

Mirrored STDP Implements Autoencoder Learning in a Network of Spiking Neurons
- PMID: 26633645
- PMCID: PMC4669146
- DOI: 10.1371/journal.pcbi.1004566
Mirrored STDP Implements Autoencoder Learning in a Network of Spiking Neurons
Abstract
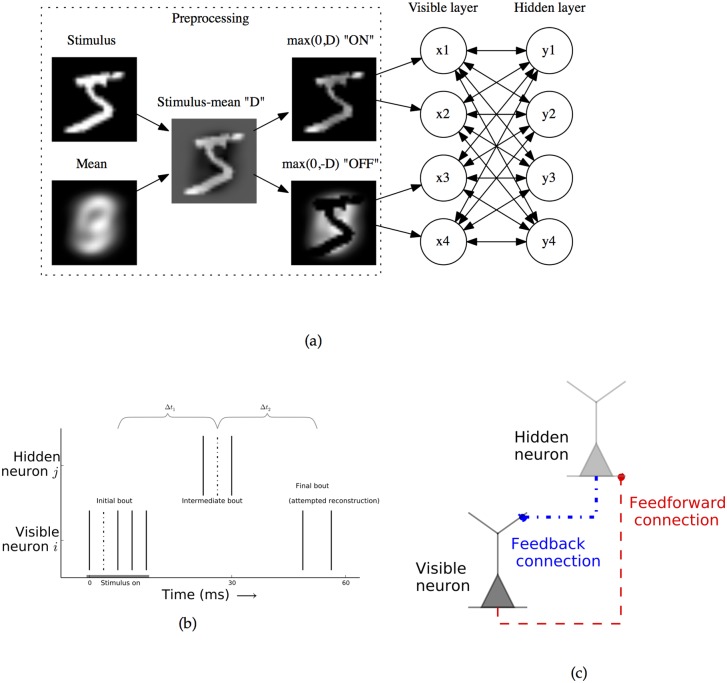
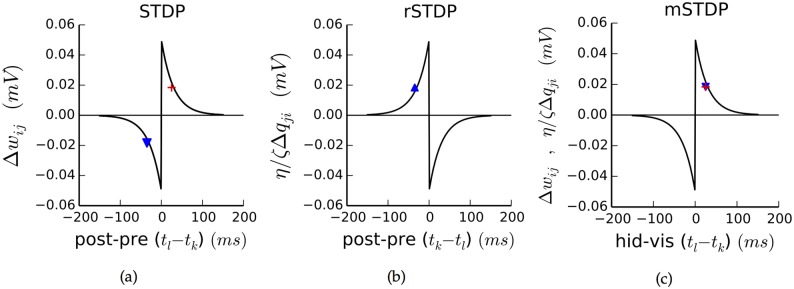
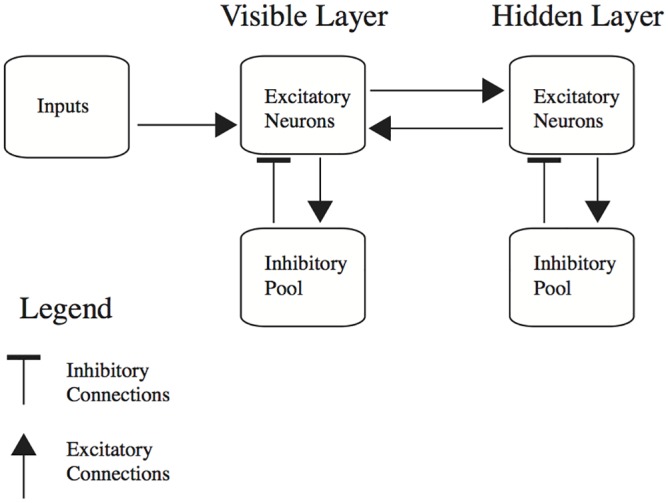
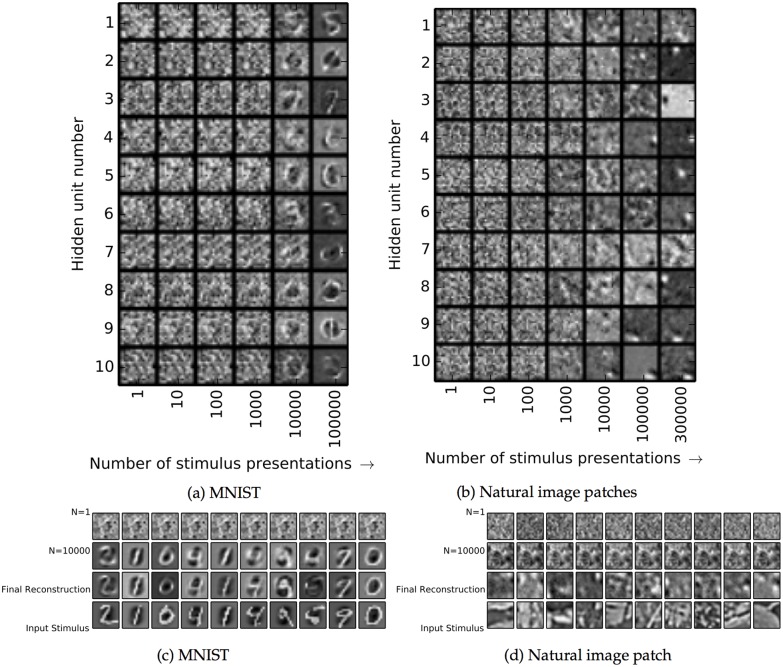
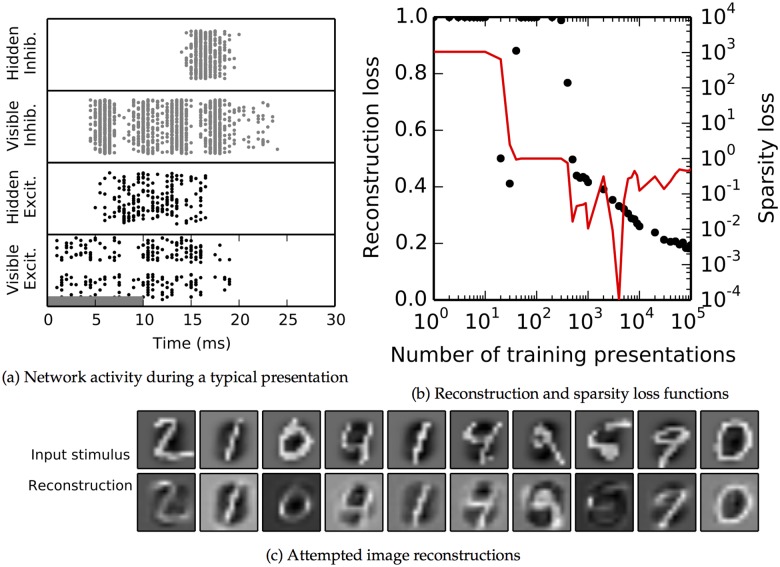
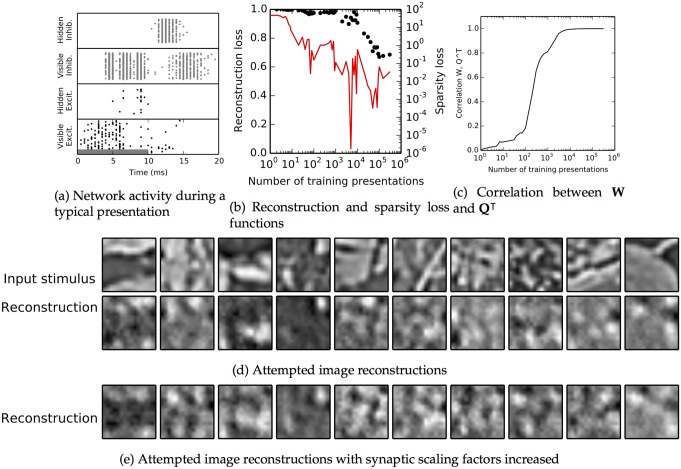
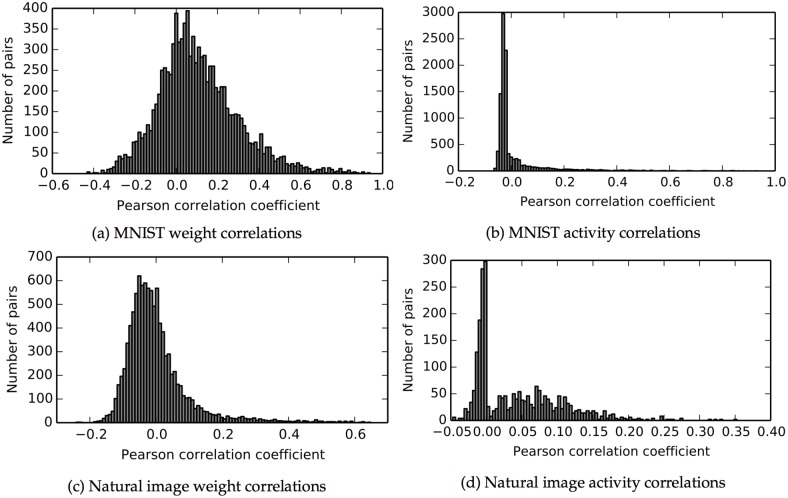
The autoencoder algorithm is a simple but powerful unsupervised method for training neural networks. Autoencoder networks can learn sparse distributed codes similar to those seen in cortical sensory areas such as visual area V1, but they can also be stacked to learn increasingly abstract representations. Several computational neuroscience models of sensory areas, including Olshausen & Field's Sparse Coding algorithm, can be seen as autoencoder variants, and autoencoders have seen extensive use in the machine learning community. Despite their power and versatility, autoencoders have been difficult to implement in a biologically realistic fashion. The challenges include their need to calculate differences between two neuronal activities and their requirement for learning rules which lead to identical changes at feedforward and feedback connections. Here, we study a biologically realistic network of integrate-and-fire neurons with anatomical connectivity and synaptic plasticity that closely matches that observed in cortical sensory areas. Our choice of synaptic plasticity rules is inspired by recent experimental and theoretical results suggesting that learning at feedback connections may have a different form from learning at feedforward connections, and our results depend critically on this novel choice of plasticity rules. Specifically, we propose that plasticity rules at feedforward versus feedback connections are temporally opposed versions of spike-timing dependent plasticity (STDP), leading to a symmetric combined rule we call Mirrored STDP (mSTDP). We show that with mSTDP, our network follows a learning rule that approximately minimizes an autoencoder loss function. When trained with whitened natural image patches, the learned synaptic weights resemble the receptive fields seen in V1. Our results use realistic synaptic plasticity rules to show that the powerful autoencoder learning algorithm could be within the reach of real biological networks.
Conflict of interest statement
The author has declared that no competing interests exist.
Figures



References
-
- Kohonen T. Self-organized formation of topologically correct feature maps. Biol Cybern. 1982;43(1):59–69. 10.1007/BF00337288 - DOI
-
- Sirosh J, Miikkulainen R. Cooperative self-organization of afferent and lateral connections in cortical maps. Biol Cybern. 1994;71(1):65–78. 10.1007/BF00198912 - DOI
-
- Choe Y, Miikkulainen R. Self-organization and segmentation in a laterally connected orientation map of spiking neurons. Neurocomputing. 1998. November;21(1–3):139–158. 10.1016/S0925-2312(98)00040-X - DOI
-
- Delorme A, Perrinet L, Thorpe SJ. Networks of integrate-and-fire neurons using Rank Order Coding B: Spike timing dependent plasticity and emergence of orientation selectivity. Neurocomputing. 2001. June;38–40:539–545. 10.1016/S0925-2312(01)00403-9 - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
