

Reinforcement Learning Trees
- PMID: 26903687
- PMCID: PMC4760114
- DOI: 10.1080/01621459.2015.1036994
Reinforcement Learning Trees
Abstract
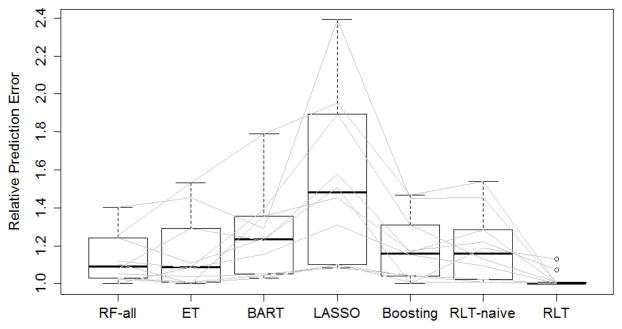
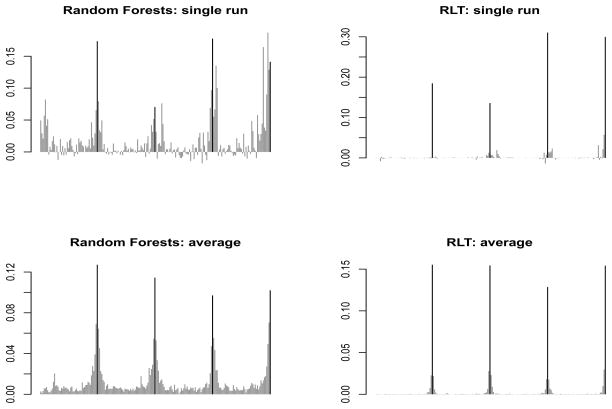
In this paper, we introduce a new type of tree-based method, reinforcement learning trees (RLT), which exhibits significantly improved performance over traditional methods such as random forests (Breiman, 2001) under high-dimensional settings. The innovations are three-fold. First, the new method implements reinforcement learning at each selection of a splitting variable during the tree construction processes. By splitting on the variable that brings the greatest future improvement in later splits, rather than choosing the one with largest marginal effect from the immediate split, the constructed tree utilizes the available samples in a more efficient way. Moreover, such an approach enables linear combination cuts at little extra computational cost. Second, we propose a variable muting procedure that progressively eliminates noise variables during the construction of each individual tree. The muting procedure also takes advantage of reinforcement learning and prevents noise variables from being considered in the search for splitting rules, so that towards terminal nodes, where the sample size is small, the splitting rules are still constructed from only strong variables. Last, we investigate asymptotic properties of the proposed method under basic assumptions and discuss rationale in general settings.
Keywords: Consistency; Error Bound; Random Forests; Reinforcement Learning; Trees.
Figures
References
-
- Amit Y, Geman D. Shape quantization and recognition with randomized trees. Neural Computing. 1997;9(7):1545–1588.
-
- Biau G. Analysis of a random forests model. Journal of Machine Learning Research. 2012;13:1063–1095.
-
- Biau G, Devroye L, Lugosi G. Consistency of random forests and other averaging classifiers. Journal of Machine Learning Research. 2008;9:2015–2033.
-
- Breiman L. Bagging Predictors. Machine Learning. 1996;24:123–140.
-
- Breiman L. Technical Report 577. Department of Statistics, University of California; Berkeley: 2000. Some infinity theory for predictor ensembles.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical