

Text as a Supplement to Speech in Young and Older Adults
- PMID: 26458131
- PMCID: PMC4767644
- DOI: 10.1097/AUD.0000000000000234
Text as a Supplement to Speech in Young and Older Adults
Abstract
Objective: The purpose of this experiment was to quantify the contribution of visual text to auditory speech recognition in background noise. Specifically, the authors tested the hypothesis that partially accurate visual text from an automatic speech recognizer could be used successfully to supplement speech understanding in difficult listening conditions in older adults, with normal or impaired hearing. The working hypotheses were based on what is known regarding audiovisual speech perception in the elderly from speechreading literature. We hypothesized that (1) combining auditory and visual text information will result in improved recognition accuracy compared with auditory or visual text information alone, (2) benefit from supplementing speech with visual text (auditory and visual enhancement) in young adults will be greater than that in older adults, and (3) individual differences in performance on perceptual measures would be associated with cognitive abilities.
Design: Fifteen young adults with normal hearing, 15 older adults with normal hearing, and 15 older adults with hearing loss participated in this study. All participants completed sentence recognition tasks in auditory-only, text-only, and combined auditory-text conditions. The auditory sentence stimuli were spectrally shaped to restore audibility for the older participants with impaired hearing. All participants also completed various cognitive measures, including measures of working memory, processing speed, verbal comprehension, perceptual and cognitive speed, processing efficiency, inhibition, and the ability to form wholes from parts. Group effects were examined for each of the perceptual and cognitive measures. Audiovisual benefit was calculated relative to performance on auditory- and visual-text only conditions. Finally, the relationship between perceptual measures and other independent measures were examined using principal-component factor analyses, followed by regression analyses.
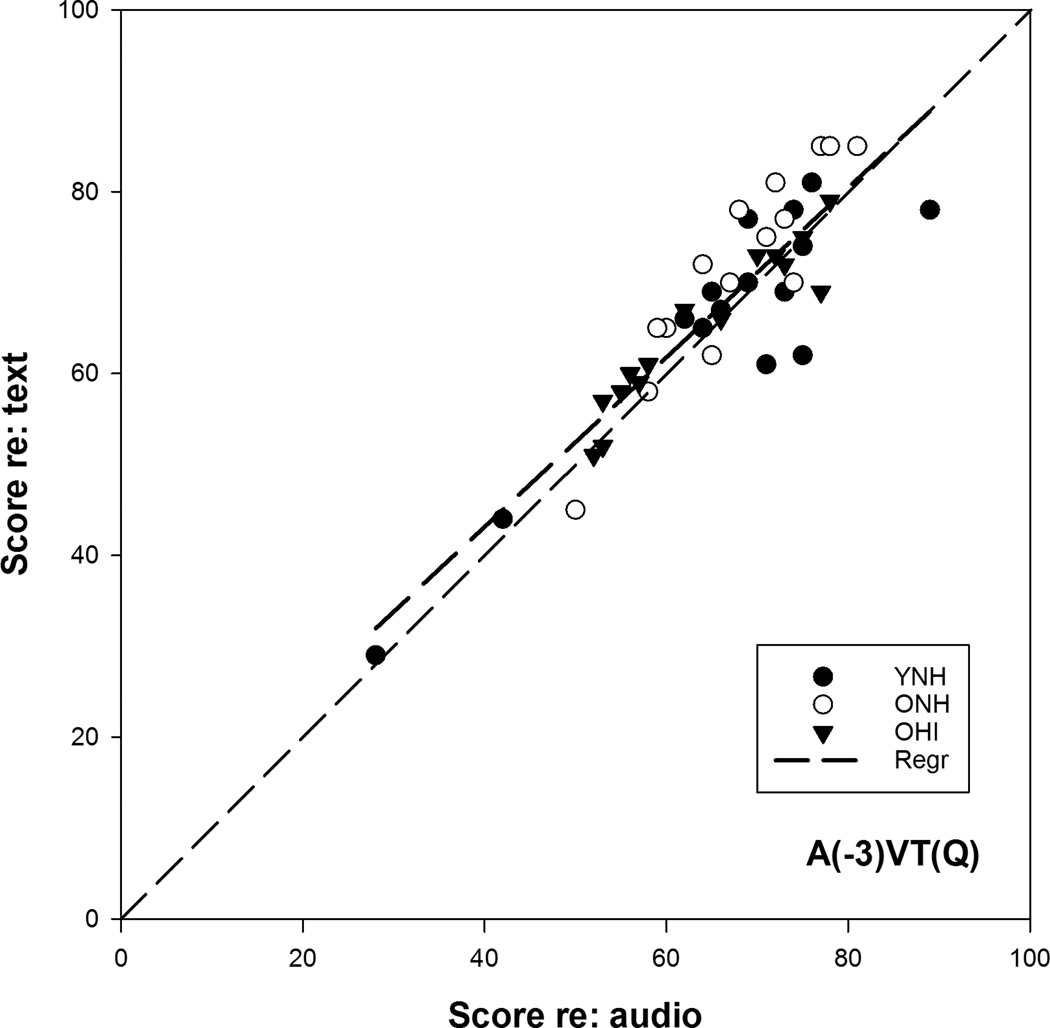
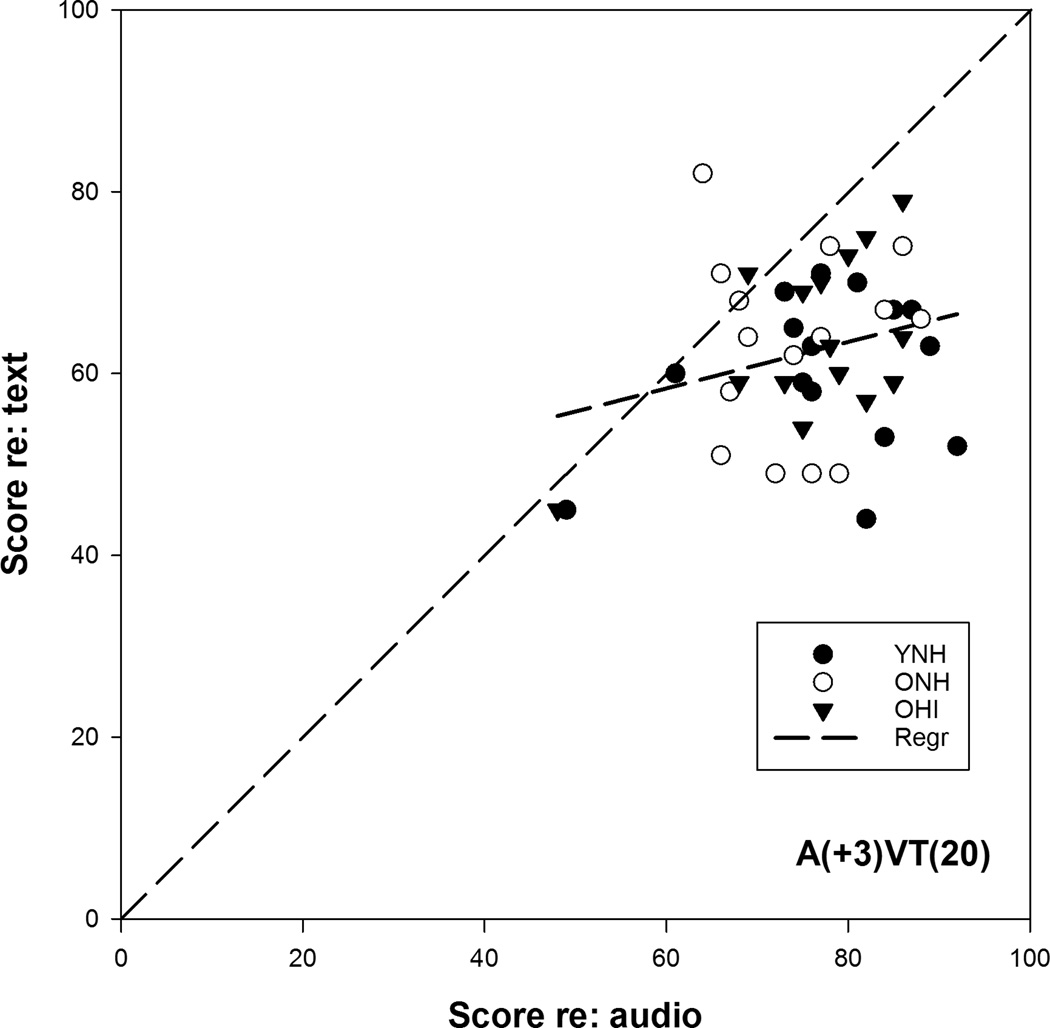
Results: Both young and older adults performed similarly on 9 out of 10 perceptual measures (auditory, visual, and combined measures). Combining degraded speech with partially correct text from an automatic speech recognizer improved the understanding of speech in both young and older adults, relative to both auditory- and text-only performance. In all subjects, cognition emerged as a key predictor for a general speech-text integration ability.
Conclusions: These results suggest that neither age nor hearing loss affected the ability of subjects to benefit from text when used to support speech, after ensuring audibility through spectral shaping. These results also suggest that the benefit obtained by supplementing auditory input with partially accurate text is modulated by cognitive ability, specifically lexical and verbal skills.
Figures








References
-
- Agrawal Y, Platz EA, Niparki JK. Prevalence of Hearing Loss and Differences by demographic characteristics among US Adults. Archives of Internal Medicine. 2008;168:1522–1530. - PubMed
-
- Alsius A, Navarra J, Campbell J, Soto-Faraco S. Audiovisual integration of speech falters under high attention demands. Current Biology. 2005;15:839–843. - PubMed
-
- American National Standards Institute. Maximum permissible ambient noise levels for audiometric test rooms. New York: ANSI; 1999. ANSI S3.1–1999.
-
- American National Standards Institute. Specifications for audiometers. New York: ANSI; 2010. ANSI S3.6–2010.
-
- Bain K, Basson SH, Wald M. Speech recognition in university classrooms: liberated learning project. Proceedings of the fifth international ACM conference on Assistive technologies; 2002. pp. 192–196. ACM.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
