

Extracting information from the text of electronic medical records to improve case detection: a systematic review
- PMID: 26911811
- PMCID: PMC4997034
- DOI: 10.1093/jamia/ocv180
Extracting information from the text of electronic medical records to improve case detection: a systematic review
Abstract
Background: Electronic medical records (EMRs) are revolutionizing health-related research. One key issue for study quality is the accurate identification of patients with the condition of interest. Information in EMRs can be entered as structured codes or unstructured free text. The majority of research studies have used only coded parts of EMRs for case-detection, which may bias findings, miss cases, and reduce study quality. This review examines whether incorporating information from text into case-detection algorithms can improve research quality.
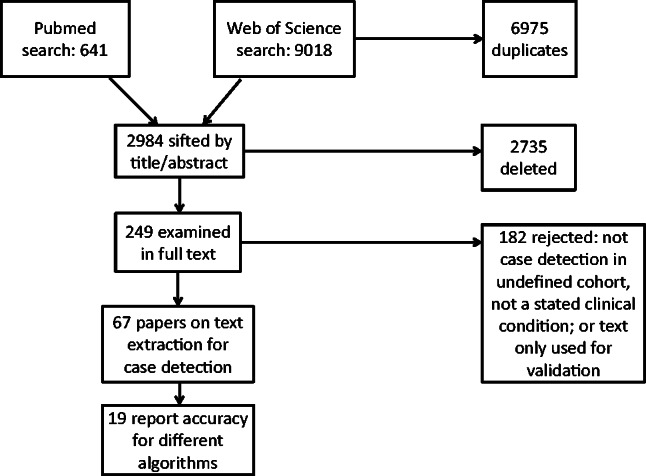
Methods: A systematic search returned 9659 papers, 67 of which reported on the extraction of information from free text of EMRs with the stated purpose of detecting cases of a named clinical condition. Methods for extracting information from text and the technical accuracy of case-detection algorithms were reviewed.
Results: Studies mainly used US hospital-based EMRs, and extracted information from text for 41 conditions using keyword searches, rule-based algorithms, and machine learning methods. There was no clear difference in case-detection algorithm accuracy between rule-based and machine learning methods of extraction. Inclusion of information from text resulted in a significant improvement in algorithm sensitivity and area under the receiver operating characteristic in comparison to codes alone (median sensitivity 78% (codes + text) vs 62% (codes), P = .03; median area under the receiver operating characteristic 95% (codes + text) vs 88% (codes), P = .025).
Conclusions: Text in EMRs is accessible, especially with open source information extraction algorithms, and significantly improves case detection when combined with codes. More harmonization of reporting within EMR studies is needed, particularly standardized reporting of algorithm accuracy metrics like positive predictive value (precision) and sensitivity (recall).
Keywords: case detection; data quality; electronic health records; review; text mining.
© The Author 2016. Published by Oxford University Press on behalf of the American Medical Informatics Association.
References
-
- World Health Organization. International statistical classification of diseases and related health problems 10th revision, edition 2010 . Geneva, Switzerland, 2010.
-
- International Health Terminology Standards Development Organisation (IHTSDO). SNOMED CT Starter Guide . Copenhagen, Denmark. Accessed from: www.snomed.org/starterguide.pdf . 2014 .
-
- Soler J-K, Okkes I, Wood M, Lamberts H . The coming of age of ICPC: celebrating the 21st birthday of the International Classification of Primary Care . Fam Pract. 2008. ; 25 ( 4 ): 312 – 317 . - PubMed
-
- Lovis C, Baud RH, Planche P . Power of expression in the electronic patient record: structured data or narrative text? Int J Med Inform. 2000. ; 58-59:101-110 . - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
