

Directly data-derived articulatory gesture-like representations retain discriminatory information about phone categories
- PMID: 26688612
- PMCID: PMC4681009
- DOI: 10.1016/j.csl.2015.03.004
Directly data-derived articulatory gesture-like representations retain discriminatory information about phone categories
Abstract
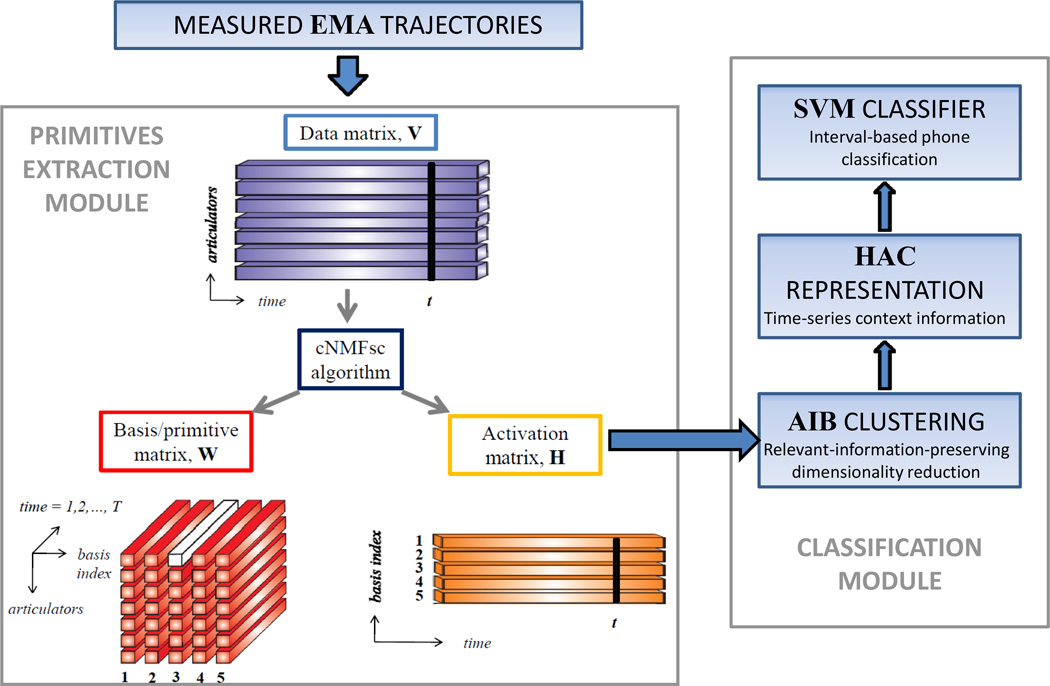
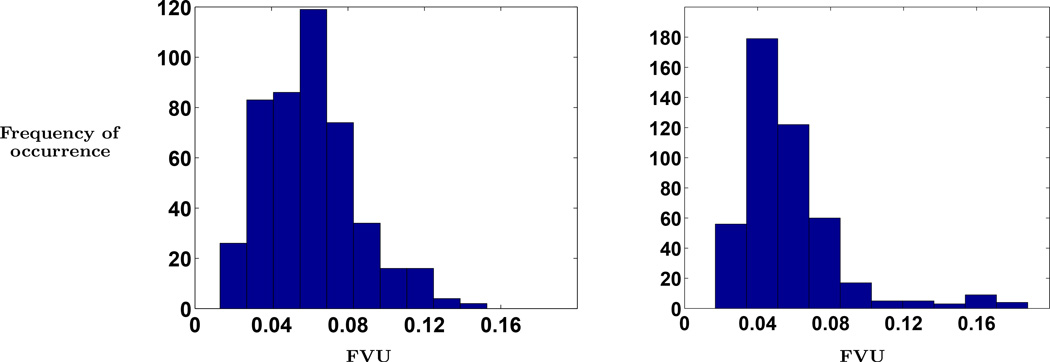
How the speech production and perception systems evolved in humans still remains a mystery today. Previous research suggests that human auditory systems are able, and have possibly evolved, to preserve maximal information about the speaker's articulatory gestures. This paper attempts an initial step towards answering the complementary question of whether speakers' articulatory mechanisms have also evolved to produce sounds that can be optimally discriminated by the listener's auditory system. To this end we explicitly model, using computational methods, the extent to which derived representations of "primitive movements" of speech articulation can be used to discriminate between broad phone categories. We extract interpretable spatio-temporal primitive movements as recurring patterns in a data matrix of human speech articulation, i.e. representing the trajectories of vocal tract articulators over time. To this end, we propose a weakly-supervised learning method that attempts to find a part-based representation of the data in terms of recurring basis trajectory units (or primitives) and their corresponding activations over time. For each phone interval, we then derive a feature representation that captures the co-occurrences between the activations of the various bases over different time-lags. We show that this feature, derived entirely from activations of these primitive movements, is able to achieve a greater discrimination relative to using conventional features on an interval-based phone classification task. We discuss the implications of these findings in furthering our understanding of speech signal representations and the links between speech production and perception systems.
Keywords: information transfer; motor theory; movement primitives; phone classification; speech communication.
Figures








References
-
- Akaike H. Likelihood of a model and information criteria. Journal of Econometrics. 1981;16(1):3–14.
-
- Arora R, Livescu K. Multi-view cca-based acoustic features for phonetic recognition across speakers and domains; Int. Conf. on Acoustics, Speech, and Signal Processing; 2013.
-
- Atal B. Automatic speech recognition: A communication perspective. ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing-Proceedings. 1999;1:457–460.
-
- Atal BS, Chang J, Mathews MV, Tukey JW. Inversion of articulatory-to-acoustic transformation in the vocal tract by a computer-sorting technique. The Journal of the Acoustical Society of America. 1978;63(5):1535–1555. - PubMed
-
- Bertrand A, Demuynck K, Stouten V, Van hamme H. Unsupervised learning of auditory filter banks using non-negative matrix factorisation; IEEE International Conference on Acoustics, Speech and Signal Processing; 2008. pp. 4713–4716.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources