

Coalescent Inference Using Serially Sampled, High-Throughput Sequencing Data from Intrahost HIV Infection
- PMID: 26857628
- PMCID: PMC4905535
- DOI: 10.1534/genetics.115.177931
Coalescent Inference Using Serially Sampled, High-Throughput Sequencing Data from Intrahost HIV Infection
Abstract
Human immunodeficiency virus (HIV) is a rapidly evolving pathogen that causes chronic infections, so genetic diversity within a single infection can be very high. High-throughput "deep" sequencing can now measure this diversity in unprecedented detail, particularly since it can be performed at different time points during an infection, and this offers a potentially powerful way to infer the evolutionary dynamics of the intrahost viral population. However, population genomic inference from HIV sequence data is challenging because of high rates of mutation and recombination, rapid demographic changes, and ongoing selective pressures. In this article we develop a new method for inference using HIV deep sequencing data, using an approach based on importance sampling of ancestral recombination graphs under a multilocus coalescent model. The approach further extends recent progress in the approximation of so-called conditional sampling distributions, a quantity of key interest when approximating coalescent likelihoods. The chief novelties of our method are that it is able to infer rates of recombination and mutation, as well as the effective population size, while handling sampling over different time points and missing data without extra computational difficulty. We apply our method to a data set of HIV-1, in which several hundred sequences were obtained from an infected individual at seven time points over 2 years. We find mutation rate and effective population size estimates to be comparable to those produced by the software BEAST. Additionally, our method is able to produce local recombination rate estimates. The software underlying our method, Coalescenator, is freely available.
Keywords: HIV evolution; coalescent; conditional sampling distribution; importance sampling; recombination.
Copyright © 2016 by the Genetics Society of America.
Figures

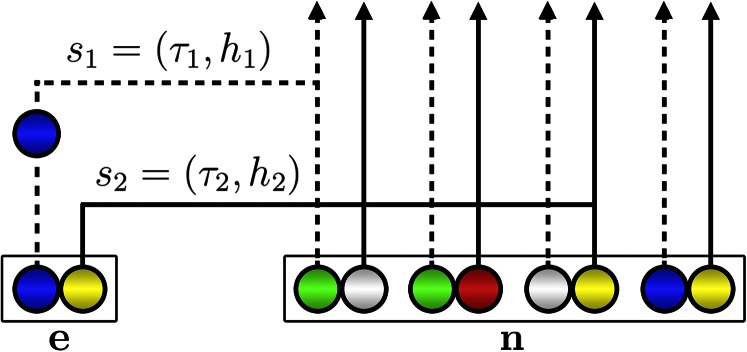


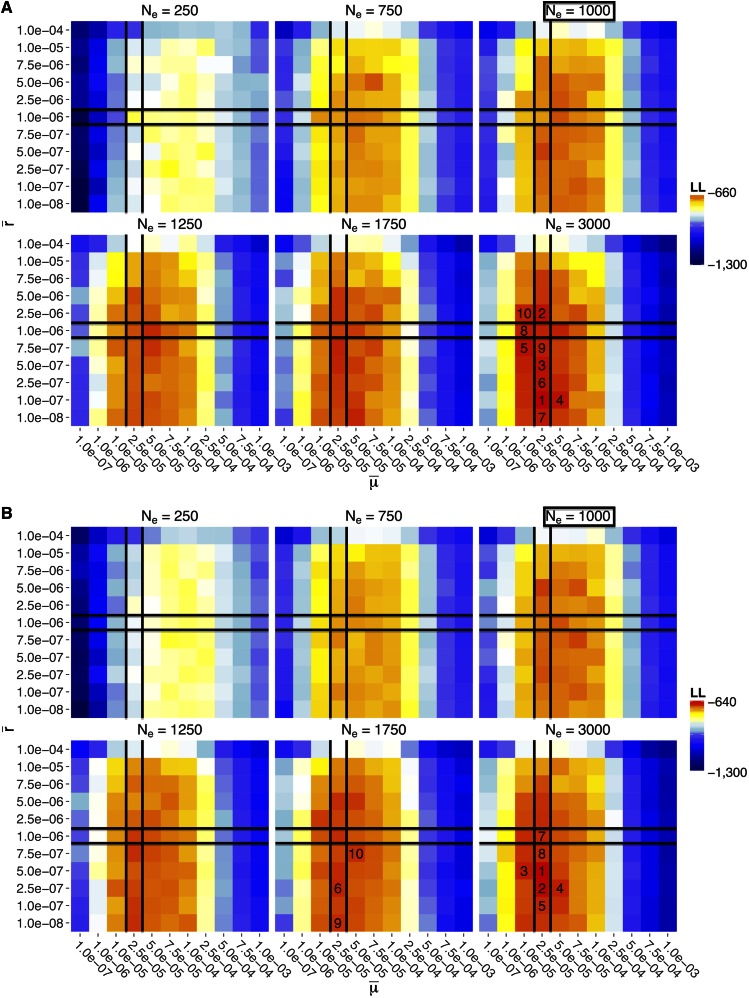






References
-
- Abramowitz, M., and I. Stegun (Editors), 1972 Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables (National Bureau of Standards Applied Mathematics Series, Ed. 10, Vol. 55). Dover Publications, New York, USA.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
