

Learning to Produce Syllabic Speech Sounds via Reward-Modulated Neural Plasticity
- PMID: 26808148
- PMCID: PMC4726623
- DOI: 10.1371/journal.pone.0145096
Learning to Produce Syllabic Speech Sounds via Reward-Modulated Neural Plasticity
Abstract
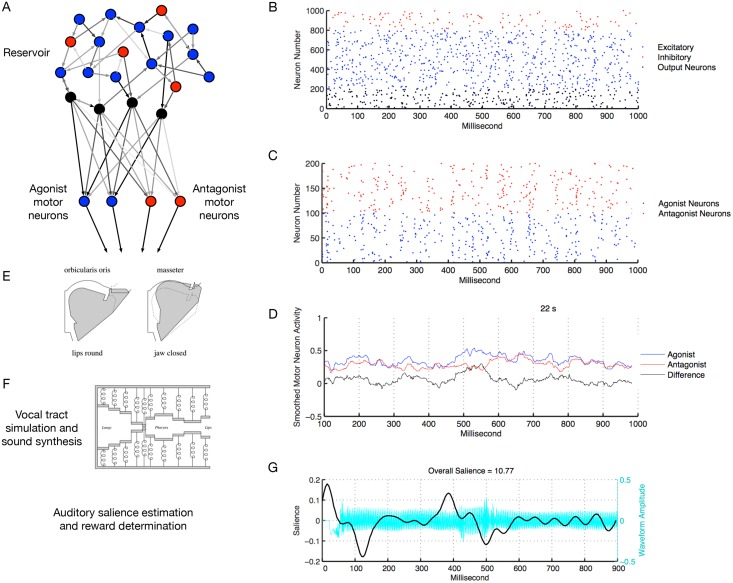
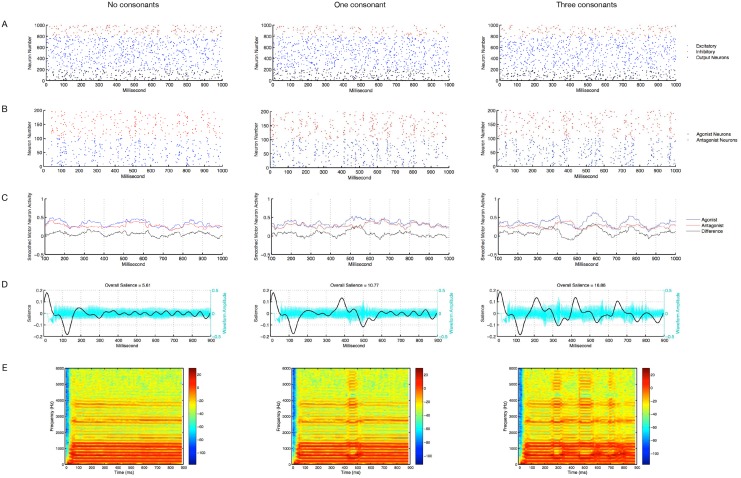
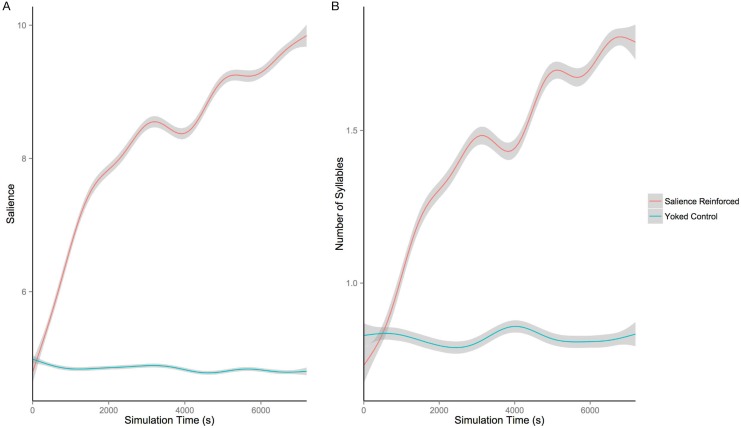
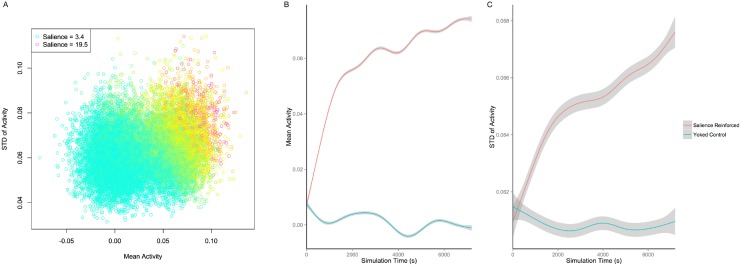
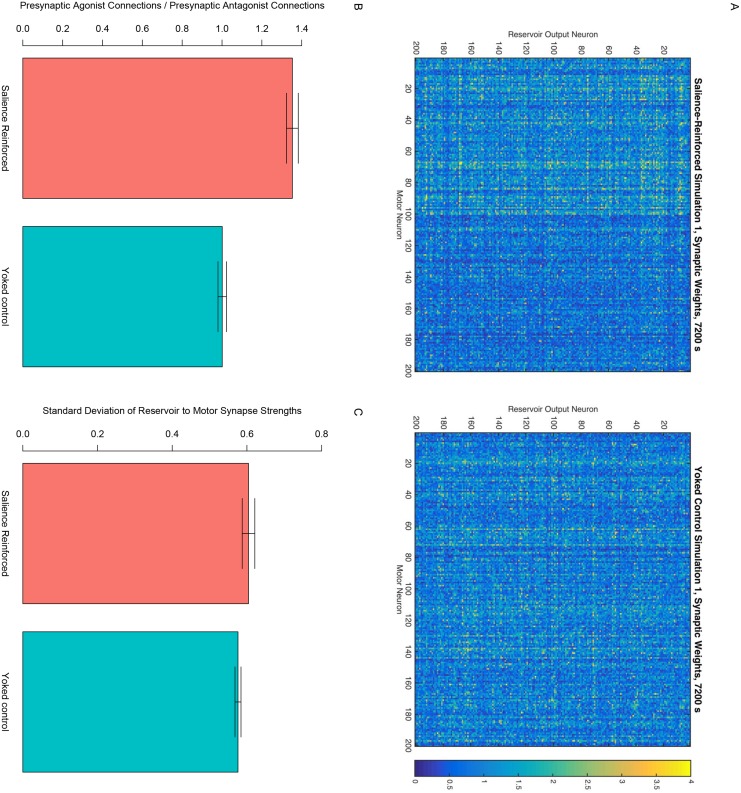
At around 7 months of age, human infants begin to reliably produce well-formed syllables containing both consonants and vowels, a behavior called canonical babbling. Over subsequent months, the frequency of canonical babbling continues to increase. How the infant's nervous system supports the acquisition of this ability is unknown. Here we present a computational model that combines a spiking neural network, reinforcement-modulated spike-timing-dependent plasticity, and a human-like vocal tract to simulate the acquisition of canonical babbling. Like human infants, the model's frequency of canonical babbling gradually increases. The model is rewarded when it produces a sound that is more auditorily salient than sounds it has previously produced. This is consistent with data from human infants indicating that contingent adult responses shape infant behavior and with data from deaf and tracheostomized infants indicating that hearing, including hearing one's own vocalizations, is critical for canonical babbling development. Reward receipt increases the level of dopamine in the neural network. The neural network contains a reservoir with recurrent connections and two motor neuron groups, one agonist and one antagonist, which control the masseter and orbicularis oris muscles, promoting or inhibiting mouth closure. The model learns to increase the number of salient, syllabic sounds it produces by adjusting the base level of muscle activation and increasing their range of activity. Our results support the possibility that through dopamine-modulated spike-timing-dependent plasticity, the motor cortex learns to harness its natural oscillations in activity in order to produce syllabic sounds. It thus suggests that learning to produce rhythmic mouth movements for speech production may be supported by general cortical learning mechanisms. The model makes several testable predictions and has implications for our understanding not only of how syllabic vocalizations develop in infancy but also for our understanding of how they may have evolved.
Conflict of interest statement
Figures
Similar articles
-
Prespeech motor learning in a neural network using reinforcement.Neural Netw. 2013 Feb;38:64-75. doi: 10.1016/j.neunet.2012.11.012. Epub 2012 Dec 3. Neural Netw. 2013. PMID: 23275137 Free PMC article.
-
Reinforcement learning of targeted movement in a spiking neuronal model of motor cortex.PLoS One. 2012;7(10):e47251. doi: 10.1371/journal.pone.0047251. Epub 2012 Oct 19. PLoS One. 2012. PMID: 23094042 Free PMC article.
-
A new model of sensorimotor coupling in the development of speech.Brain Lang. 2004 May;89(2):393-400. doi: 10.1016/S0093-934X(03)00345-6. Brain Lang. 2004. PMID: 15068923
-
Precursors to speech in infancy: the prediction of speech and language disorders.J Commun Disord. 1999 Jul-Aug;32(4):223-45. doi: 10.1016/s0021-9924(99)00013-1. J Commun Disord. 1999. PMID: 10466095 Review.
-
Neuromotor speech impairment: it's all in the talking.Folia Phoniatr Logop. 2013;65(2):55-67. doi: 10.1159/000353855. Epub 2013 Aug 12. Folia Phoniatr Logop. 2013. PMID: 23942013 Review.
Cited by
-
Generative Adversarial Phonology: Modeling Unsupervised Phonetic and Phonological Learning With Neural Networks.Front Artif Intell. 2020 Jul 8;3:44. doi: 10.3389/frai.2020.00044. eCollection 2020. Front Artif Intell. 2020. PMID: 33733161 Free PMC article.
-
Brain-inspired model for early vocal learning and correspondence matching using free-energy optimization.PLoS Comput Biol. 2021 Feb 18;17(2):e1008566. doi: 10.1371/journal.pcbi.1008566. eCollection 2021 Feb. PLoS Comput Biol. 2021. PMID: 33600482 Free PMC article.
-
The Social Feedback Hypothesis and Communicative Development in Autism Spectrum Disorder: A Response to Akhtar, Jaswal, Dinishak, and Stephan (2016).Psychol Sci. 2016 Nov;27(11):1531-1533. doi: 10.1177/0956797616668558. Epub 2016 Sep 23. Psychol Sci. 2016. PMID: 27664191 Free PMC article. No abstract available.
-
The social functions of babbling: acoustic and contextual characteristics that facilitate maternal responsiveness.Dev Sci. 2018 Sep;21(5):e12641. doi: 10.1111/desc.12641. Epub 2017 Dec 17. Dev Sci. 2018. PMID: 29250872 Free PMC article.
-
The relationship between nighttime exercise and problematic smartphone use before sleep and associated health issues: a cross-sectional study.BMC Public Health. 2024 Feb 23;24(1):590. doi: 10.1186/s12889-024-18100-0. BMC Public Health. 2024. PMID: 38395834 Free PMC article.
References
-
- Oller DK. The emergence of the sounds of speech in infancy In: Yeni-Komshian GH, Kavanagh JF, Ferguson CA, editors. Child phonology, vol. 1: Production. New York: Academic Press; 1980. p. 93–112.
-
- Stark RE. Stages of speech development in the first year of life In: Yeni-Komshian GH, Kavanagh JF, Ferguson CA, editors. Child phonology, vol. 1: Production. New York: Academic Press; 1980. p. 73–92.
-
- Koomans-van Beinum FJ, van der Stelt JM. Early stages in the development of speech movements In: Lindblom B, Zetterström R, editors. Precursors of early speech. New York: Stockton Press; 1986. p. 37–50.
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
