

Simple Plans or Sophisticated Habits? State, Transition and Learning Interactions in the Two-Step Task
- PMID: 26657806
- PMCID: PMC4686094
- DOI: 10.1371/journal.pcbi.1004648
Simple Plans or Sophisticated Habits? State, Transition and Learning Interactions in the Two-Step Task
Abstract
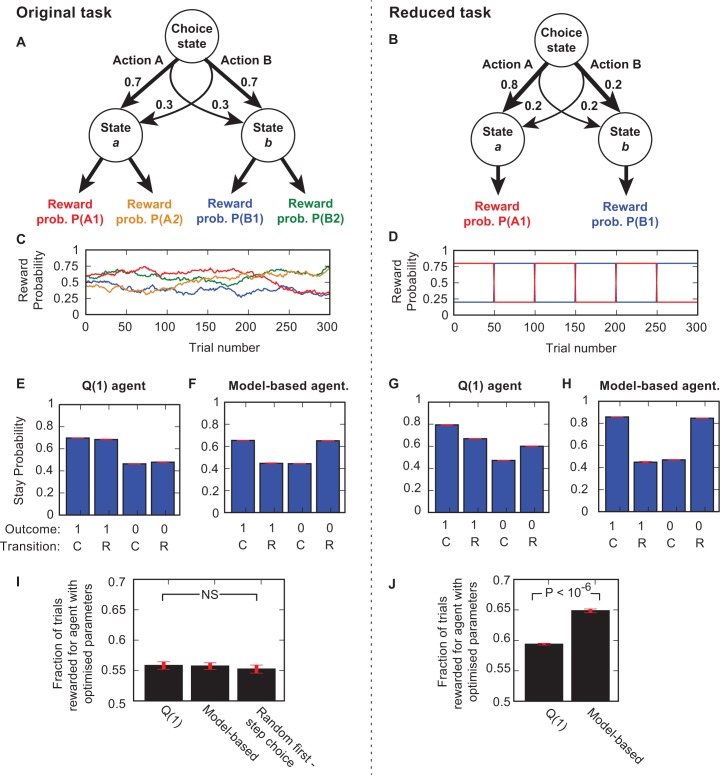
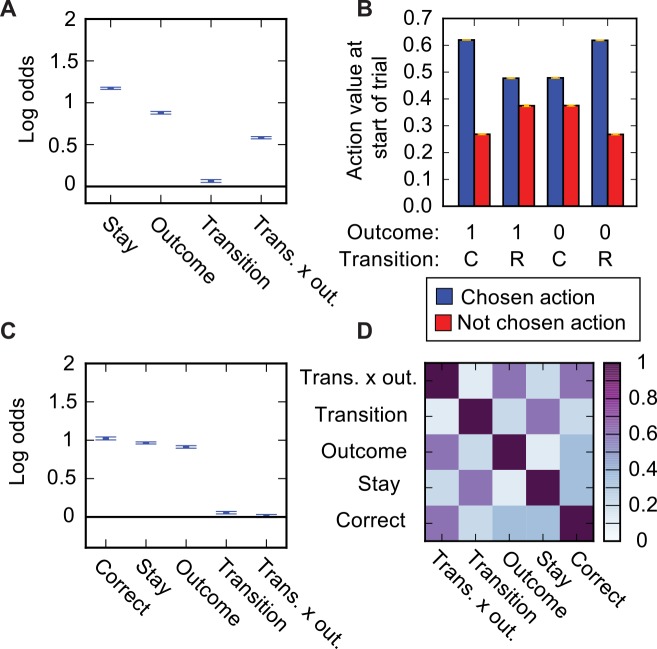
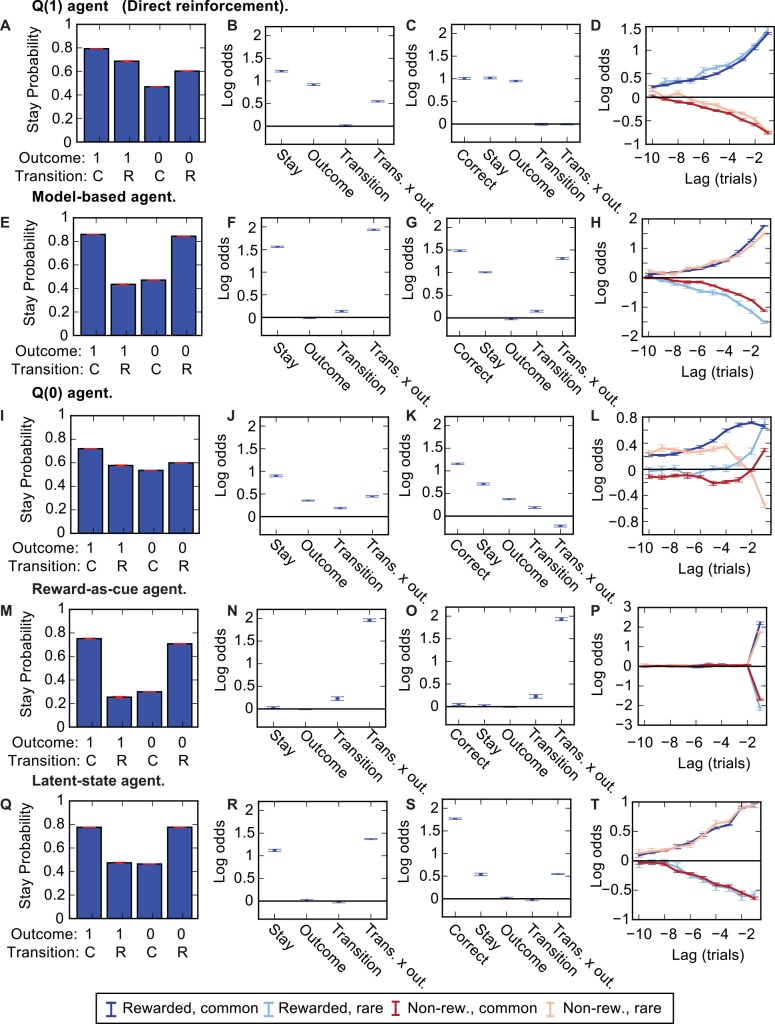
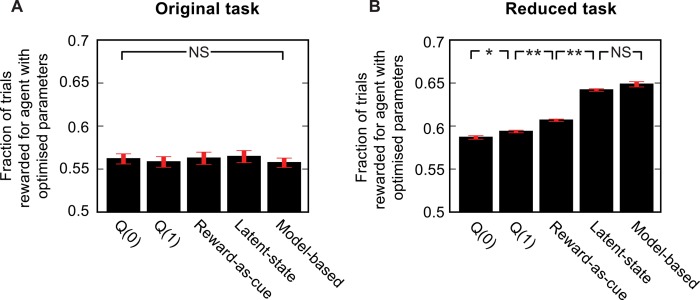
The recently developed 'two-step' behavioural task promises to differentiate model-based from model-free reinforcement learning, while generating neurophysiologically-friendly decision datasets with parametric variation of decision variables. These desirable features have prompted its widespread adoption. Here, we analyse the interactions between a range of different strategies and the structure of transitions and outcomes in order to examine constraints on what can be learned from behavioural performance. The task involves a trade-off between the need for stochasticity, to allow strategies to be discriminated, and a need for determinism, so that it is worth subjects' investment of effort to exploit the contingencies optimally. We show through simulation that under certain conditions model-free strategies can masquerade as being model-based. We first show that seemingly innocuous modifications to the task structure can induce correlations between action values at the start of the trial and the subsequent trial events in such a way that analysis based on comparing successive trials can lead to erroneous conclusions. We confirm the power of a suggested correction to the analysis that can alleviate this problem. We then consider model-free reinforcement learning strategies that exploit correlations between where rewards are obtained and which actions have high expected value. These generate behaviour that appears model-based under these, and also more sophisticated, analyses. Exploiting the full potential of the two-step task as a tool for behavioural neuroscience requires an understanding of these issues.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
-
- Balleine BW, Dickinson A. Goal-directed instrumental action: contingency and incentive learning and their cortical substrates. Neuropharmacology. 1998;37: 407–419. - PubMed
-
- Sutton RS, Barto AG. Reinforcement learning: An introduction The MIT press; 1998.
-
- Daw ND, Niv Y, Dayan P. Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nat Neurosci. 2005;8: 1704–11. doi:nn1560 - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
