

Effect of trial-to-trial variability on optimal event-related fMRI design: Implications for Beta-series correlation and multi-voxel pattern analysis
- PMID: 26549299
- PMCID: PMC4692520
- DOI: 10.1016/j.neuroimage.2015.11.009
Effect of trial-to-trial variability on optimal event-related fMRI design: Implications for Beta-series correlation and multi-voxel pattern analysis
Abstract
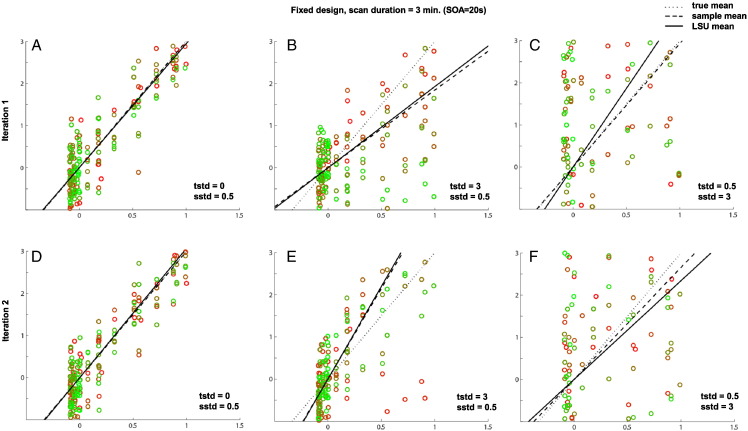
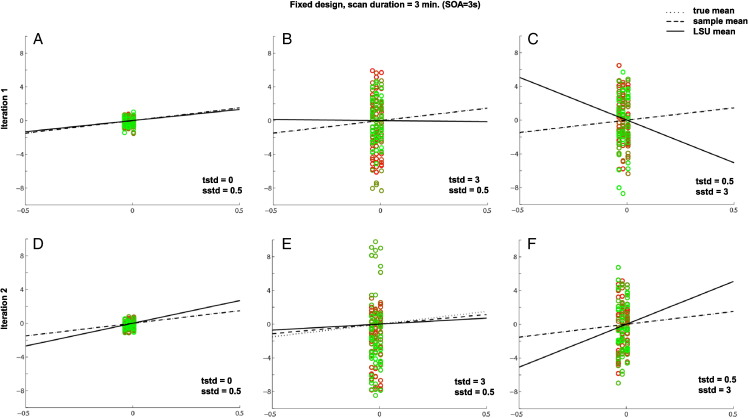
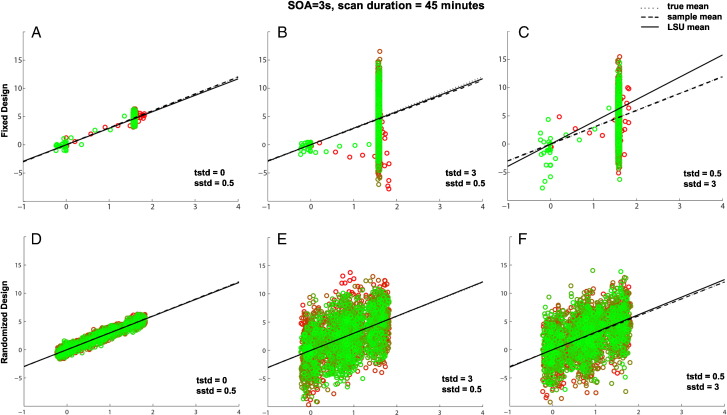
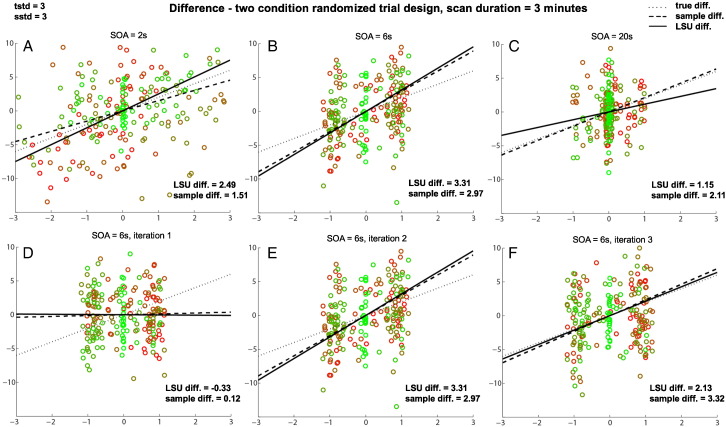
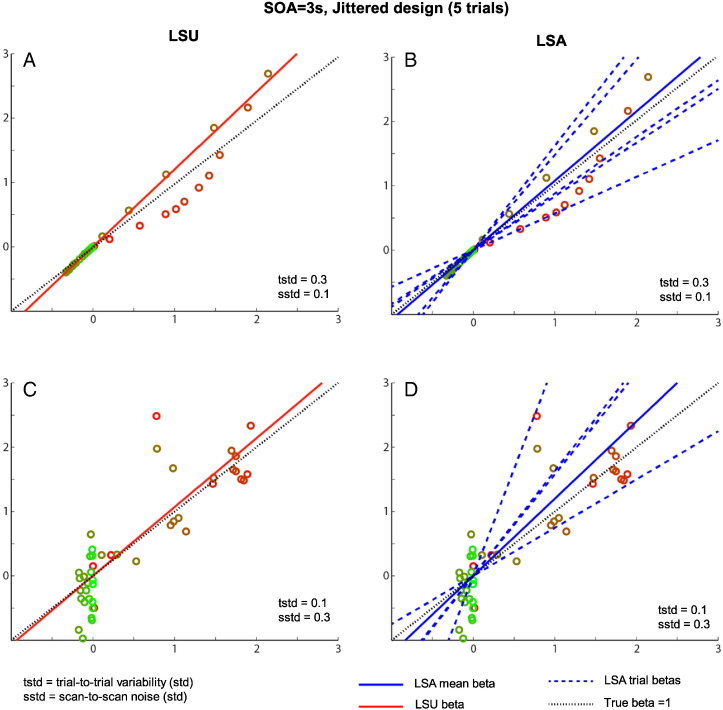
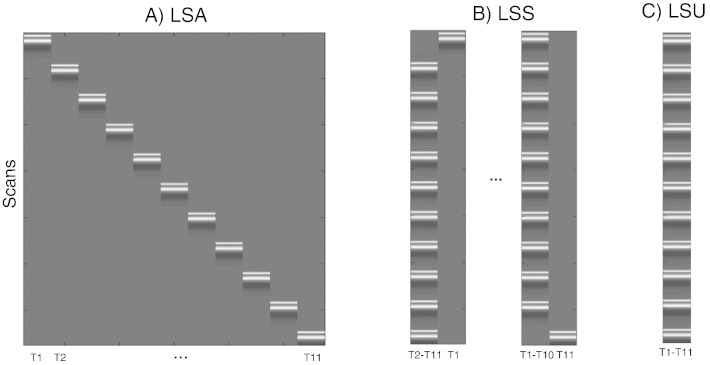
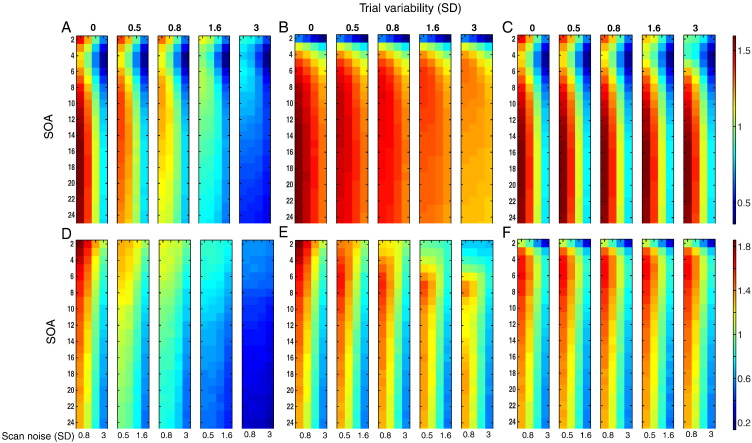
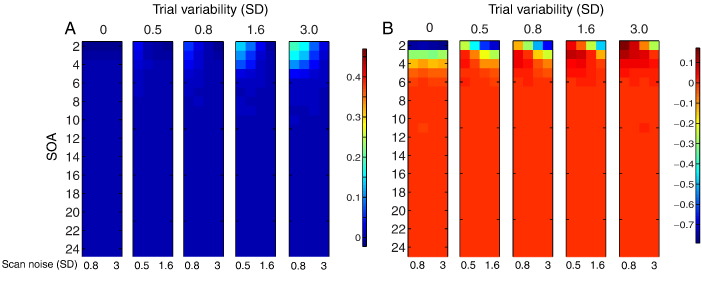
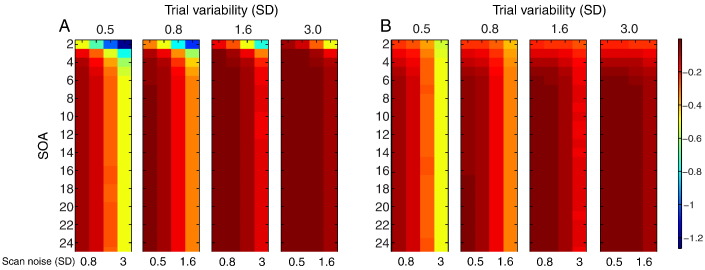
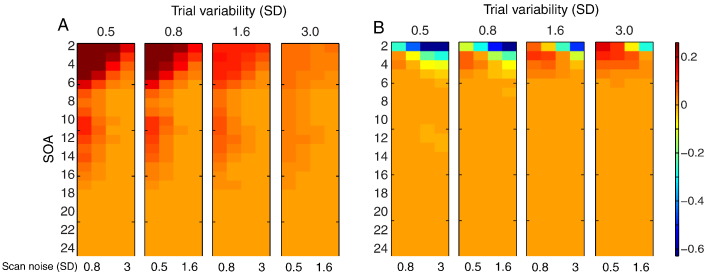
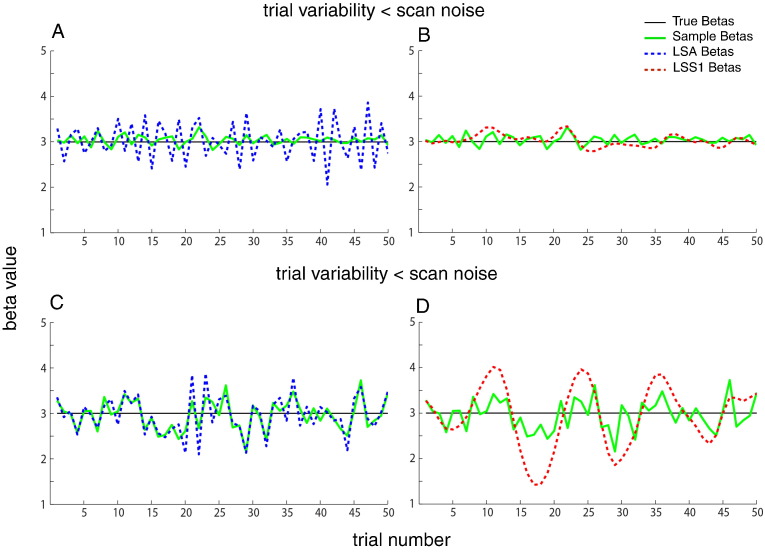
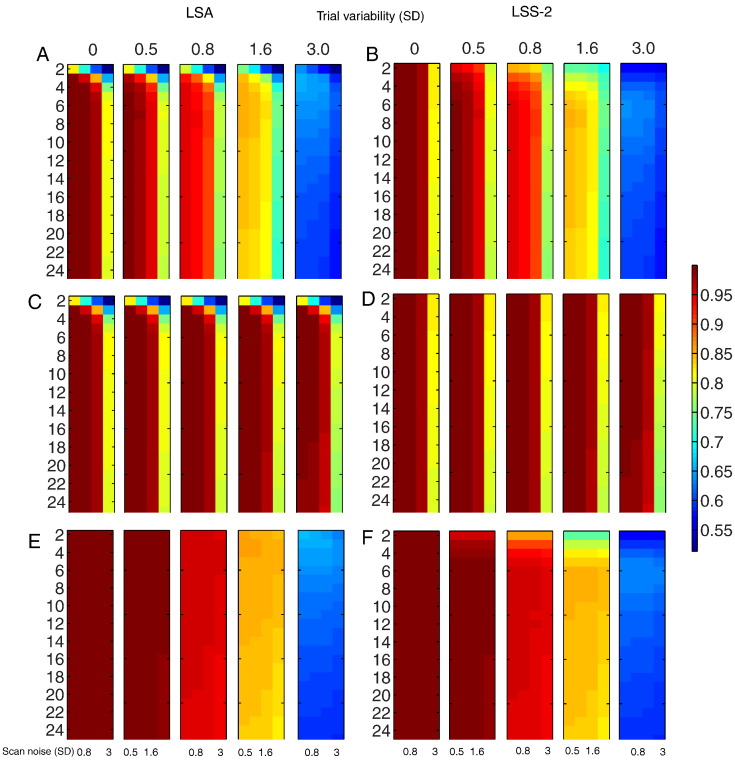
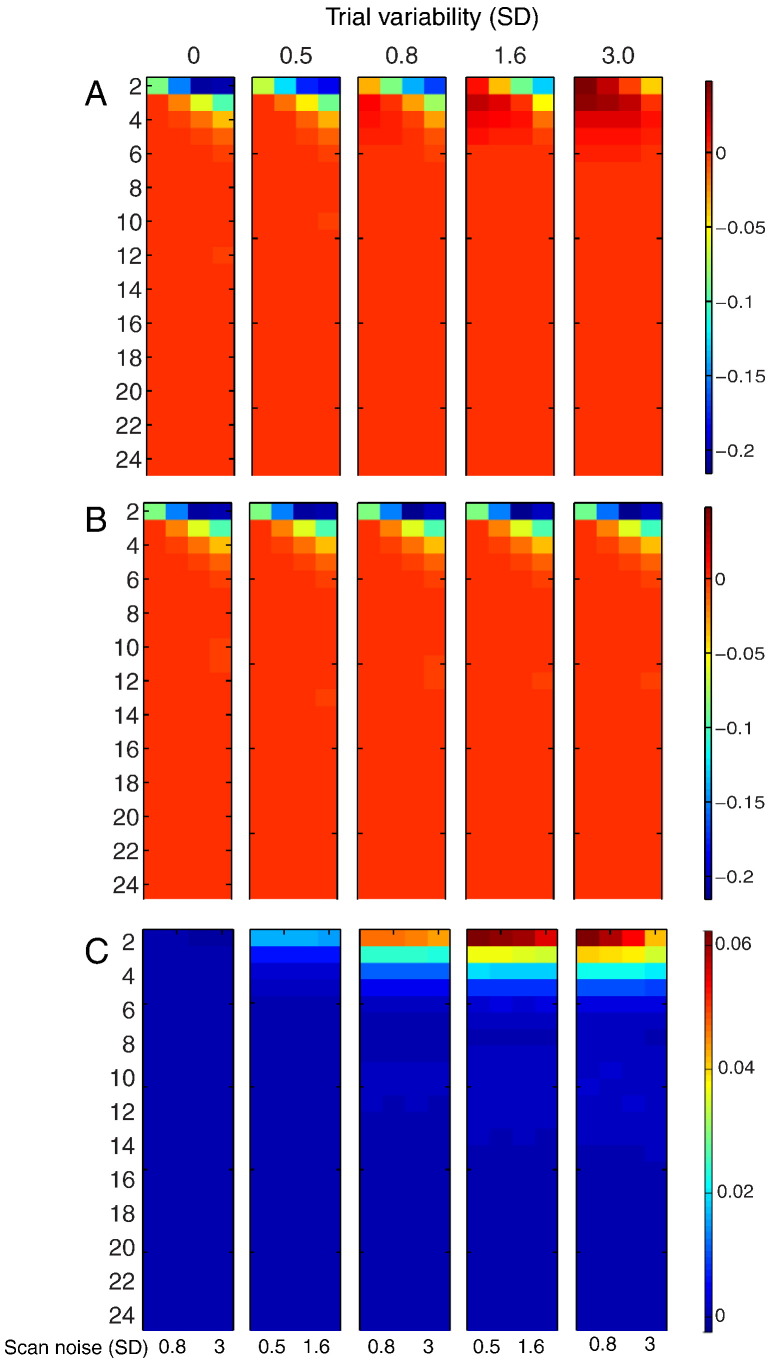
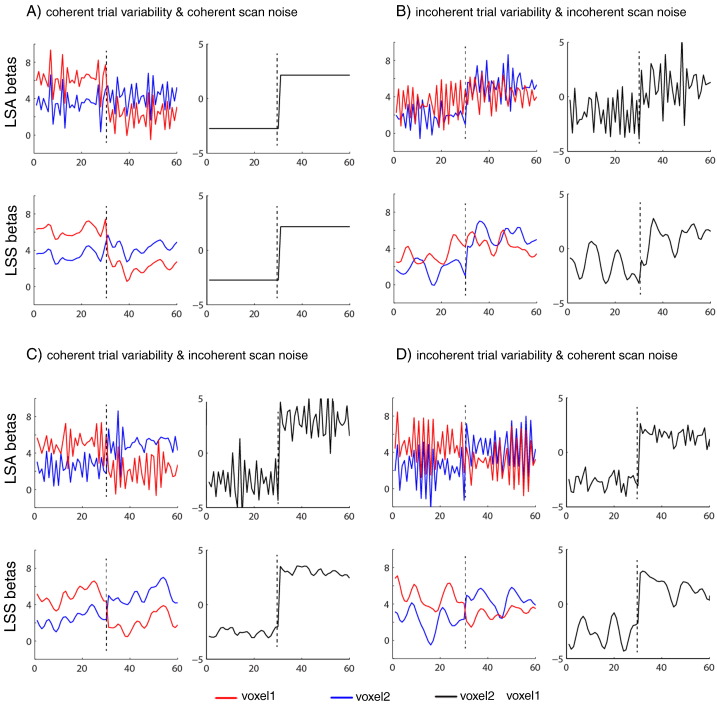
Functional magnetic resonance imaging (fMRI) studies typically employ rapid, event-related designs for behavioral reasons and for reasons associated with statistical efficiency. Efficiency is calculated from the precision of the parameters (Betas) estimated from a General Linear Model (GLM) in which trial onsets are convolved with a Hemodynamic Response Function (HRF). However, previous calculations of efficiency have ignored likely variability in the neural response from trial to trial, for example due to attentional fluctuations, or different stimuli across trials. Here we compare three GLMs in their efficiency for estimating average and individual Betas across trials as a function of trial variability, scan noise and Stimulus Onset Asynchrony (SOA): "Least Squares All" (LSA), "Least Squares Separate" (LSS) and "Least Squares Unitary" (LSU). Estimation of responses to individual trials in particular is important for both functional connectivity using "Beta-series correlation" and "multi-voxel pattern analysis" (MVPA). Our simulations show that the ratio of trial-to-trial variability to scan noise impacts both the optimal SOA and optimal GLM, especially for short SOAs<5s: LSA is better when this ratio is high, whereas LSS and LSU are better when the ratio is low. For MVPA, the consistency across voxels of trial variability and of scan noise is also critical. These findings not only have important implications for design of experiments using Beta-series regression and MVPA, but also statistical parametric mapping studies that seek only efficient estimation of the mean response across trials.
Keywords: Bold variability; General Linear Model; Least squares all; Least squares separate; MVPA; Trial based correlations; fMRI design.
Copyright © 2015. Published by Elsevier Inc.
Figures
References
-
- Birn R.M. The behavioral significance of spontaneous fluctuations in brain activity. Neuron. 2007;56:8–9. - PubMed
-
- Brignell C.J., Browne W.J., Dryden I.L., Francis S.T. Mixed Effect Modelling of Single Trial Variability in Ultra-high Field fMRI. 2015. ArXiv preprint, ArXiv: 1501.05763
-
- Chawla D., Rees G., Friston K.J. The physiological basis of attentional modulation in extrastriate visual areas. Nat. Neurosci. 1999;2:671–676. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
