

Energy Scaling Advantages of Resistive Memory Crossbar Based Computation and Its Application to Sparse Coding
- PMID: 26778946
- PMCID: PMC4701906
- DOI: 10.3389/fnins.2015.00484
Energy Scaling Advantages of Resistive Memory Crossbar Based Computation and Its Application to Sparse Coding
Abstract
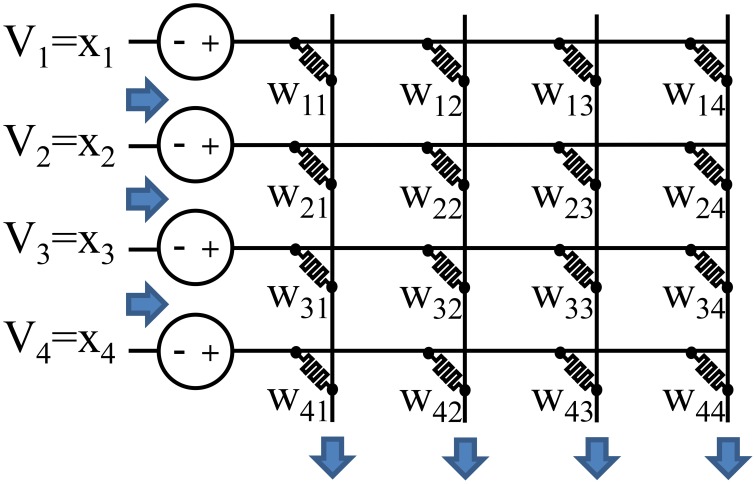
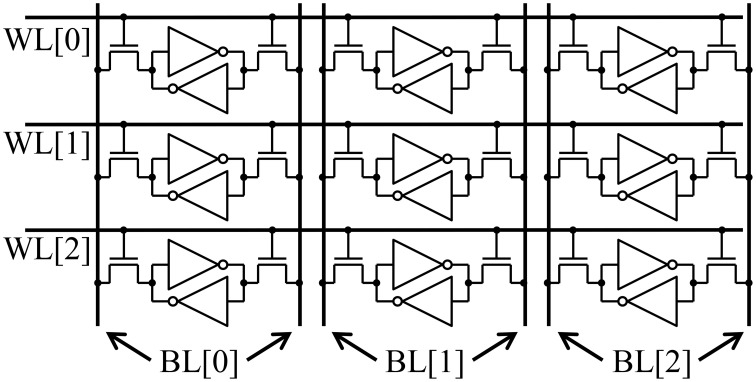
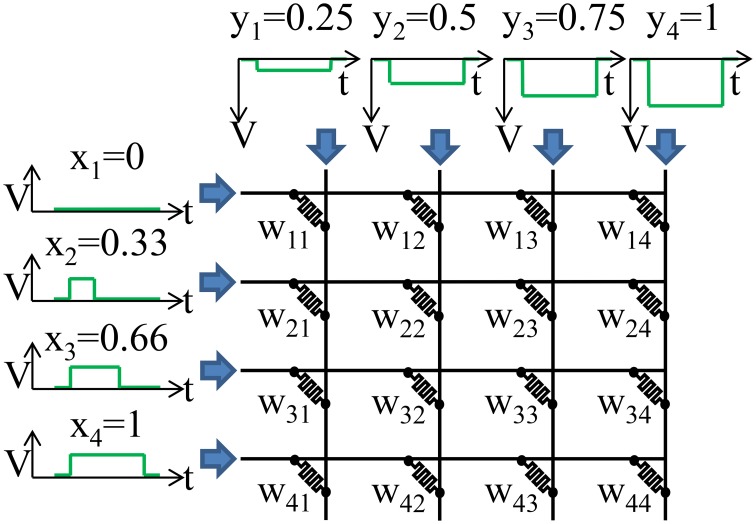
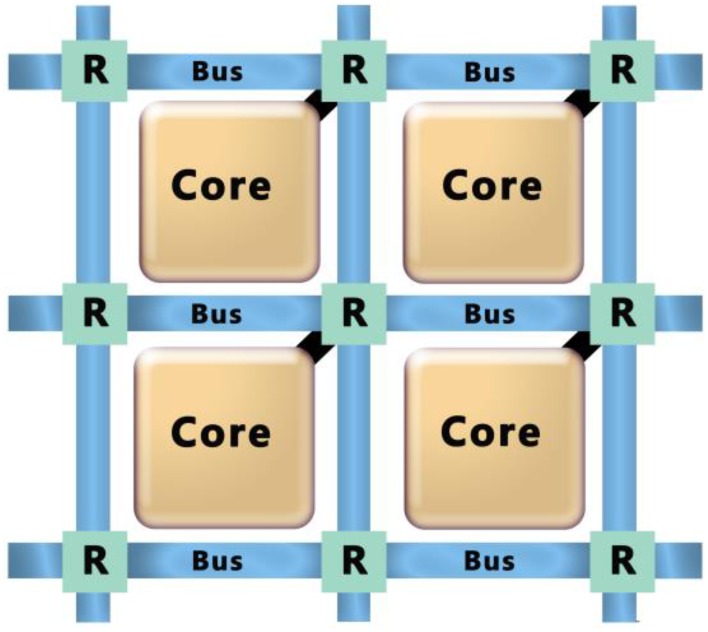
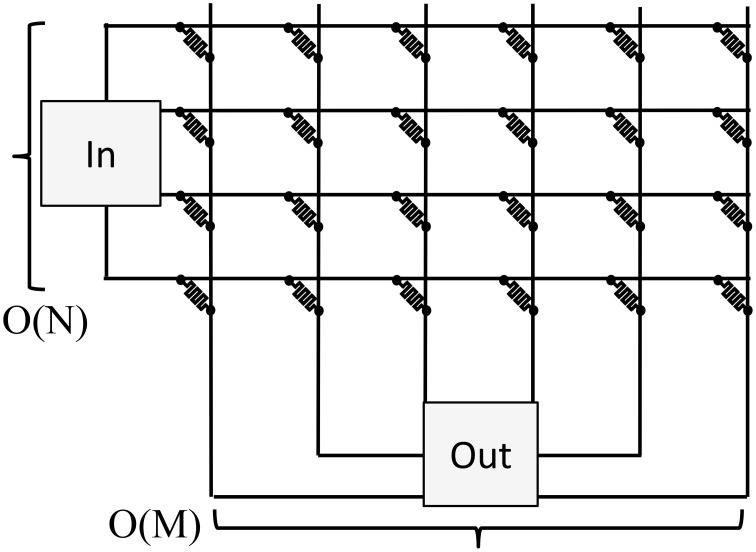
The exponential increase in data over the last decade presents a significant challenge to analytics efforts that seek to process and interpret such data for various applications. Neural-inspired computing approaches are being developed in order to leverage the computational properties of the analog, low-power data processing observed in biological systems. Analog resistive memory crossbars can perform a parallel read or a vector-matrix multiplication as well as a parallel write or a rank-1 update with high computational efficiency. For an N × N crossbar, these two kernels can be O(N) more energy efficient than a conventional digital memory-based architecture. If the read operation is noise limited, the energy to read a column can be independent of the crossbar size (O(1)). These two kernels form the basis of many neuromorphic algorithms such as image, text, and speech recognition. For instance, these kernels can be applied to a neural sparse coding algorithm to give an O(N) reduction in energy for the entire algorithm when run with finite precision. Sparse coding is a rich problem with a host of applications including computer vision, object tracking, and more generally unsupervised learning.
Keywords: energy; memristor; neuromorphic computing; resistive memory; sparse coding.
Figures
References
-
- Arora S., Ge R., Ma T., Moitra A. (2015). Simple, efficient, and neural algorithms for sparse coding. arXiv preprint arXiv:1503.00778. - PubMed
-
- Burr G. W., Shelby R. M., Sidler S., di Nolfo C., Jang J., Boybat I., et al. (2015). Experimental demonstration and tolerancing of a large-scale neural network (165 000 Synapses) using phase-change memory as the synaptic weight element. IEEE Trans. Electron Dev. 62, 3498–3507. 10.1109/TED.2015.2439635 - DOI
-
- Cassidy A. S., Alvarez-Icaza R., Akopyan F., Sawada J., Arthur J. V., Merolla P. A., et al. (2014). Real-time scalable cortical computing at 46 giga-synaptic OPS/watt with ~100 × Speedup in Time-to-Solution and ~100,000 × reduction in energy-to-solution, in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (New Orleans, LA: IEEE Press; ), 27–38.
-
- Chen A. (2013). A comprehensive crossbar array model with solutions for line resistance and nonlinear device characteristics. IEEE Trans. Electron Dev. 60, 1318–1326. 10.1109/TED.2013.2246791 - DOI
-
- Chen H.-Y., Gao B., Li H., Liu R., Huang P., Chen Z., et al. (2014). Towards high-speed, write-disturb tolerant 3D vertical RRAM arrays, in Digest of Technical Papers, 2014 Symposium on: IEEE VLSI Technology (VLSI-Technology) (Honolulu, HI: ), 1–2.
LinkOut - more resources
Full Text Sources
Other Literature Sources