

Codon influence on protein expression in E. coli correlates with mRNA levels
- PMID: 26760206
- PMCID: PMC5054687
- DOI: 10.1038/nature16509
Codon influence on protein expression in E. coli correlates with mRNA levels
Abstract
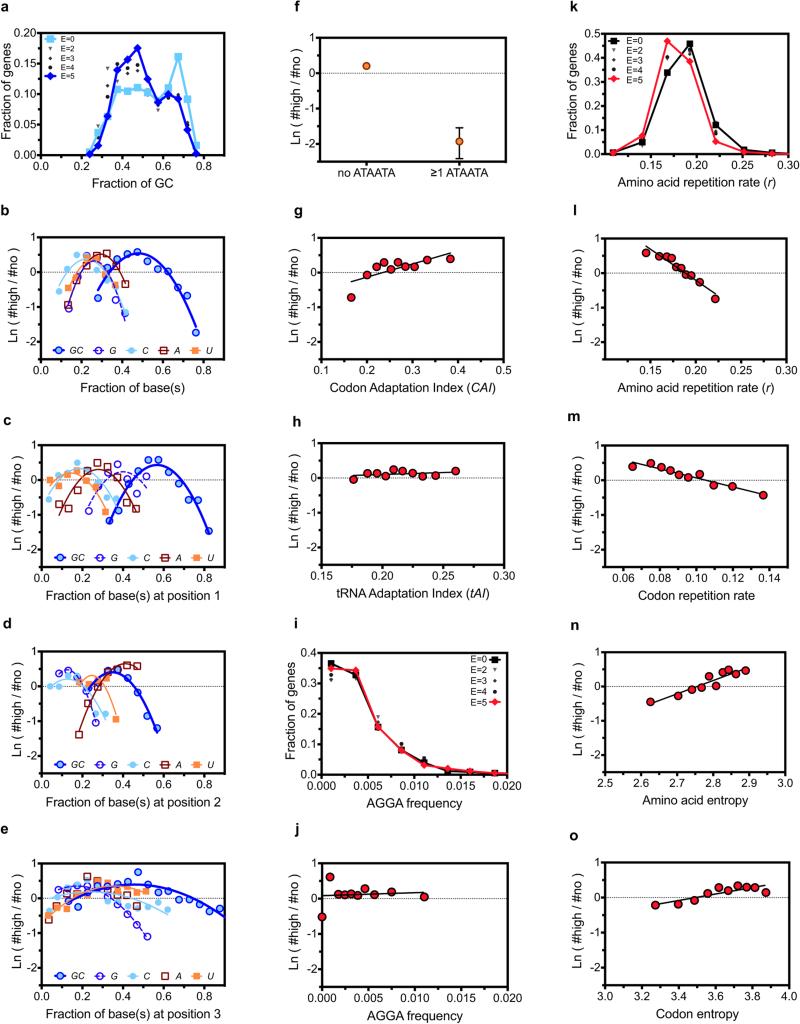
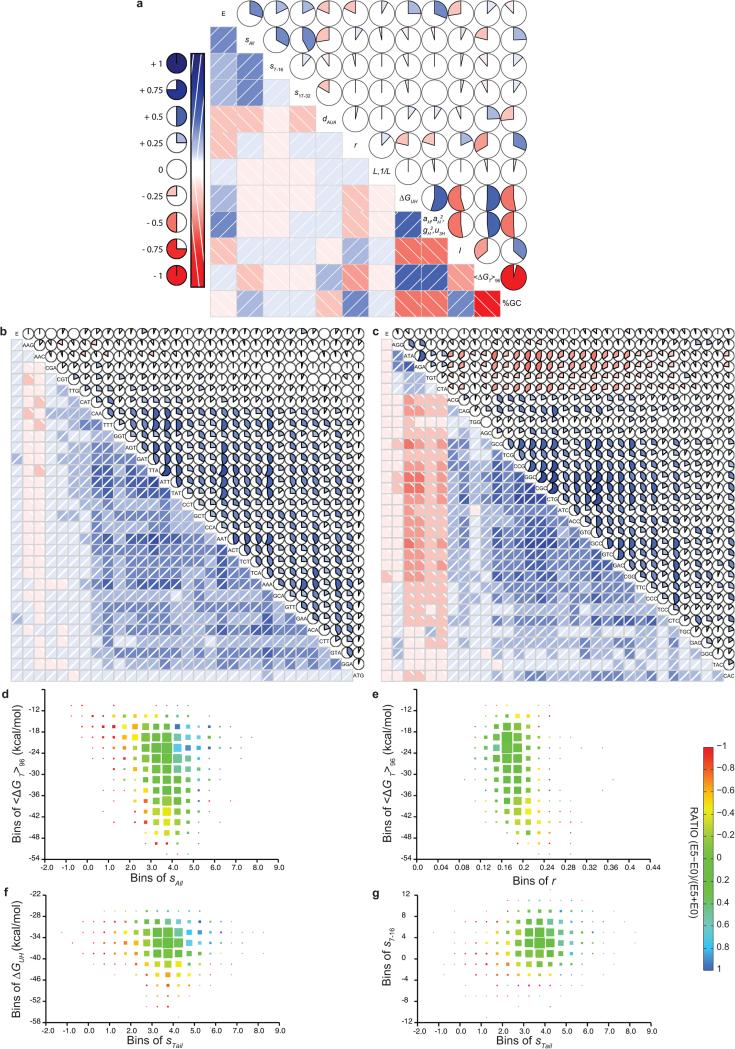
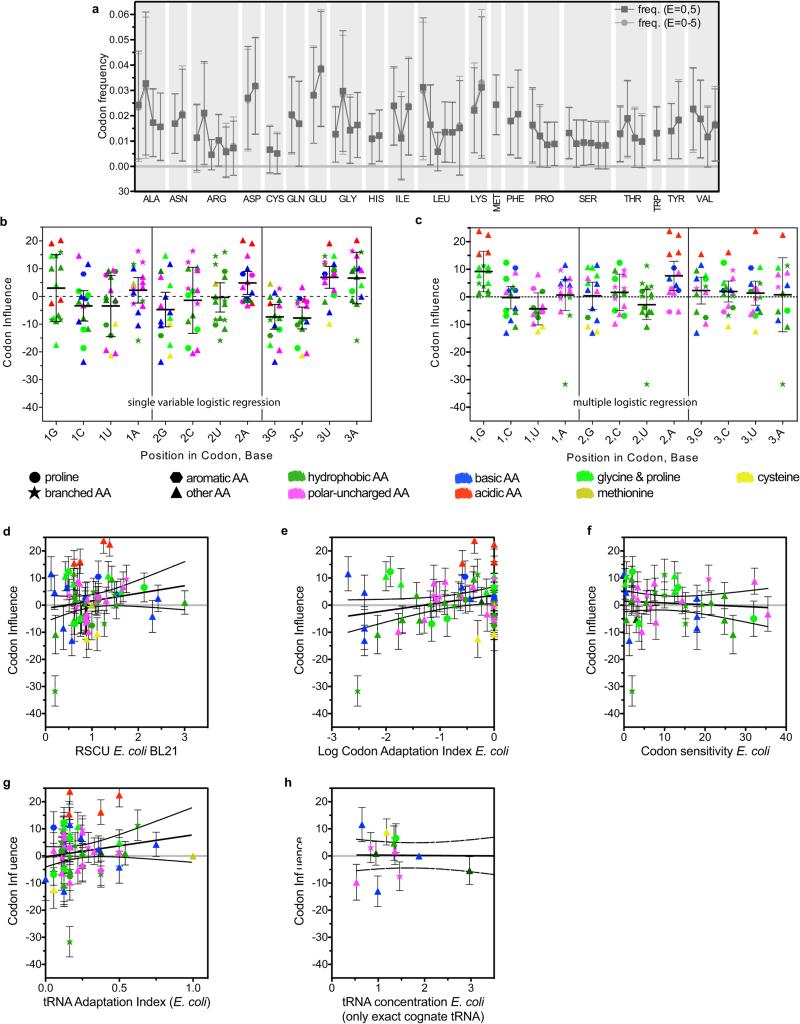
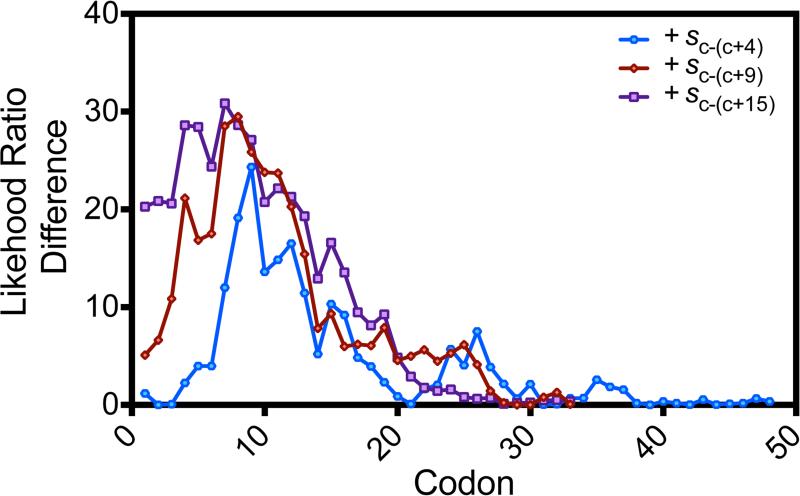
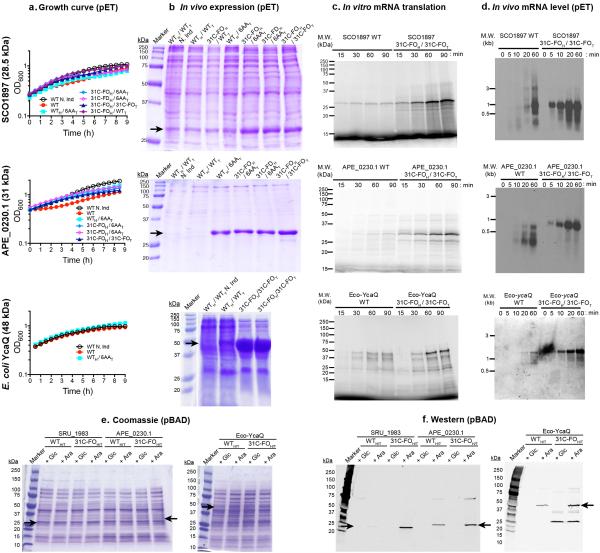
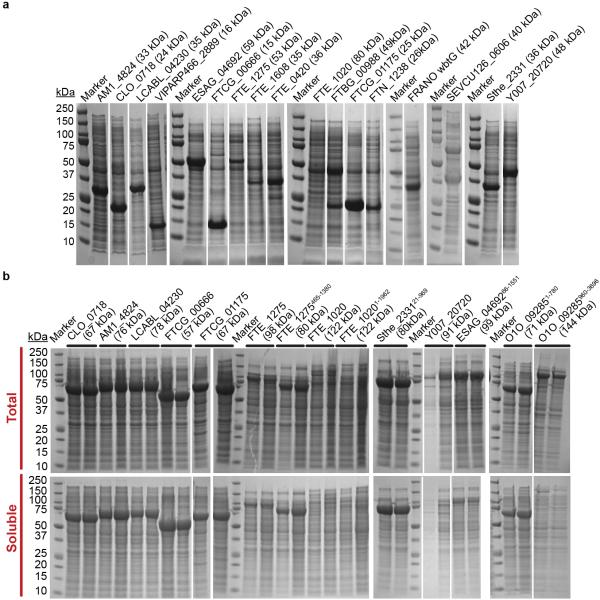
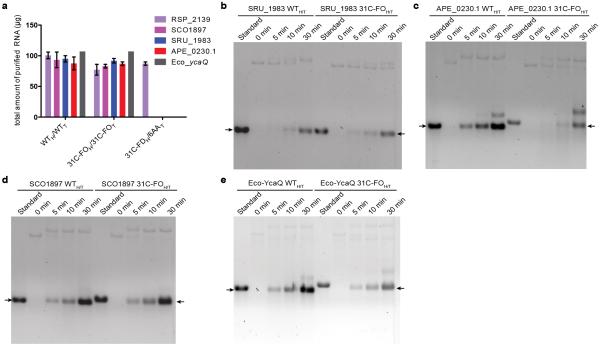
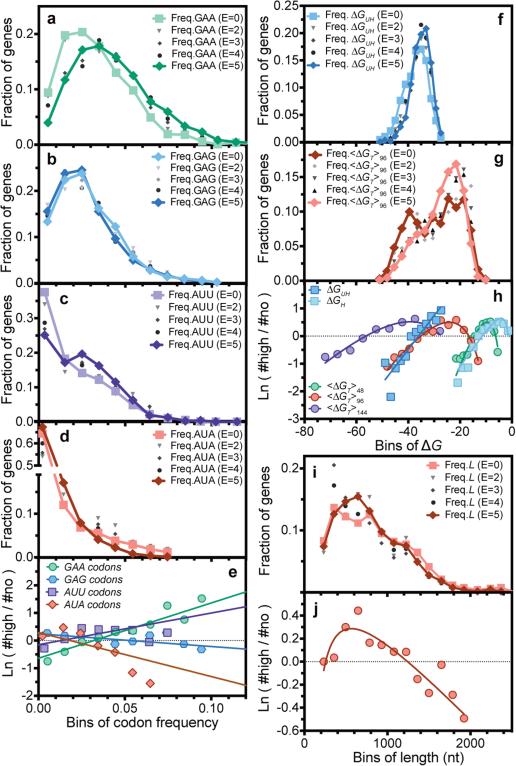
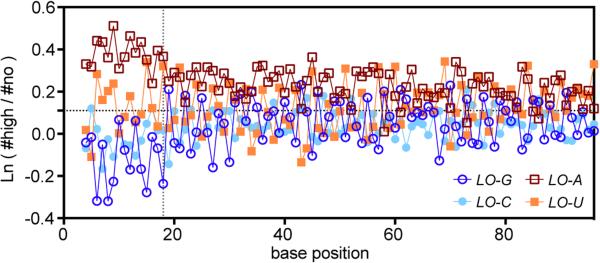
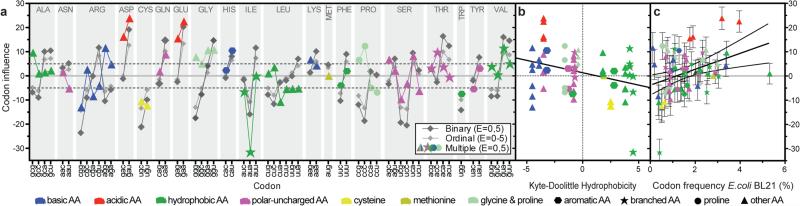
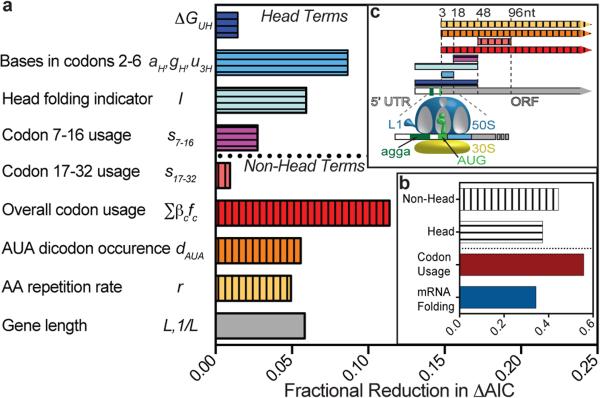
Degeneracy in the genetic code, which enables a single protein to be encoded by a multitude of synonymous gene sequences, has an important role in regulating protein expression, but substantial uncertainty exists concerning the details of this phenomenon. Here we analyse the sequence features influencing protein expression levels in 6,348 experiments using bacteriophage T7 polymerase to synthesize messenger RNA in Escherichia coli. Logistic regression yields a new codon-influence metric that correlates only weakly with genomic codon-usage frequency, but strongly with global physiological protein concentrations and also mRNA concentrations and lifetimes in vivo. Overall, the codon content influences protein expression more strongly than mRNA-folding parameters, although the latter dominate in the initial ~16 codons. Genes redesigned based on our analyses are transcribed with unaltered efficiency but translated with higher efficiency in vitro. The less efficiently translated native sequences show greatly reduced mRNA levels in vivo. Our results suggest that codon content modulates a kinetic competition between protein elongation and mRNA degradation that is a central feature of the physiology and also possibly the regulation of translation in E. coli.
Figures
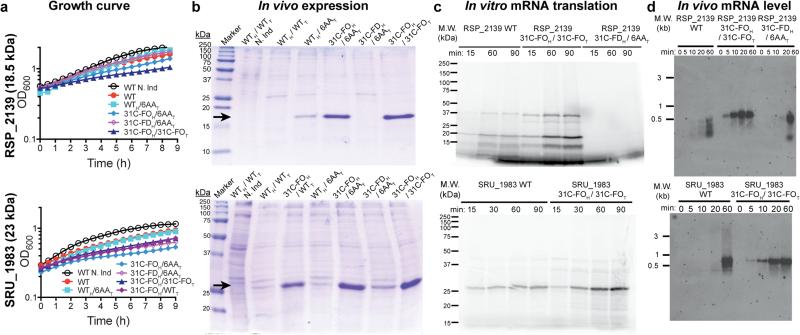
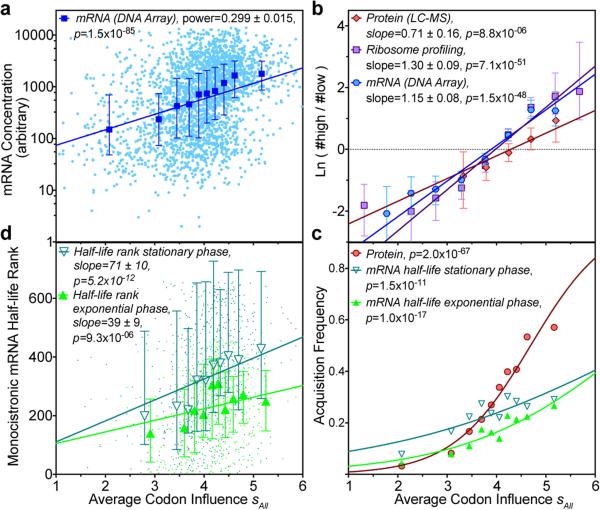
References
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
