

Distribution and Features of the Six Classes of Peroxiredoxins
- PMID: 26810075
- PMCID: PMC4749874
- DOI: 10.14348/molcells.2016.2330
Distribution and Features of the Six Classes of Peroxiredoxins
Abstract
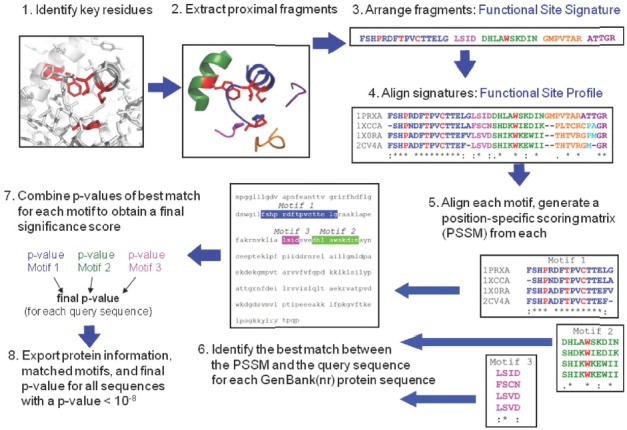
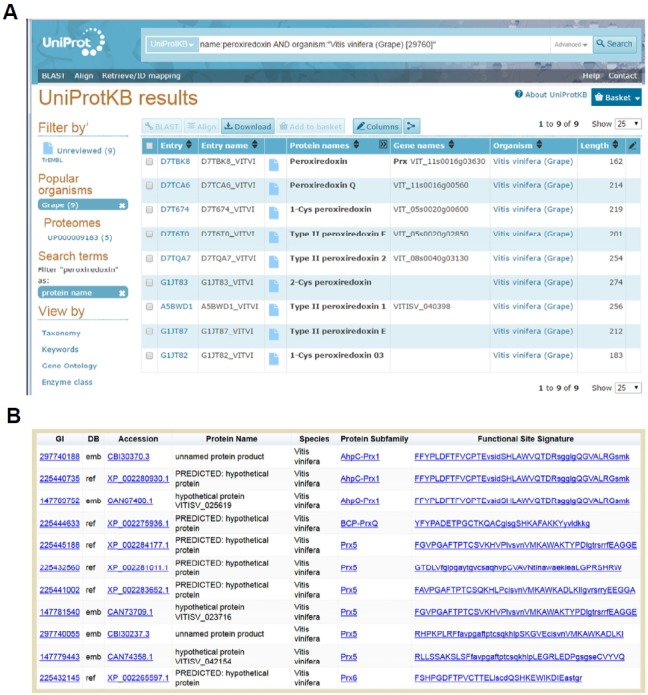
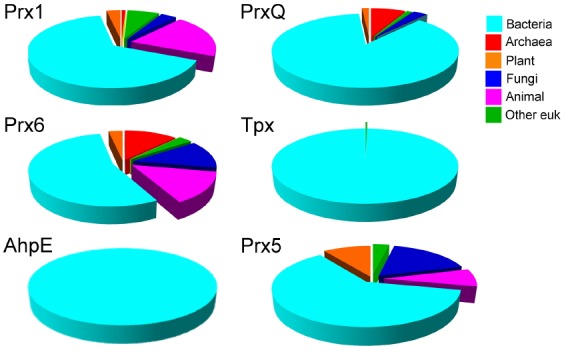
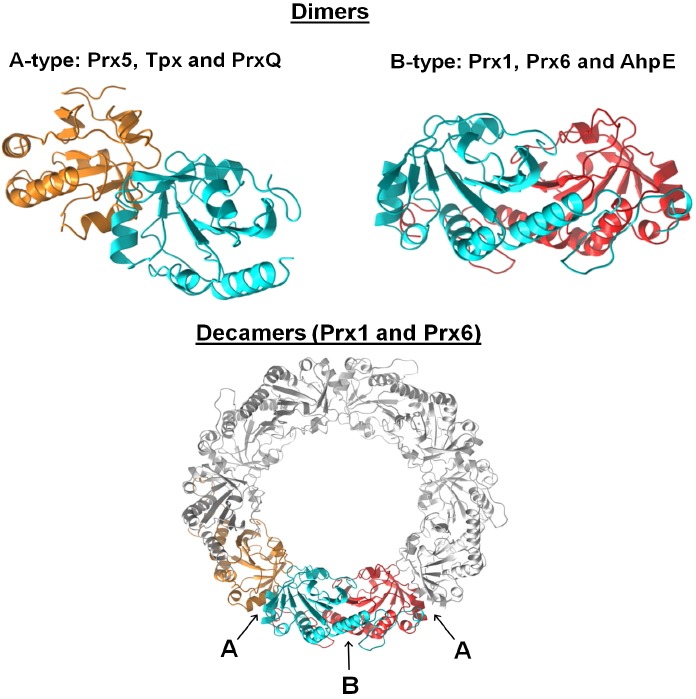
Peroxiredoxins are cysteine-dependent peroxide reductases that group into 6 different, structurally discernable classes. In 2011, our research team reported the application of a bioinformatic approach called active site profiling to extract active site-proximal sequence segments from the 29 distinct, structurally-characterized peroxiredoxins available at the time. These extracted sequences were then used to create unique profiles for the six groups which were subsequently used to search GenBank(nr), allowing identification of ∼3500 peroxiredoxin sequences and their respective subgroups. Summarized in this minireview are the features and phylogenetic distributions of each of these peroxiredoxin subgroups; an example is also provided illustrating the use of the web accessible, searchable database known as PREX to identify subfamily-specific peroxiredoxin sequences for the organism Vitis vinifera (grape).
Keywords: active site profiling; bioinformatics; disulfide reductase; peroxide reductase; thiol peroxidase.
Figures

Similar articles
-
Overview on Peroxiredoxin.Mol Cells. 2016 Jan;39(1):1-5. doi: 10.14348/molcells.2016.2368. Mol Cells. 2016. PMID: 26831451 Free PMC article. Review.
-
PREX: PeroxiRedoxin classification indEX, a database of subfamily assignments across the diverse peroxiredoxin family.Nucleic Acids Res. 2011 Jan;39(Database issue):D332-7. doi: 10.1093/nar/gkq1060. Epub 2010 Oct 29. Nucleic Acids Res. 2011. PMID: 21036863 Free PMC article.
-
An Atlas of Peroxiredoxins Created Using an Active Site Profile-Based Approach to Functionally Relevant Clustering of Proteins.PLoS Comput Biol. 2017 Feb 10;13(2):e1005284. doi: 10.1371/journal.pcbi.1005284. eCollection 2017 Feb. PLoS Comput Biol. 2017. PMID: 28187133 Free PMC article.
-
Phylogenetic analysis of cnidarian peroxiredoxins and stress-responsive expression in the estuarine sea anemone Nematostella vectensis.Comp Biochem Physiol A Mol Integr Physiol. 2018 Jul;221:32-43. doi: 10.1016/j.cbpa.2018.03.009. Epub 2018 Mar 19. Comp Biochem Physiol A Mol Integr Physiol. 2018. PMID: 29567405
-
The plant multigenic family of thiol peroxidases.Free Radic Biol Med. 2005 Jun 1;38(11):1413-21. doi: 10.1016/j.freeradbiomed.2004.07.037. Free Radic Biol Med. 2005. PMID: 15890615 Review.
Cited by
-
Unraveling the Peroxidase Activity in Peroxiredoxins: A Comprehensive Review of Mechanisms, Functions, and Biological Significance.Cureus. 2024 Aug 4;16(8):e66117. doi: 10.7759/cureus.66117. eCollection 2024 Aug. Cureus. 2024. PMID: 39229430 Free PMC article. Review.
-
Oxidants in Physiological Processes.Handb Exp Pharmacol. 2021;264:27-47. doi: 10.1007/164_2020_380. Handb Exp Pharmacol. 2021. PMID: 32767144 Review.
-
The BCAT1 CXXC Motif Provides Protection against ROS in Acute Myeloid Leukaemia Cells.Antioxidants (Basel). 2022 Mar 31;11(4):683. doi: 10.3390/antiox11040683. Antioxidants (Basel). 2022. PMID: 35453368 Free PMC article.
-
Evolution and function of the Mycoplasma hyopneumoniae peroxiredoxin, a 2-Cys-like enzyme with a single Cys residue.Mol Genet Genomics. 2017 Apr;292(2):297-305. doi: 10.1007/s00438-016-1272-2. Epub 2016 Nov 17. Mol Genet Genomics. 2017. PMID: 27858147
-
Overview on Peroxiredoxin.Mol Cells. 2016 Jan;39(1):1-5. doi: 10.14348/molcells.2016.2368. Mol Cells. 2016. PMID: 26831451 Free PMC article. Review.
References
-
- Bailey T.L., Gribskov M. Combining evidence using p-values: application to sequence homology searches. Bioinformatics. 1998a;14:48–54. - PubMed
-
- Bailey T.L., Gribskov M. Methods and statistics for combining motif match scores. J. Comput. Biol. 1998b;5:211–221. - PubMed
-
- Barranco-Medina S., Kakorin S., Lazaro J.J., Dietz K.J. Thermodynamics of the dimer-decamer transition of reduced human and plant 2-cys peroxiredoxin. Biochemistry. 2008;47:7196–7204. - PubMed
-
- Cammer S.A., Hoffman B.T., Speir J.A., Canady M.A., Nelson M.R., Knutson S., Gallina M., Baxter S.M., Fetrow J.S. Structure-based active site profiles for genome analysis and functional family subclassification. J. Mol. Biol. 2003;334:387–401. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
