

Choosing experiments to accelerate collective discovery
- PMID: 26554009
- PMCID: PMC4664375
- DOI: 10.1073/pnas.1509757112
Choosing experiments to accelerate collective discovery
Abstract
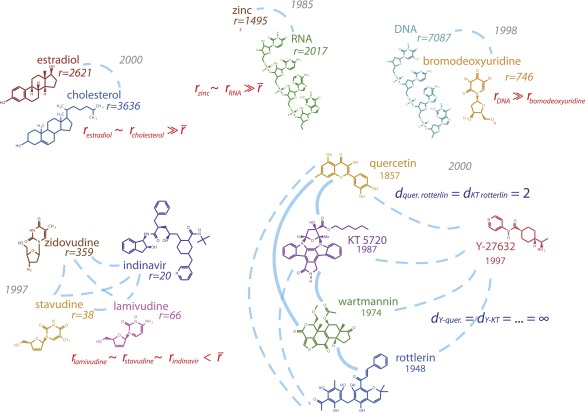
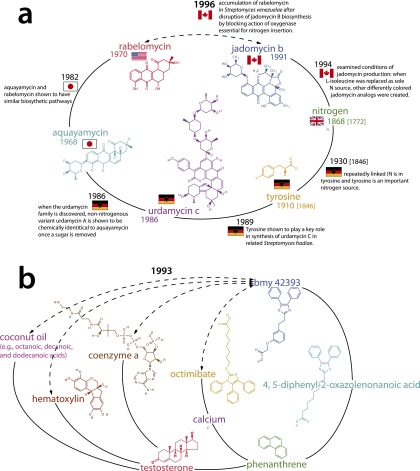
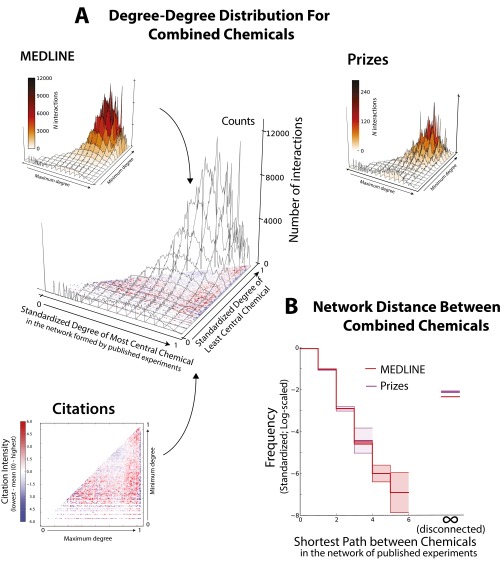
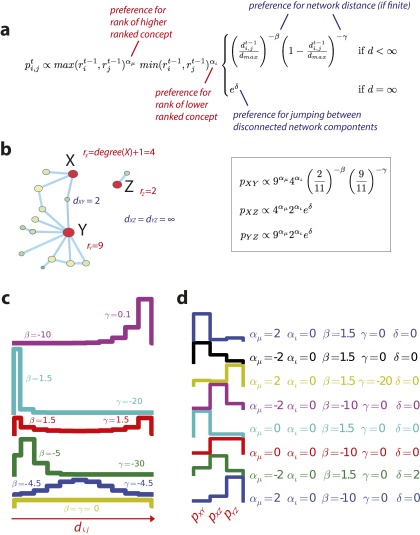
A scientist's choice of research problem affects his or her personal career trajectory. Scientists' combined choices affect the direction and efficiency of scientific discovery as a whole. In this paper, we infer preferences that shape problem selection from patterns of published findings and then quantify their efficiency. We represent research problems as links between scientific entities in a knowledge network. We then build a generative model of discovery informed by qualitative research on scientific problem selection. We map salient features from this literature to key network properties: an entity's importance corresponds to its degree centrality, and a problem's difficulty corresponds to the network distance it spans. Drawing on millions of papers and patents published over 30 years, we use this model to infer the typical research strategy used to explore chemical relationships in biomedicine. This strategy generates conservative research choices focused on building up knowledge around important molecules. These choices become more conservative over time. The observed strategy is efficient for initial exploration of the network and supports scientific careers that require steady output, but is inefficient for science as a whole. Through supercomputer experiments on a sample of the network, we study thousands of alternatives and identify strategies much more efficient at exploring mature knowledge networks. We find that increased risk-taking and the publication of experimental failures would substantially improve the speed of discovery. We consider institutional shifts in grant making, evaluation, and publication that would help realize these efficiencies.
Keywords: complex networks; computational biology; innovation; science of science; sociology of science.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
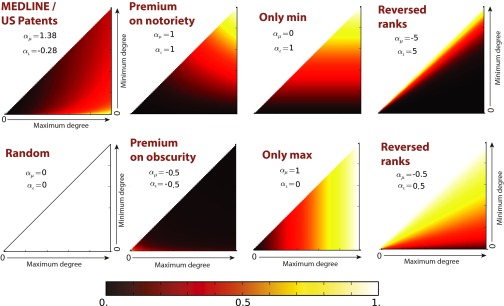
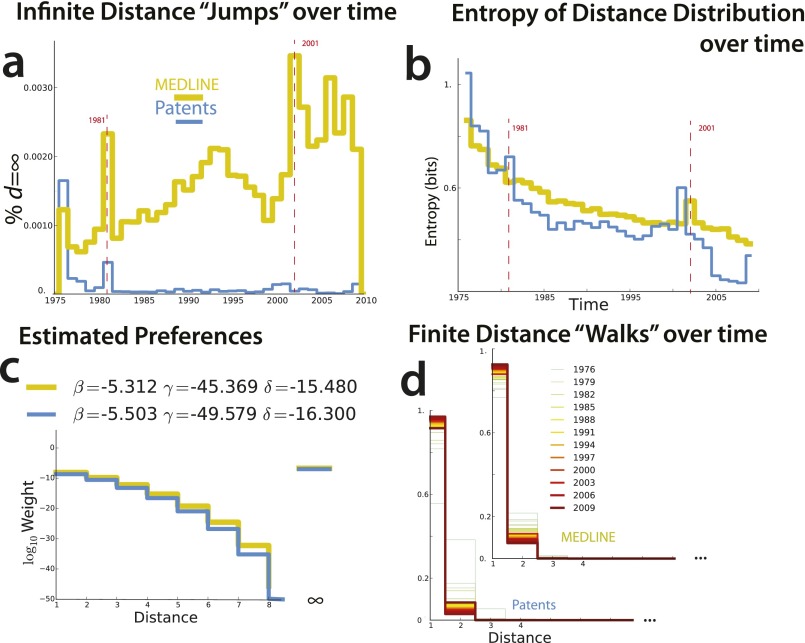

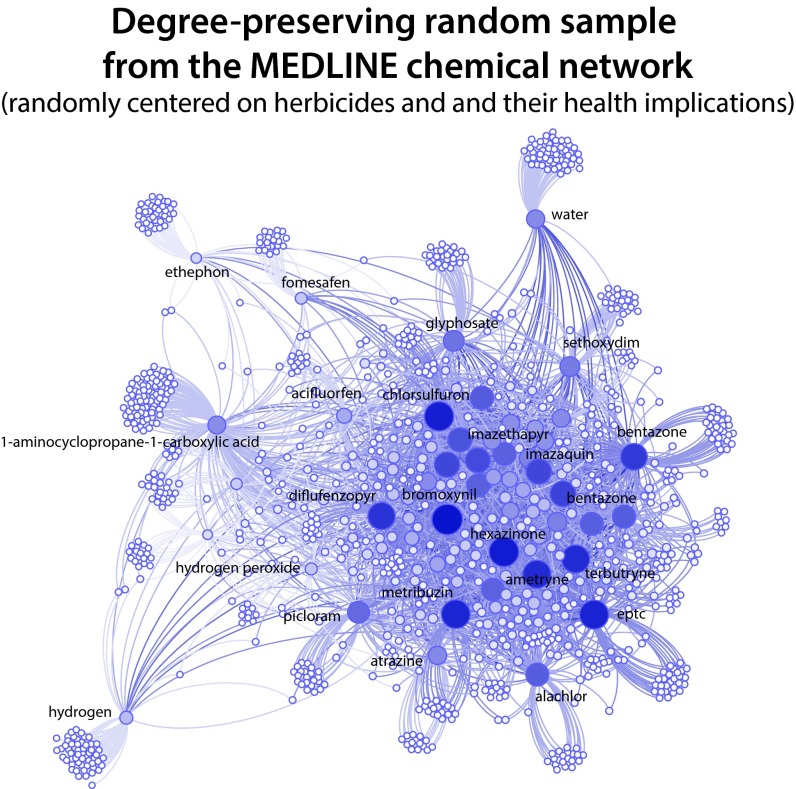
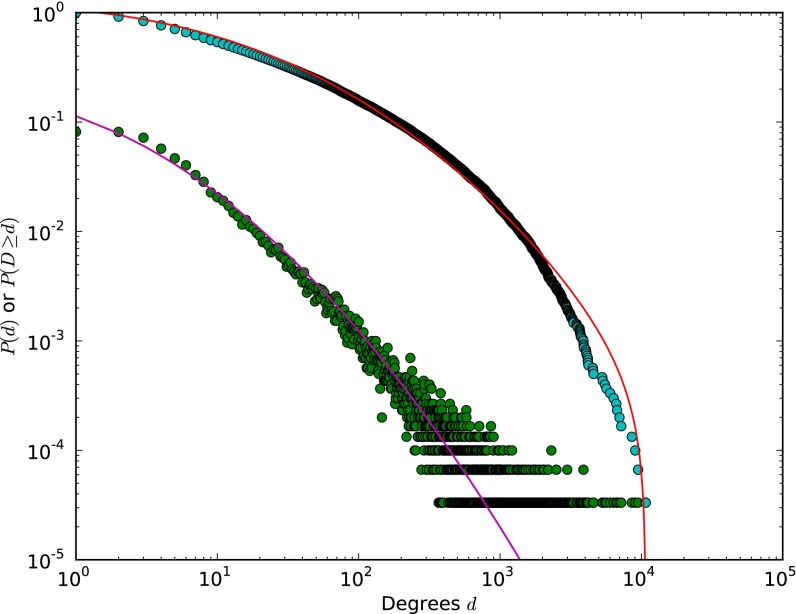
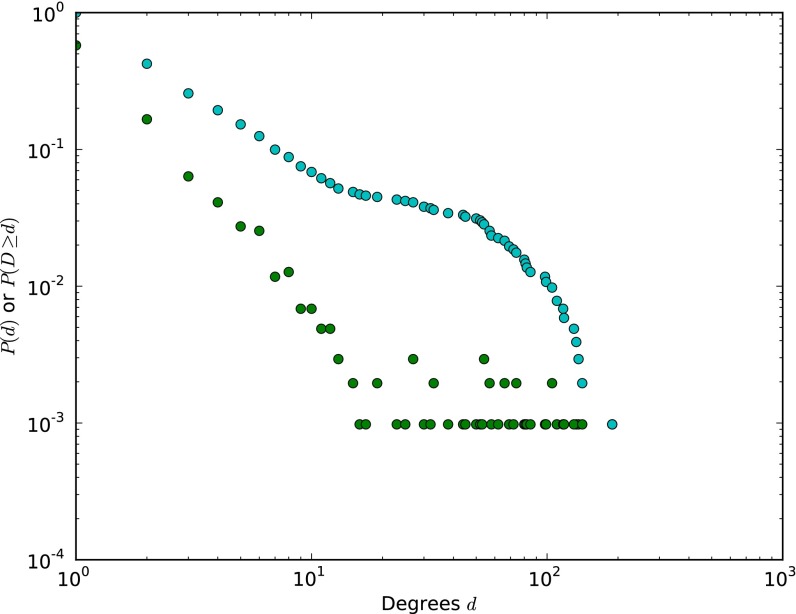
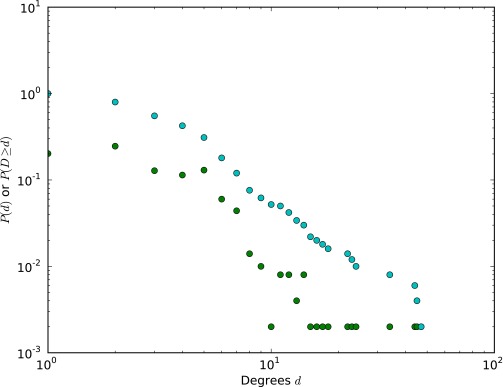
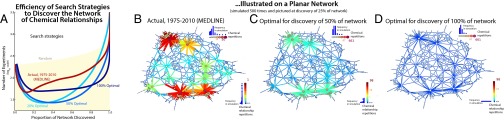
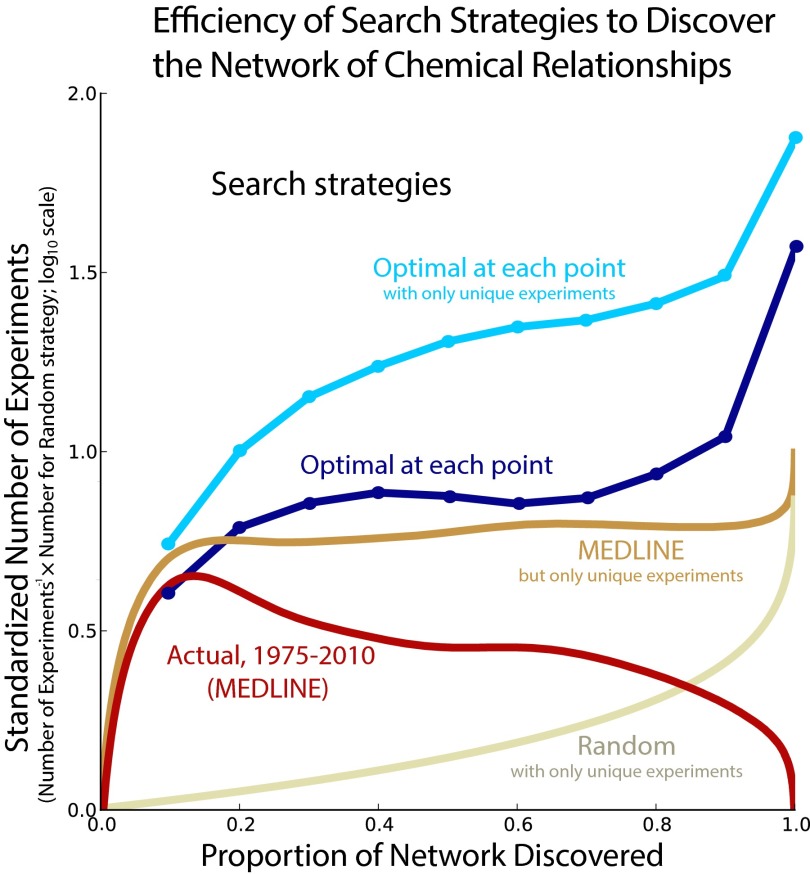
References
-
- Kleinberg J, Oren S. Mechanisms for (Mis)Allocating Scientific Credit, STOC ’11. Association for Computing Machinery; New York: 2011. pp. 529–538.
-
- Foster JG, Rzhetsky A, Evans JA. Tradition and innovation in scientists’ research strategies. Am Sociol Rev. 2015;80(5):875–908.
-
- Weisberg M, Muldoon R. Epistemic landscapes and the division of cognitive labor. Philos Sci. 2009;76(2):225–252.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
