

Mesolimbic dopamine signals the value of work
- PMID: 26595651
- PMCID: PMC4696912
- DOI: 10.1038/nn.4173
Mesolimbic dopamine signals the value of work
Abstract
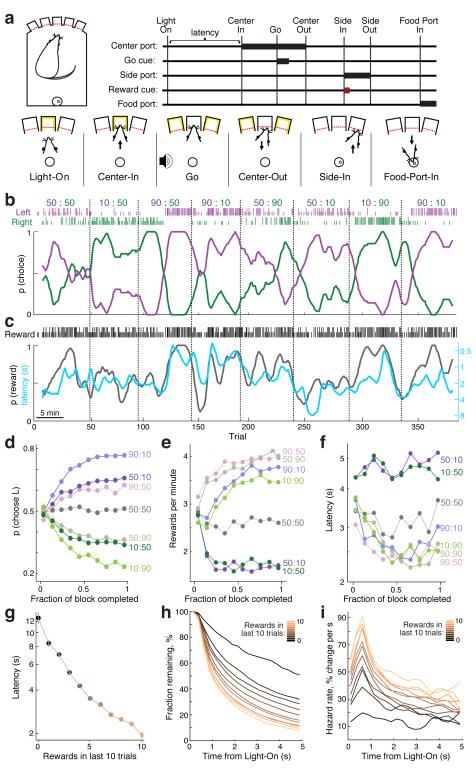
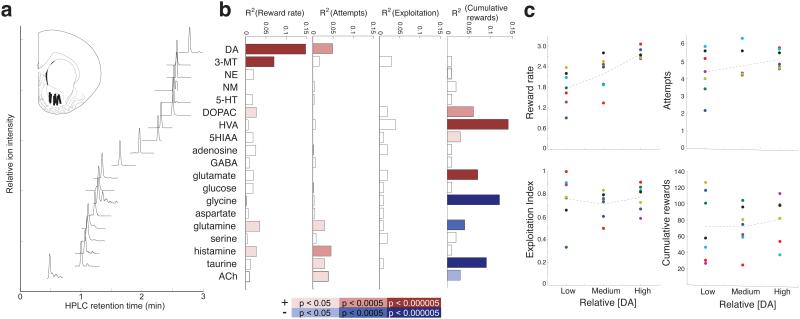
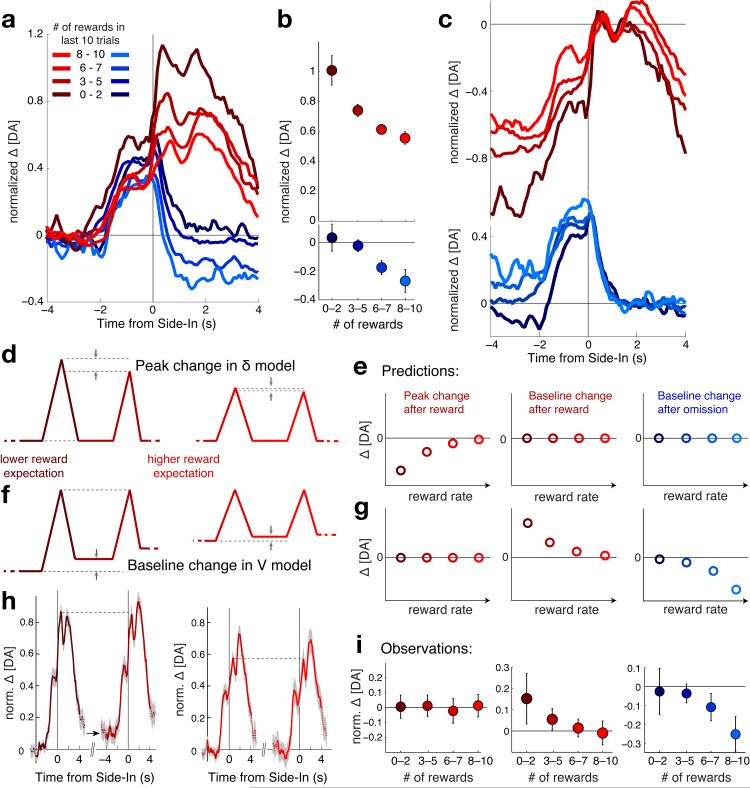
Dopamine cell firing can encode errors in reward prediction, providing a learning signal to guide future behavior. Yet dopamine is also a key modulator of motivation, invigorating current behavior. Existing theories propose that fast (phasic) dopamine fluctuations support learning, whereas much slower (tonic) dopamine changes are involved in motivation. We examined dopamine release in the nucleus accumbens across multiple time scales, using complementary microdialysis and voltammetric methods during adaptive decision-making. We found that minute-by-minute dopamine levels covaried with reward rate and motivational vigor. Second-by-second dopamine release encoded an estimate of temporally discounted future reward (a value function). Changing dopamine immediately altered willingness to work and reinforced preceding action choices by encoding temporal-difference reward prediction errors. Our results indicate that dopamine conveys a single, rapidly evolving decision variable, the available reward for investment of effort, which is employed for both learning and motivational functions.
Figures



References
-
- Reynolds JN, Hyland BI, Wickens JR. A cellular mechanism of reward-related learning. Nature. 2001;413:67–70. - PubMed
-
- Schultz W, Dayan P, Montague PR. A neural substrate of prediction and reward. Science. 1997;275:1593–9. - PubMed
-
- Day JJ, Roitman MF, Wightman RM, Carelli RM. Associative learning mediates dynamic shifts in dopamine signaling in the nucleus accumbens. Nat Neurosci. 2007;10:1020–8. doi:nn1923 [pii] 10.1038/nn1923. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
- EB003320/EB/NIBIB NIH HHS/United States
- R01 NS078435/NS/NINDS NIH HHS/United States
- T32 DA007281/DA/NIDA NIH HHS/United States
- NS076401/NS/NINDS NIH HHS/United States
- NS078435/NS/NINDS NIH HHS/United States
- DA007281/DA/NIDA NIH HHS/United States
- MH093888/MH/NIMH NIH HHS/United States
- R21 DA032259/DA/NIDA NIH HHS/United States
- R37 EB003320/EB/NIBIB NIH HHS/United States
- MH101697/MH/NIMH NIH HHS/United States
- DA032259/DA/NIDA NIH HHS/United States
- R01 EB003320/EB/NIBIB NIH HHS/United States
- T32 NS076401/NS/NINDS NIH HHS/United States
- T32 DA007268/DA/NIDA NIH HHS/United States
- R01 MH101697/MH/NIMH NIH HHS/United States
- R21 MH093888/MH/NIMH NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
