

There Is a "U" in Clutter: Evidence for Robust Sparse Codes Underlying Clutter Tolerance in Human Vision
- PMID: 26490856
- PMCID: PMC4683683
- DOI: 10.1523/JNEUROSCI.1211-15.2015
There Is a "U" in Clutter: Evidence for Robust Sparse Codes Underlying Clutter Tolerance in Human Vision
Abstract
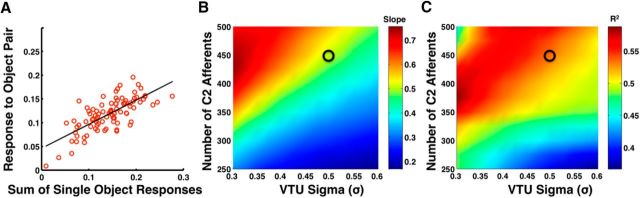
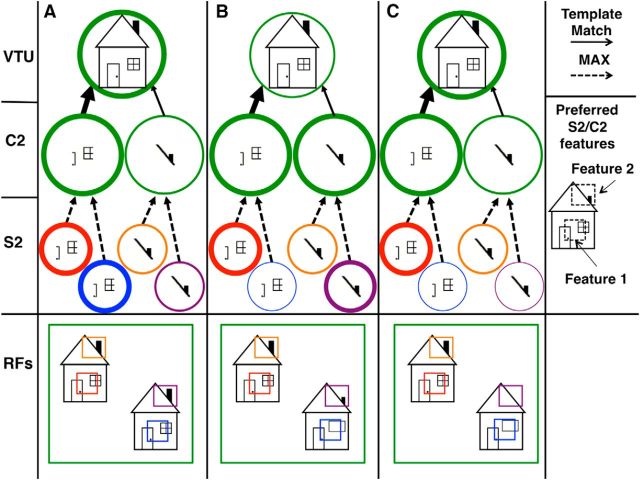
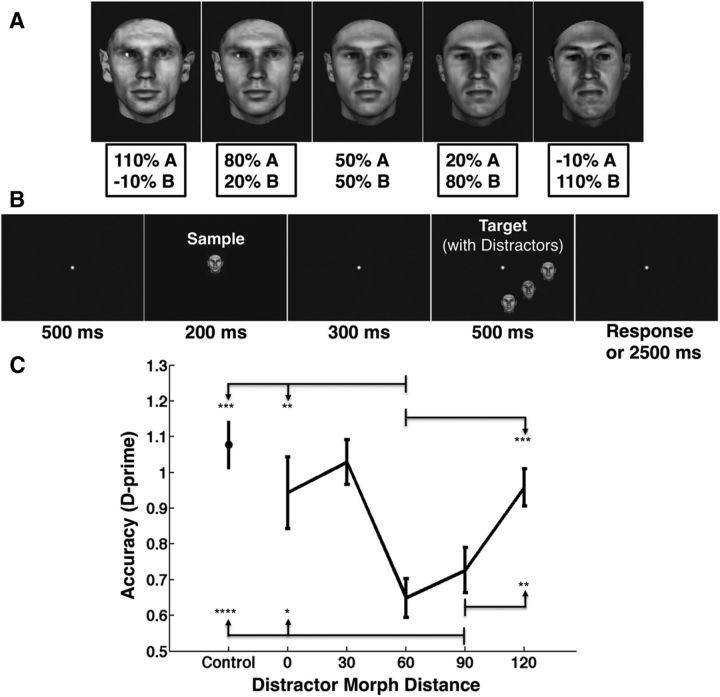
The ability to recognize objects in clutter is crucial for human vision, yet the underlying neural computations remain poorly understood. Previous single-unit electrophysiology recordings in inferotemporal cortex in monkeys and fMRI studies of object-selective cortex in humans have shown that the responses to pairs of objects can sometimes be well described as a weighted average of the responses to the constituent objects. Yet, from a computational standpoint, it is not clear how the challenge of object recognition in clutter can be solved if downstream areas must disentangle the identity of an unknown number of individual objects from the confounded average neuronal responses. An alternative idea is that recognition is based on a subpopulation of neurons that are robust to clutter, i.e., that do not show response averaging, but rather robust object-selective responses in the presence of clutter. Here we show that simulations using the HMAX model of object recognition in cortex can fit the aforementioned single-unit and fMRI data, showing that the averaging-like responses can be understood as the result of responses of object-selective neurons to suboptimal stimuli. Moreover, the model shows how object recognition can be achieved by a sparse readout of neurons whose selectivity is robust to clutter. Finally, the model provides a novel prediction about human object recognition performance, namely, that target recognition ability should show a U-shaped dependency on the similarity of simultaneously presented clutter objects. This prediction is confirmed experimentally, supporting a simple, unifying model of how the brain performs object recognition in clutter.
Significance statement: The neural mechanisms underlying object recognition in cluttered scenes (i.e., containing more than one object) remain poorly understood. Studies have suggested that neural responses to multiple objects correspond to an average of the responses to the constituent objects. Yet, it is unclear how the identities of an unknown number of objects could be disentangled from a confounded average response. Here, we use a popular computational biological vision model to show that averaging-like responses can result from responses of clutter-tolerant neurons to suboptimal stimuli. The model also provides a novel prediction, that human detection ability should show a U-shaped dependency on target-clutter similarity, which is confirmed experimentally, supporting a simple, unifying account of how the brain performs object recognition in clutter.
Keywords: HMAX; clutter; sparse coding; vision.
Copyright © 2015 the authors 0270-6474/15/3514148-12$15.00/0.
Figures



Similar articles
-
Clutter modulates the representation of target objects in the human occipitotemporal cortex.J Cogn Neurosci. 2014 Mar;26(3):490-500. doi: 10.1162/jocn_a_00505. Epub 2013 Oct 21. J Cogn Neurosci. 2014. PMID: 24144245
-
What response properties do individual neurons need to underlie position and clutter "invariant" object recognition?J Neurophysiol. 2009 Jul;102(1):360-76. doi: 10.1152/jn.90745.2008. Epub 2009 May 13. J Neurophysiol. 2009. PMID: 19439676 Free PMC article.
-
Category selectivity in the ventral visual pathway confers robustness to clutter and diverted attention.Curr Biol. 2007 Dec 4;17(23):2067-72. doi: 10.1016/j.cub.2007.10.043. Epub 2007 Nov 8. Curr Biol. 2007. PMID: 17997310 Free PMC article.
-
Visual Object Recognition: Do We (Finally) Know More Now Than We Did?Annu Rev Vis Sci. 2016 Oct 14;2:377-396. doi: 10.1146/annurev-vision-111815-114621. Epub 2016 Aug 3. Annu Rev Vis Sci. 2016. PMID: 28532357 Review.
-
Learning and neural plasticity in visual object recognition.Curr Opin Neurobiol. 2006 Apr;16(2):152-8. doi: 10.1016/j.conb.2006.03.012. Epub 2006 Mar 24. Curr Opin Neurobiol. 2006. PMID: 16563736 Review.
Cited by
-
Nonlinear Processing of Shape Information in Rat Lateral Extrastriate Cortex.J Neurosci. 2019 Feb 27;39(9):1649-1670. doi: 10.1523/JNEUROSCI.1938-18.2018. Epub 2019 Jan 7. J Neurosci. 2019. PMID: 30617210 Free PMC article.
-
How the mind sees the world.Nat Hum Behav. 2020 Nov;4(11):1100-1101. doi: 10.1038/s41562-020-00973-x. Nat Hum Behav. 2020. PMID: 33046863 No abstract available.
-
Representation of multiple objects in macaque category-selective areas.Nat Commun. 2018 May 2;9(1):1774. doi: 10.1038/s41467-018-04126-7. Nat Commun. 2018. PMID: 29720645 Free PMC article.
-
Can (should) theories of crowding be unified?J Vis. 2016 Dec 1;16(15):10. doi: 10.1167/16.15.10. J Vis. 2016. PMID: 27936273 Free PMC article.
-
On the ability of standard and brain-constrained deep neural networks to support cognitive superposition: a position paper.Cogn Neurodyn. 2024 Dec;18(6):3383-3400. doi: 10.1007/s11571-023-10061-1. Epub 2024 Feb 4. Cogn Neurodyn. 2024. PMID: 39712129 Free PMC article.
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources