

Review
doi: 10.1038/nrn.2015.26.
Epub 2016 Feb 11.
Dopamine reward prediction-error signalling: a two-component response
Affiliations
- PMID: 26865020
- PMCID: PMC5549862
- DOI: 10.1038/nrn.2015.26
Item in Clipboard
Review
Dopamine reward prediction-error signalling: a two-component response
Nat Rev Neurosci.
2016 Mar.
Abstract
Environmental stimuli and objects, including rewards, are often processed sequentially in the brain. Recent work suggests that the phasic dopamine reward prediction-error response follows a similar sequential pattern. An initial brief, unselective and highly sensitive increase in activity unspecifically detects a wide range of environmental stimuli, then quickly evolves into the main response component, which reflects subjective reward value and utility. This temporal evolution allows the dopamine reward prediction-error signal to optimally combine speed and accuracy.
Conflict of interest statement
The author declares no competing interests.
Figures

A reward is composed of sensory and value-related components. The sensory components have an impact on sensory receptors and neurons, and drive initial sensory processing that detects and subsequently identifies the reward. Reward value, which specifically reflects the positively motivating function of rewards, is processed only after the object has been identified. Value does not primarily reflect physical parameters but rather the brain’s subjective assessment of the usefulness of the reward for survival and reproduction. These sequential processes result in decisions and actions, and drive reinforcement as a result of the experienced outcome. For further details, see REF. .

a | Sequential processing in a cognitive system. The graph shows the time course of target discrimination in a monkey frontal eye field neuron during attentional selection. The animal’s task was to distinguish between a target stimulus and a distractor. The neuron initially detects both stimuli indiscriminately (blue zone); only later does its response differentiate between the stimuli (red zone). b | Sequential dopamine processing of reward. The graph shows distinct, sequential components of the dopamine prediction-error response to conditioned stimuli predicting either non-reward or reward delivery. These responses reflect initial transient object detection, which is indiscriminate, and subsequent reward identification and valuation, which distinguishes between reward and no reward prediction. c | The components of the dopamine prediction-error response in part b that relate to detection and valuation can be distinguished by statistics. The partial beta (slope) coefficients of the double linear regression on physical intensity and reward value show distinct time courses, indicating the dynamic evolution from initial detection to subsequent valuation. d | Voltammetric dopamine responses in rat nucleus accumbens distinguish between a reward-predicting conditioned stimulus (CS+) and a non-reward-predicting conditioned stimulus (CS−). Again, the dopamine release comprises an initial indiscriminate detection component and a subsequent identification and value component. e | A more demanding random dot motion discrimination task reveals completely separated dopamine response components. Increasing motion coherence (MC) results in more accurate motion discrimination and thus higher reward probability (p). The initial, stereotyped, non-differential activation reflects stimulus detection and decreases back to baseline (blue zone); the subsequent separate, graded increase develops when the animal signals stimulus discrimination; it codes reward value (red zone), which in this case derives from reward probability,. [DA], dopamine concentration. Part a is adapted, with permission, from REF. , Proceedings of the National Academy of Sciences. Part b is adapted from REF. , republished with permission of Society for Neuroscience, from Coding of predicted reward omission by dopamine neurons in a conditioned inhibition paradigm, Tobler, P. N., Dickinson, A. & Schultz, W., 23 (32), 2003; permission conveyed through Copyright Clearance Center, Inc. Part c is adapted from REF. , republished with permission of Society for Neuroscience, from Multiphasic temporal dynamics in responses of midbrain dopamine neurons to appetitive and aversive stimuli, Fiorillo, C. D., Song, M. R. & Yun, S. R., 33 (11), 2013; permission conveyed through Copyright Clearance Center, Inc. Part d is from REF. , Nature Publishing Group. Part e is adapted from REF. , republished with permission of Society for Neuroscience, from Temporally extended dopamine responses to perceptually demanding reward-predictive stimuli, Nomoto, K., Schultz, W., Watanabe, T. & Sakagami, M., 30 (32), 2010; permission conveyed through Copyright Clearance Center, Inc.

a | Influence of physical intensity. In the example shown, stronger (yet non-aversive) sounds generate higher initial dopamine responses than weaker sounds. b | Influence of reward context. The left graph shows dopamine responses to the presentation of either a reward or one of two unrewarded pictures of different sizes in an experiment in which the contexts in which each is presented are distinct. The right graph shows that the dopamine neuron responses to the pictures are much more substantial when they are presented in the same context as the reward (that is, when the presentations occur in one common trial block with a common background picture and when the liquid spout is always present). c | Influence of reward generalization between stimuli that share physical characteristics. In the example shown, a conditioned visual aversive stimulus activates 16% of dopamine neurons when it is pseudorandomly interspersed with an auditory reward-predicting stimulus. However, the same visual aversive stimulus activates 65% of dopamine neurons when the alternating reward-predicting stimulus is also visual. d | Influence of stimulus novelty. The graph shows activity in a single dopamine neuron during an experiment in which an animal is repeatedly presented with a novel, unrewarded stimulus (rapid vertical opening of the door of an empty box). Dots representing action potentials are plotted in sequential trials from top down. Activation was substantial in the first ten trials. However, 60 trials later, the same dopamine neuron shows a diminished response. Horizontal eye movement traces displayed above and below the neuronal rasters illustrate the change in behaviour that correlates with decreasing novelty (less eye movement towards the stimulus; y-axis represents eye position to the right). Part a is adapted from REF. , republished with permission of Society for Neuroscience, from Multiphasic temporal dynamics in responses of midbrain dopamine neurons to appetitive and aversive stimuli, Fiorillo, C. D., Song, M. R. & Yun, S. R., 33 (11), 2013; permission conveyed through Copyright Clearance Center, Inc. Part b is adapted with permission from REF. , Elsevier. Part c is from REF. , Nature Publishing Group. Part d is adapted with permission from REF. , American Physiological Society.
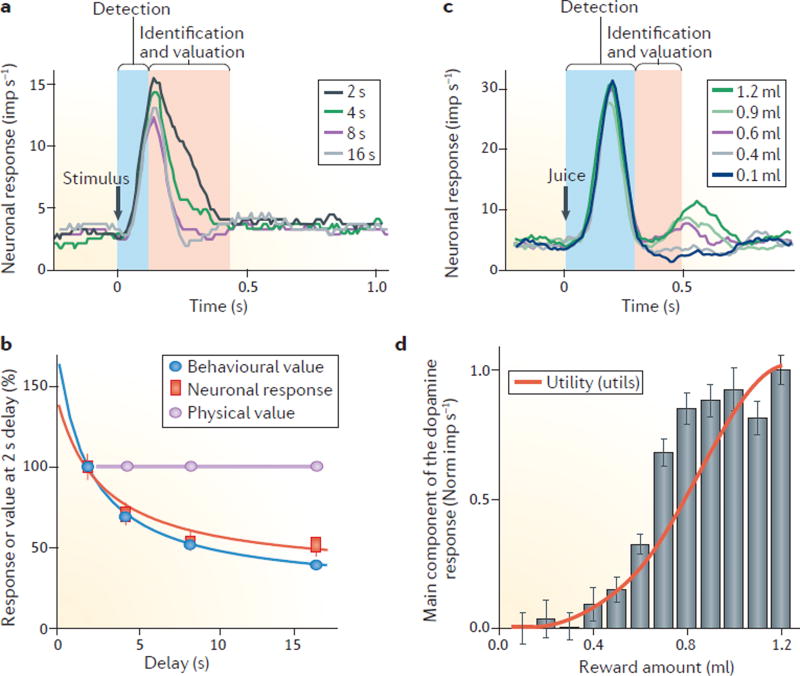
a | Temporal discounting of a reward’s subjective value is reflected in the dopamine response. The figure shows the averaged activity from 54 dopamine neurons responding to 4 stimuli predicting the same amount of a reward that is delivered after delays of 2, 4, 8 or 16 seconds. The stimulus response is reduced as the delay before receiving the reward increases, suggesting that the value coding by these neurons is subjective and decreases with the delay after which the reward is delivered. The value-related response decrement occurs primarily in the later, main response component (red zone). b | Corresponding temporal discounting in both the behavioural response and the main dopamine response component reveals subjective value coding. c | Monotonic increase of the main dopamine response component (red zone) when an animal is provided with an increasing amount of an unpredicted juice reward. By contrast, the initial response component (blue zone) is unselective and reflects only the detection of juice flow onset. d | The dopamine reward prediction-error signal codes formal economic utility. For the experiment described in c, the red line shows the utility function as estimated from behavioural choices. The grey bars show a nonlinear increase in the main component of the dopamine response (red zone in c) to juice reward, reflecting the positive prediction error generated by its unpredicted delivery. Parts a and b are adapted from REF. , republished with permission of Society for Neuroscience, from Influence of reward delays on responses of dopamine neurons, Kobayashi, S. & Schultz, W., 28 (31), 2008; permission conveyed through Copyright Clearance Center, Inc. Parts c and d are adapted with permission from REF. , Elsevier.

The reward prediction error signalled by the main dopamine response component following a conditioned stimulus remains present until the time of reward. a | The graphs illustrate persistent reward representation in a random dot motion discrimination task in which distinct dopamine response components can initially be observed (blue and red zones). The reward prediction-error response subsequently decreases in a manner that correlates with increasing reward probability (right), suggesting that a neuronal representation of reward value persists after the onset of the value response component of the dopamine response. b | Schematics showing how an accurate reward-value representation may persist until the reward is received. As shown in the top panel, after a rewarded stimulus generates a detection response that develops into a full reward-value activation, reward delivery, which induces no prediction error (no PE), elicits no dopamine response; by contrast, reward omission, generating a negative prediction error (−PE), induces a dopamine depression. However, as shown at in the bottom panel, after an unrewarded stimulus generates a detection response that develops into a dopamine depression, a surprising reward elicits a positive prediction error (+PE) and dopamine activation, whereas no reward fails to generate a prediction error and dopamine response. Thus, the dopamine responses at the time of reward probe the reward prediction that exists at that moment. This proposed mechanism expands on previous suggestions that have not taken into account the two dopamine response components,. Part a is adapted from REF. , republished with permission of Society for Neuroscience, from Temporally extended dopamine responses to perceptually demanding reward-predictive stimuli, Nomoto, K., Schultz, W., Watanabe, T. & Sakagami, M. 30 (32), 2010; permission conveyed through Copyright Clearance Center, Inc.


References
-
- Schultz W. Multiple dopamine functions at different time courses. Ann. Rev. Neurosci. 2007;30:259–288. - PubMed
-
- Ljungberg T, Apicella P, Schultz W. Responses of monkey dopamine neurons during learning of behavioral reactions. J. Neurophysiol. 1992;67:145–163. - PubMed
-
- Schultz W, Dayan P, Montague RR. A neural substrate of prediction and reward. Science. 1997;275:1593–1599. - PubMed
-
- Schultz W. Predictive reward signal of dopamine neurons. J. Neurophysiol. 1998;80:1–27. - PubMed
-
- Waelti P, Dickinson A, Schultz W. Dopamine responses comply with basic assumptions of formal learning theory. Nature. 2001;412:43–48. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
