

Convalescing Cluster Configuration Using a Superlative Framework
- PMID: 26543895
- PMCID: PMC4620246
- DOI: 10.1155/2015/180749
Convalescing Cluster Configuration Using a Superlative Framework
Abstract
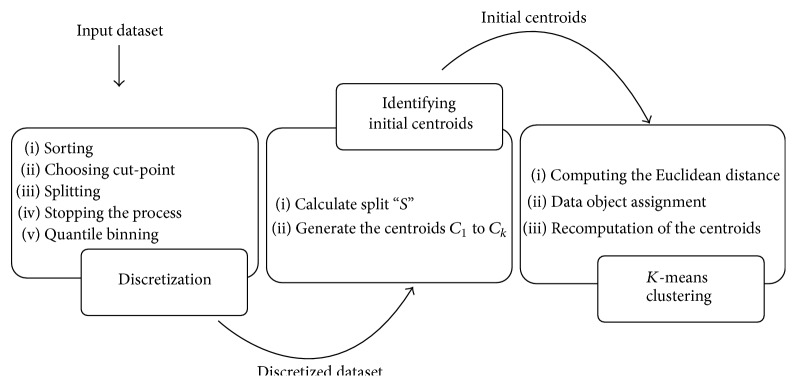
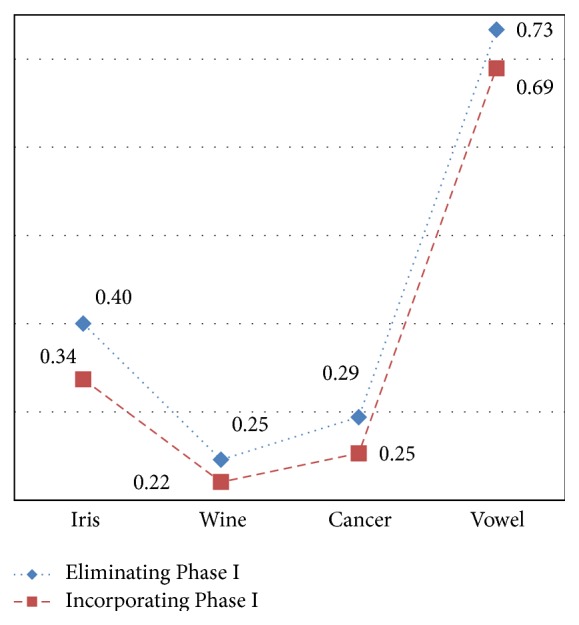
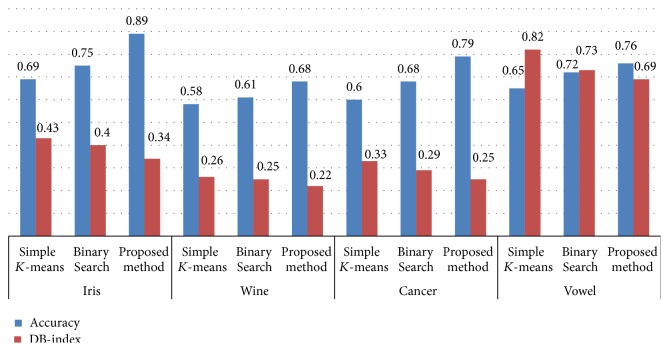
Competent data mining methods are vital to discover knowledge from databases which are built as a result of enormous growth of data. Various techniques of data mining are applied to obtain knowledge from these databases. Data clustering is one such descriptive data mining technique which guides in partitioning data objects into disjoint segments. K-means algorithm is a versatile algorithm among the various approaches used in data clustering. The algorithm and its diverse adaptation methods suffer certain problems in their performance. To overcome these issues a superlative algorithm has been proposed in this paper to perform data clustering. The specific feature of the proposed algorithm is discretizing the dataset, thereby improving the accuracy of clustering, and also adopting the binary search initialization method to generate cluster centroids. The generated centroids are fed as input to K-means approach which iteratively segments the data objects into respective clusters. The clustered results are measured for accuracy and validity. Experiments conducted by testing the approach on datasets from the UC Irvine Machine Learning Repository evidently show that the accuracy and validity measure is higher than the other two approaches, namely, simple K-means and Binary Search method. Thus, the proposed approach proves that discretization process will improve the efficacy of descriptive data mining tasks.
Figures






References
-
- Pujari A. K. Data Mining Techniques. Hyderabad, India: University Press; 2001.
-
- Tan P., Steinbach M., Kumar V. Introduction to Data Mining. Pearson Addison-Wesley; 2006.
-
- Larose D. T. Discovering Knowledge in Data—An Introduction to Data Mining. New York, NY, USA: John Wiley & Sons; 2005.
-
- Hegland M. Data Mining—Challenges, Models, Methods and Algorithms. ANU Data Mining Group; 2003. (Draft).
-
- Freitas A. A. Data Mining and Knowledge Discovery with Evolutionary Algorithms. Springer; 2002.
LinkOut - more resources
Full Text Sources
Other Literature Sources
