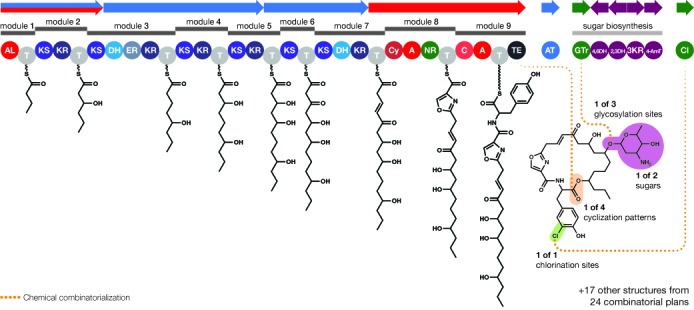
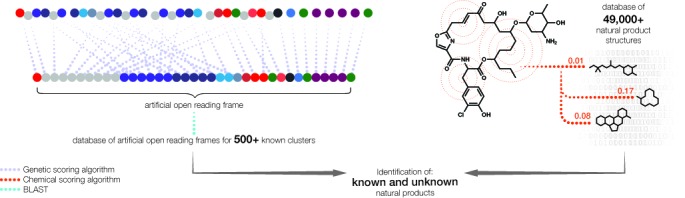
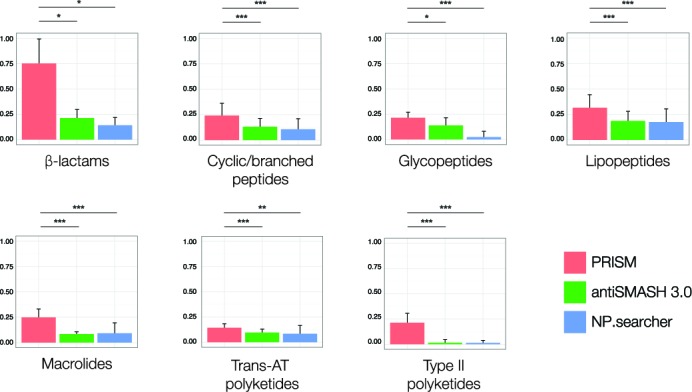
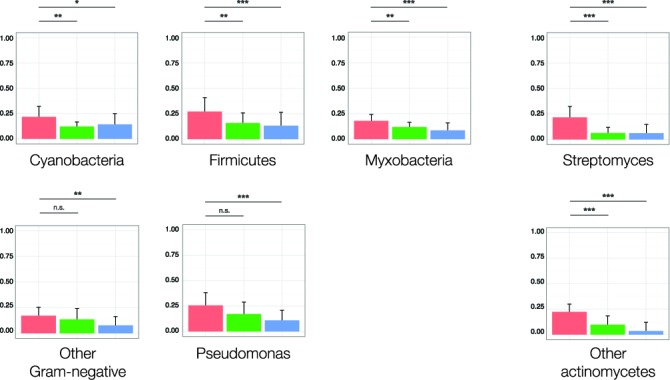
Microbial natural products are an invaluable source of evolved bioactive small molecules and pharmaceutical agents. Next-generation and metagenomic sequencing indicates untapped genomic potential, yet high rediscovery rates of known metabolites increasingly frustrate conventional natural product screening programs. New methods to connect biosynthetic gene clusters to novel chemical scaffolds are therefore critical to enable the targeted discovery of genetically encoded natural products. Here, we present PRISM, a computational resource for the identification of biosynthetic gene clusters, prediction of genetically encoded nonribosomal peptides and type I and II polyketides, and bio- and cheminformatic dereplication of known natural products. PRISM implements novel algorithms which render it uniquely capable of predicting type II polyketides, deoxygenated sugars, and starter units, making it a comprehensive genome-guided chemical structure prediction engine. A library of 57 tailoring reactions is leveraged for combinatorial scaffold library generation when multiple potential substrates are consistent with biosynthetic logic. We compare the accuracy of PRISM to existing genomic analysis platforms. PRISM is an open-source, user-friendly web application available at http://magarveylab.ca/prism/.
© The Author(s) 2015. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures

References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
