

Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition
- PMID: 26797612
- PMCID: PMC4732148
- DOI: 10.3390/s16010115
Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition
Abstract
Human activity recognition (HAR) tasks have traditionally been solved using engineered features obtained by heuristic processes. Current research suggests that deep convolutional neural networks are suited to automate feature extraction from raw sensor inputs. However, human activities are made of complex sequences of motor movements, and capturing this temporal dynamics is fundamental for successful HAR. Based on the recent success of recurrent neural networks for time series domains, we propose a generic deep framework for activity recognition based on convolutional and LSTM recurrent units, which: (i) is suitable for multimodal wearable sensors; (ii) can perform sensor fusion naturally; (iii) does not require expert knowledge in designing features; and (iv) explicitly models the temporal dynamics of feature activations. We evaluate our framework on two datasets, one of which has been used in a public activity recognition challenge. Our results show that our framework outperforms competing deep non-recurrent networks on the challenge dataset by 4% on average; outperforming some of the previous reported results by up to 9%. Our results show that the framework can be applied to homogeneous sensor modalities, but can also fuse multimodal sensors to improve performance. We characterise key architectural hyperparameters' influence on performance to provide insights about their optimisation.
Keywords: LSTM; deep learning; human activity recognition; machine learning; neural network; sensor fusion; wearable sensors.
Figures
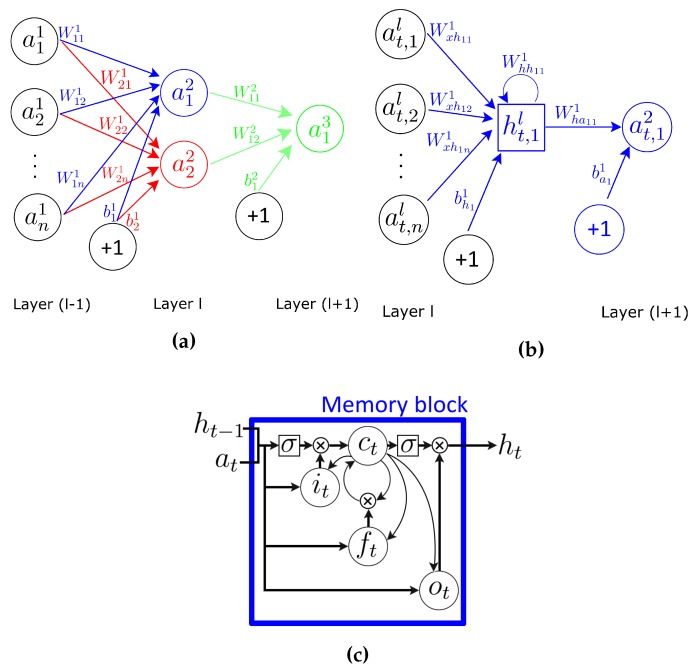
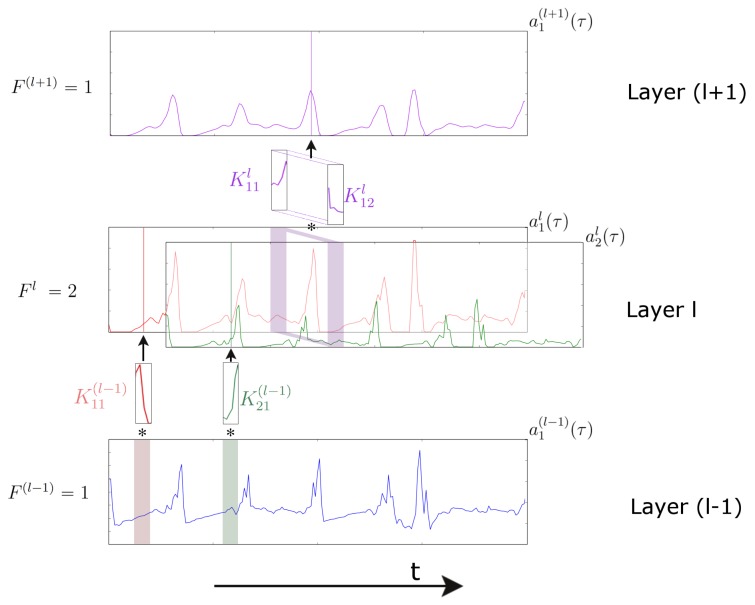
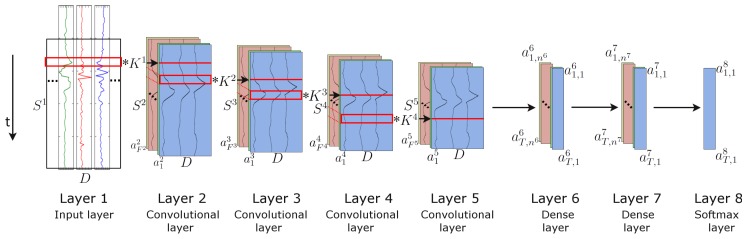
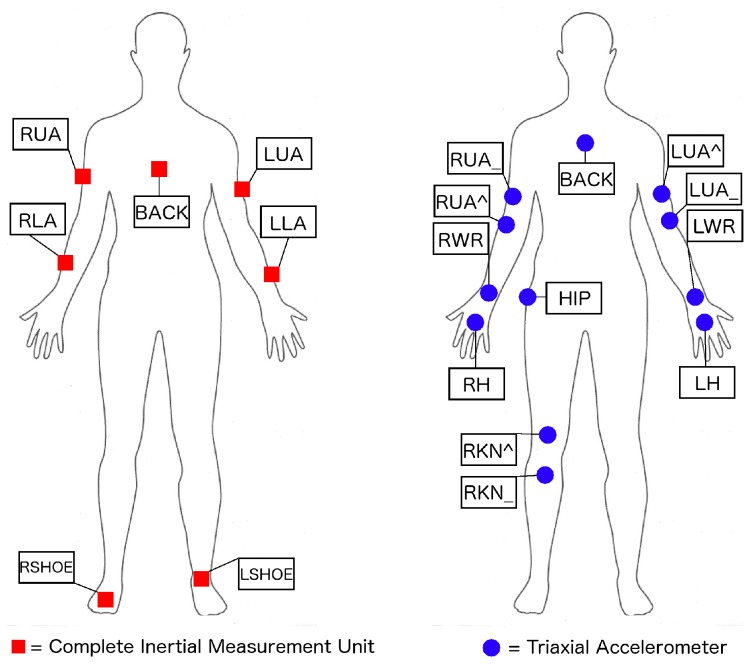
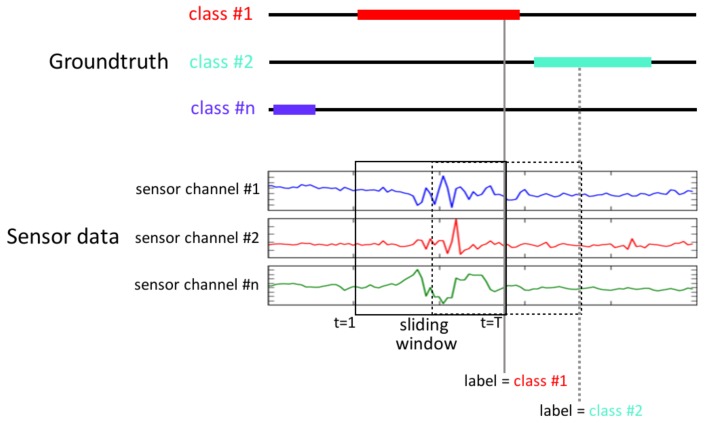
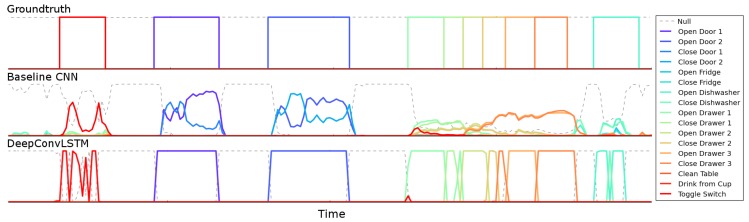
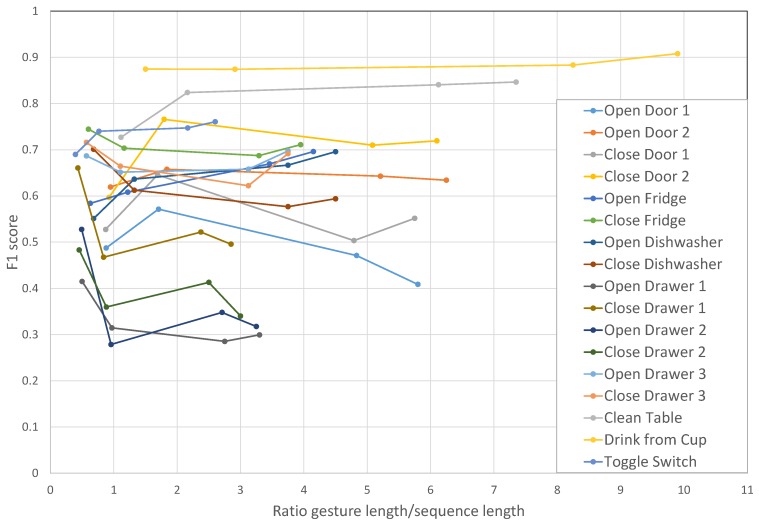
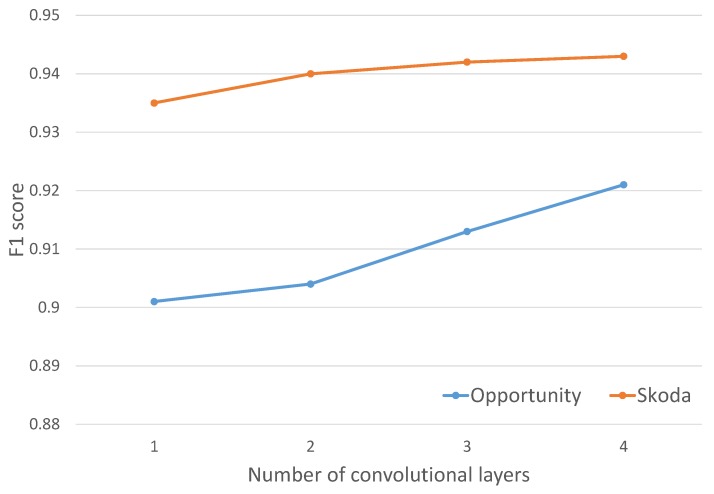
Similar articles
-
Feature Representation and Data Augmentation for Human Activity Classification Based on Wearable IMU Sensor Data Using a Deep LSTM Neural Network.Sensors (Basel). 2018 Aug 31;18(9):2892. doi: 10.3390/s18092892. Sensors (Basel). 2018. PMID: 30200377 Free PMC article.
-
LSTM Networks Using Smartphone Data for Sensor-Based Human Activity Recognition in Smart Homes.Sensors (Basel). 2021 Feb 26;21(5):1636. doi: 10.3390/s21051636. Sensors (Basel). 2021. PMID: 33652697 Free PMC article.
-
Comparison of Feature Learning Methods for Human Activity Recognition Using Wearable Sensors.Sensors (Basel). 2018 Feb 24;18(2):679. doi: 10.3390/s18020679. Sensors (Basel). 2018. PMID: 29495310 Free PMC article.
-
Deep Learning for Human Activity Recognition on 3D Human Skeleton: Survey and Comparative Study.Sensors (Basel). 2023 May 27;23(11):5121. doi: 10.3390/s23115121. Sensors (Basel). 2023. PMID: 37299848 Free PMC article. Review.
-
Deep Learning to Predict Falls in Older Adults Based on Daily-Life Trunk Accelerometry.Sensors (Basel). 2018 May 22;18(5):1654. doi: 10.3390/s18051654. Sensors (Basel). 2018. PMID: 29786659 Free PMC article. Review.
Cited by
-
A deep learning model based on whole slide images to predict disease-free survival in cutaneous melanoma patients.Sci Rep. 2022 Nov 27;12(1):20366. doi: 10.1038/s41598-022-24315-1. Sci Rep. 2022. PMID: 36437296 Free PMC article.
-
LARa: Creating a Dataset for Human Activity Recognition in Logistics Using Semantic Attributes.Sensors (Basel). 2020 Jul 22;20(15):4083. doi: 10.3390/s20154083. Sensors (Basel). 2020. PMID: 32707928 Free PMC article.
-
Multi-Modal Deep Learning for Assessing Surgeon Technical Skill.Sensors (Basel). 2022 Sep 27;22(19):7328. doi: 10.3390/s22197328. Sensors (Basel). 2022. PMID: 36236424 Free PMC article.
-
Smartphone-Based Activity Recognition in a Pedestrian Navigation Context.Sensors (Basel). 2021 May 7;21(9):3243. doi: 10.3390/s21093243. Sensors (Basel). 2021. PMID: 34067137 Free PMC article.
-
Cross-Domain Human Activity Recognition Using Low-Resolution Infrared Sensors.Sensors (Basel). 2024 Oct 2;24(19):6388. doi: 10.3390/s24196388. Sensors (Basel). 2024. PMID: 39409429 Free PMC article.
References
-
- Rashidi P., Cook D.J. The resident in the loop: Adapting the smart home to the user. IEEE Trans. Syst. Man. Cybern. J. Part A. 2009;39:949–959. doi: 10.1109/TSMCA.2009.2025137. - DOI
-
- Avci A., Bosch S., Marin-Perianu M., Marin-Perianu R., Havinga P. Activity Recognition Using Inertial Sensing for Healthcare, Wellbeing and Sports Applications: A Survey; Proceedings of the 23rd International Conference on Architecture of Computing Systems (ARCS); Hannover, Germany. 22–23 Febuary 2010; pp. 1–10.
-
- Mazilu S., Blanke U., Hardegger M., Tröster G., Gazit E., Hausdorff J.M. GaitAssist: A Daily-Life Support and Training System for Parkinson’s Disease Patients with Freezing of Gait; Proceedings of the ACM Conference on Human Factors in Computing Systems (SIGCHI); Toronto, ON, Canada. 26 April–1 May 2014.
-
- Kranz M., Möller A., Hammerla N., Diewald S., Plötz T., Olivier P., Roalter L. The mobile fitness coach: Towards individualized skill assessment using personalized mobile devices. Perv. Mob. Comput. 2013;9:203–215. doi: 10.1016/j.pmcj.2012.06.002. - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
