

SLOPE-ADAPTIVE VARIABLE SELECTION VIA CONVEX OPTIMIZATION
- PMID: 26709357
- PMCID: PMC4689150
- DOI: 10.1214/15-AOAS842
SLOPE-ADAPTIVE VARIABLE SELECTION VIA CONVEX OPTIMIZATION
Abstract
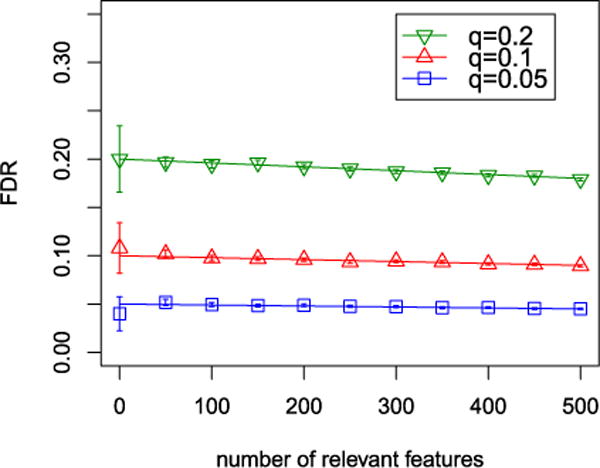
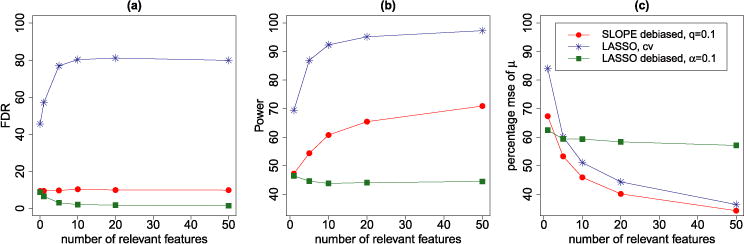
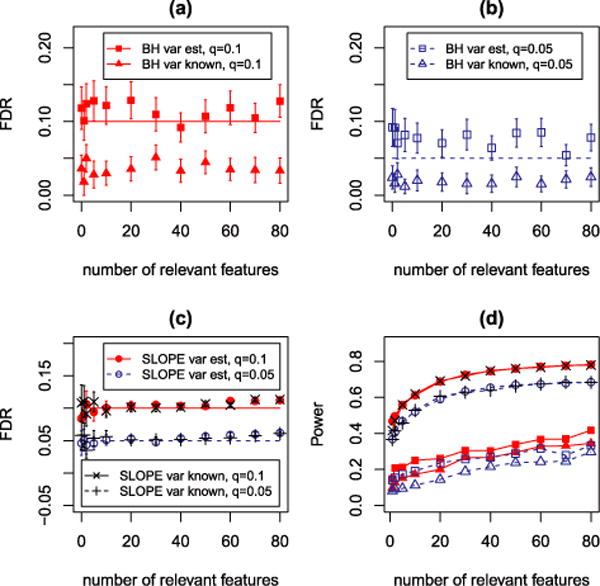
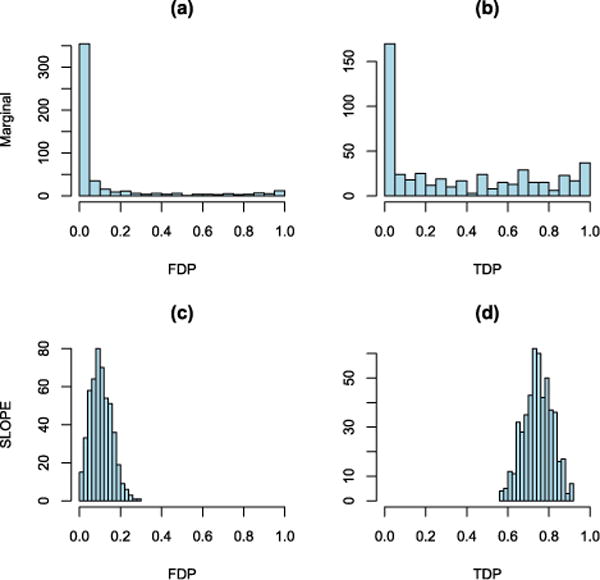
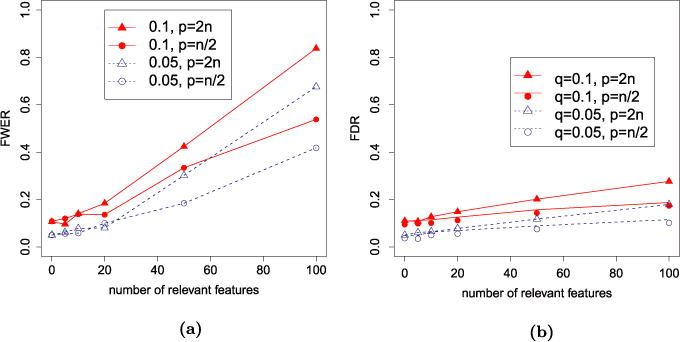
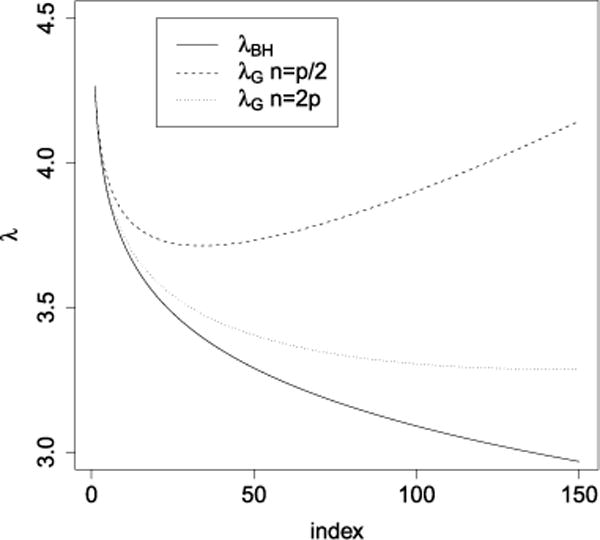
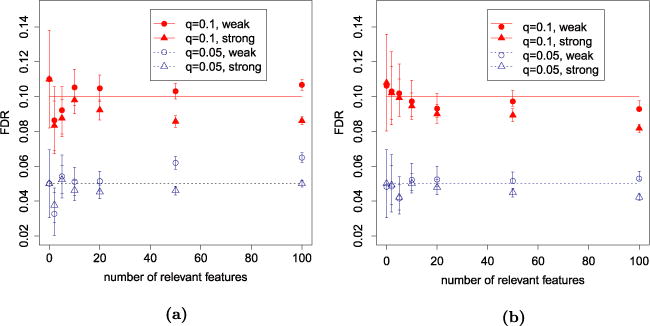
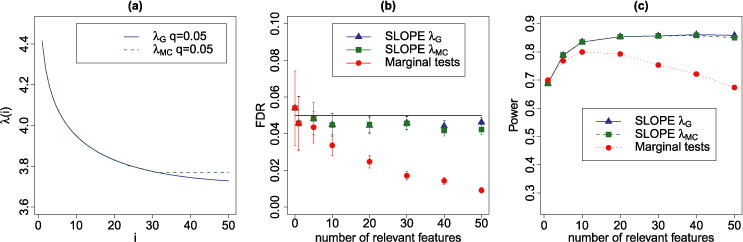
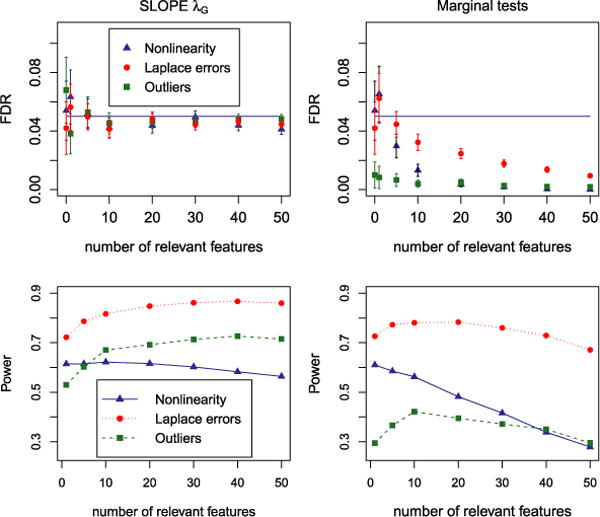
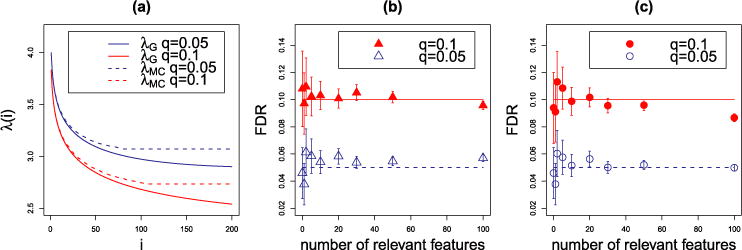
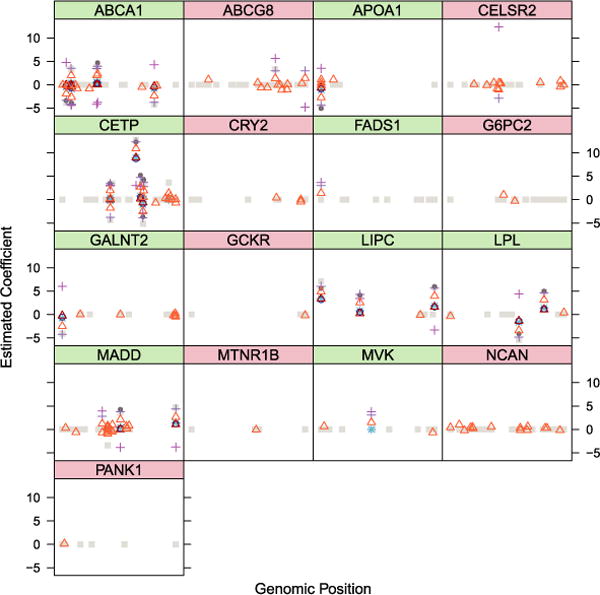
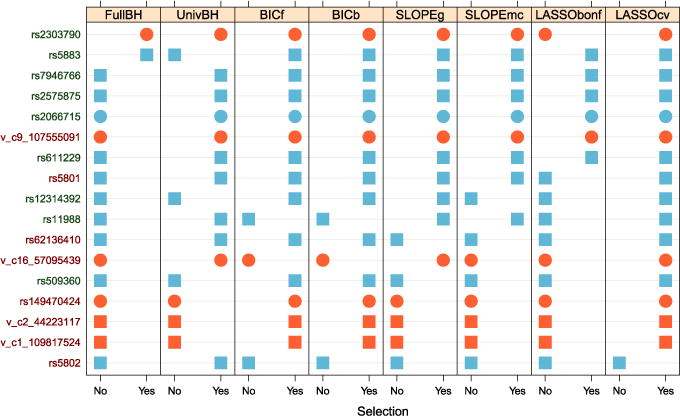
We introduce a new estimator for the vector of coefficients β in the linear model y = Xβ + z, where X has dimensions n × p with p possibly larger than n. SLOPE, short for Sorted L-One Penalized Estimation, is the solution to [Formula: see text]where λ1 ≥ λ2 ≥ … ≥ λ p ≥ 0 and [Formula: see text] are the decreasing absolute values of the entries of b. This is a convex program and we demonstrate a solution algorithm whose computational complexity is roughly comparable to that of classical ℓ1 procedures such as the Lasso. Here, the regularizer is a sorted ℓ1 norm, which penalizes the regression coefficients according to their rank: the higher the rank-that is, stronger the signal-the larger the penalty. This is similar to the Benjamini and Hochberg [J. Roy. Statist. Soc. Ser. B57 (1995) 289-300] procedure (BH) which compares more significant p-values with more stringent thresholds. One notable choice of the sequence {λ i } is given by the BH critical values [Formula: see text], where q ∈ (0, 1) and z(α) is the quantile of a standard normal distribution. SLOPE aims to provide finite sample guarantees on the selected model; of special interest is the false discovery rate (FDR), defined as the expected proportion of irrelevant regressors among all selected predictors. Under orthogonal designs, SLOPE with λBH provably controls FDR at level q. Moreover, it also appears to have appreciable inferential properties under more general designs X while having substantial power, as demonstrated in a series of experiments running on both simulated and real data.
Keywords: Lasso; Sparse regression; false discovery rate; sorted ℓ1 penalized estimation (SLOPE); variable selection.
Figures
References
-
- Abramovich F, Benjamini Y. Wavelets and Statistics Lecture Notes in Statistics. Vol. 103. Springer; Berlin: 1995. Thresholding of wavelet coefficients as multiple hypotheses testing procedure; pp. 5–14.
-
- Abramovich F, Benjamini Y, Donoho DL, Johnstone IM. Adapting to unknown sparsity by controlling the false discovery rate. Ann Statist. 2006;34:584–653. MR2281879.
-
- Akaike H. A new look at the statistical model identification. (System identification and time-series analysis).IEEE Trans Automat Control. 1974;AC-19:716–723. MR0423716.
-
- Barlow RE, Bartholomew DJ, Bremner JM, Brunk HD. Statistical Inference Under Order Restrictions The Theory and Application of Isotonic Regression. Wiley; New York: 1972. MR0326887.
-
- Bauer P, Pötscher BM, Hackl P. Model selection by multiple test procedures. Statistics. 1988;19:39–44. MR0921623.
Grants and funding
LinkOut - more resources
Full Text Sources