

S/HIC: Robust Identification of Soft and Hard Sweeps Using Machine Learning
- PMID: 26977894
- PMCID: PMC4792382
- DOI: 10.1371/journal.pgen.1005928
S/HIC: Robust Identification of Soft and Hard Sweeps Using Machine Learning
Abstract
Detecting the targets of adaptive natural selection from whole genome sequencing data is a central problem for population genetics. However, to date most methods have shown sub-optimal performance under realistic demographic scenarios. Moreover, over the past decade there has been a renewed interest in determining the importance of selection from standing variation in adaptation of natural populations, yet very few methods for inferring this model of adaptation at the genome scale have been introduced. Here we introduce a new method, S/HIC, which uses supervised machine learning to precisely infer the location of both hard and soft selective sweeps. We show that S/HIC has unrivaled accuracy for detecting sweeps under demographic histories that are relevant to human populations, and distinguishing sweeps from linked as well as neutrally evolving regions. Moreover, we show that S/HIC is uniquely robust among its competitors to model misspecification. Thus, even if the true demographic model of a population differs catastrophically from that specified by the user, S/HIC still retains impressive discriminatory power. Finally, we apply S/HIC to the case of resequencing data from human chromosome 18 in a European population sample, and demonstrate that we can reliably recover selective sweeps that have been identified earlier using less specific and sensitive methods.
Conflict of interest statement
The authors have declared that no competing interests exist.
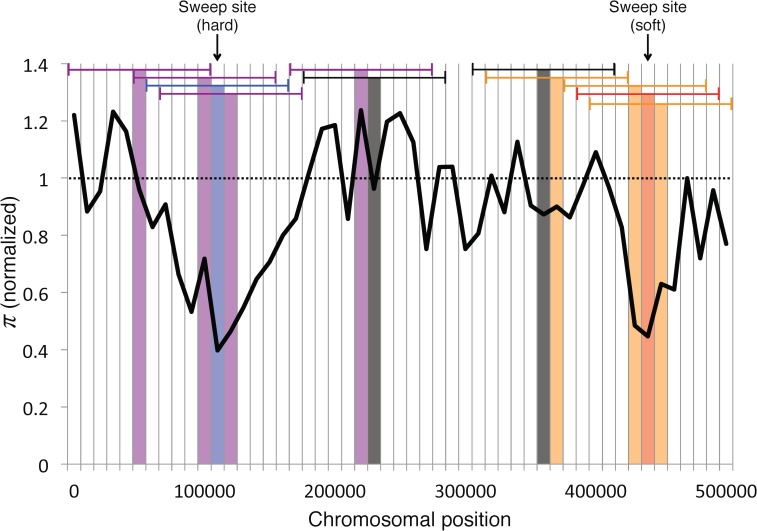
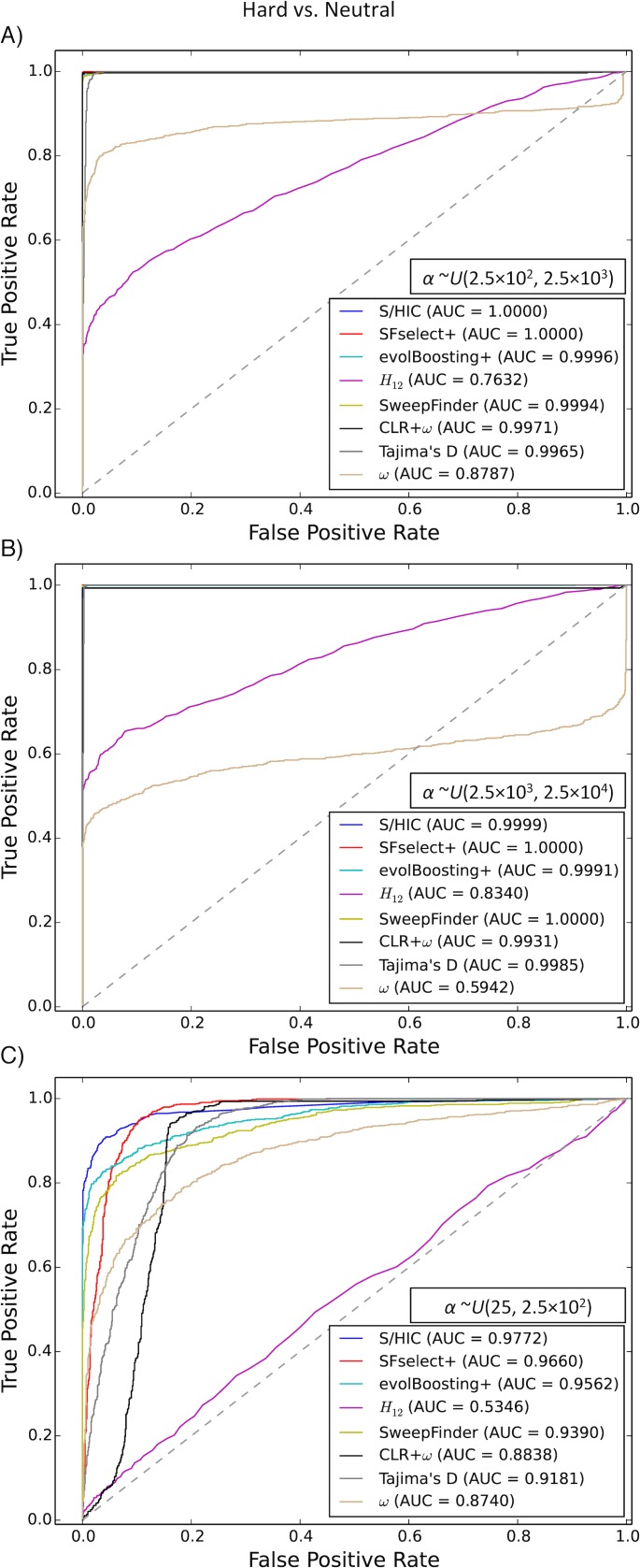
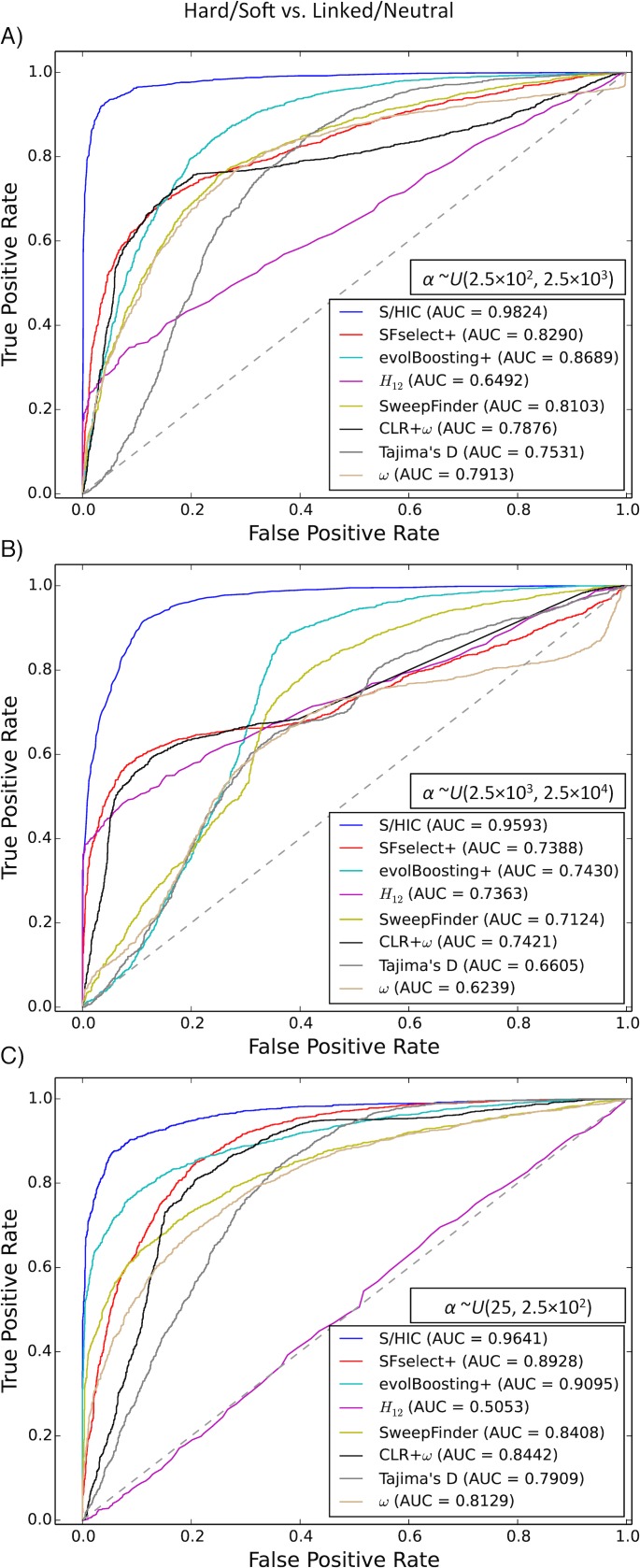
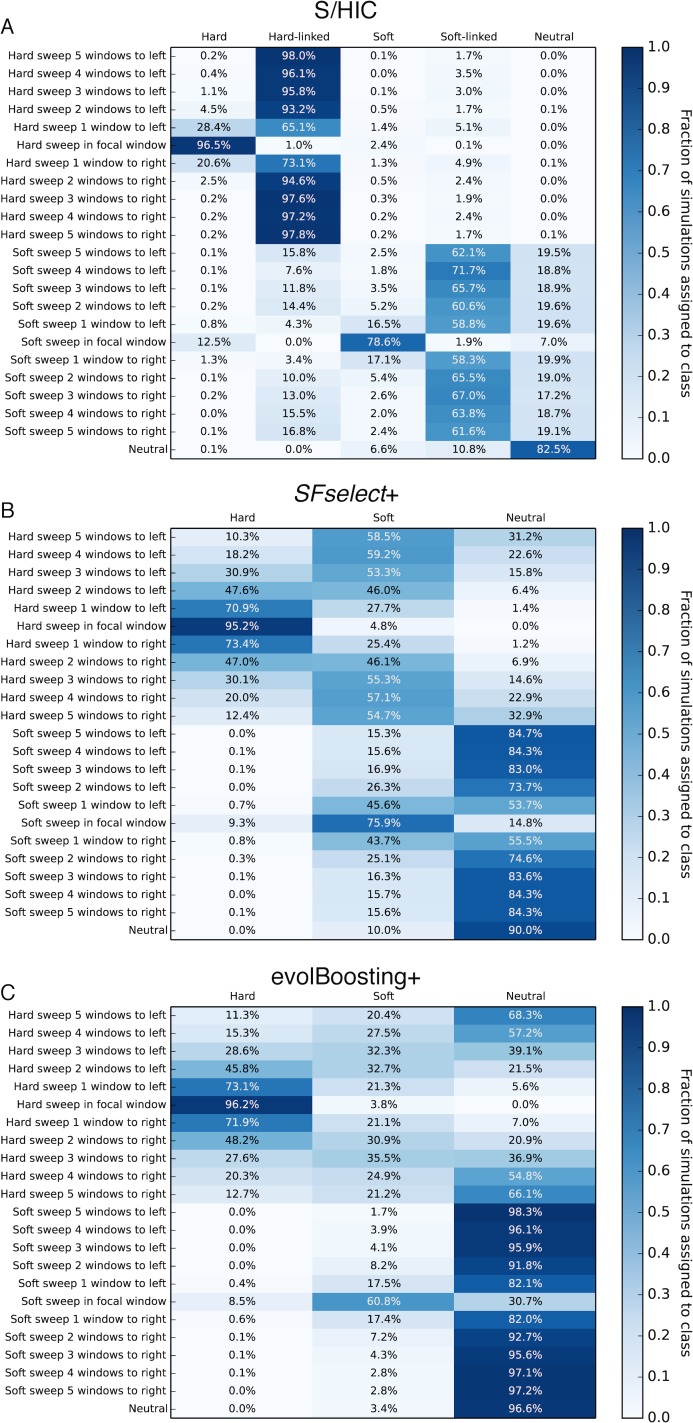
Figures
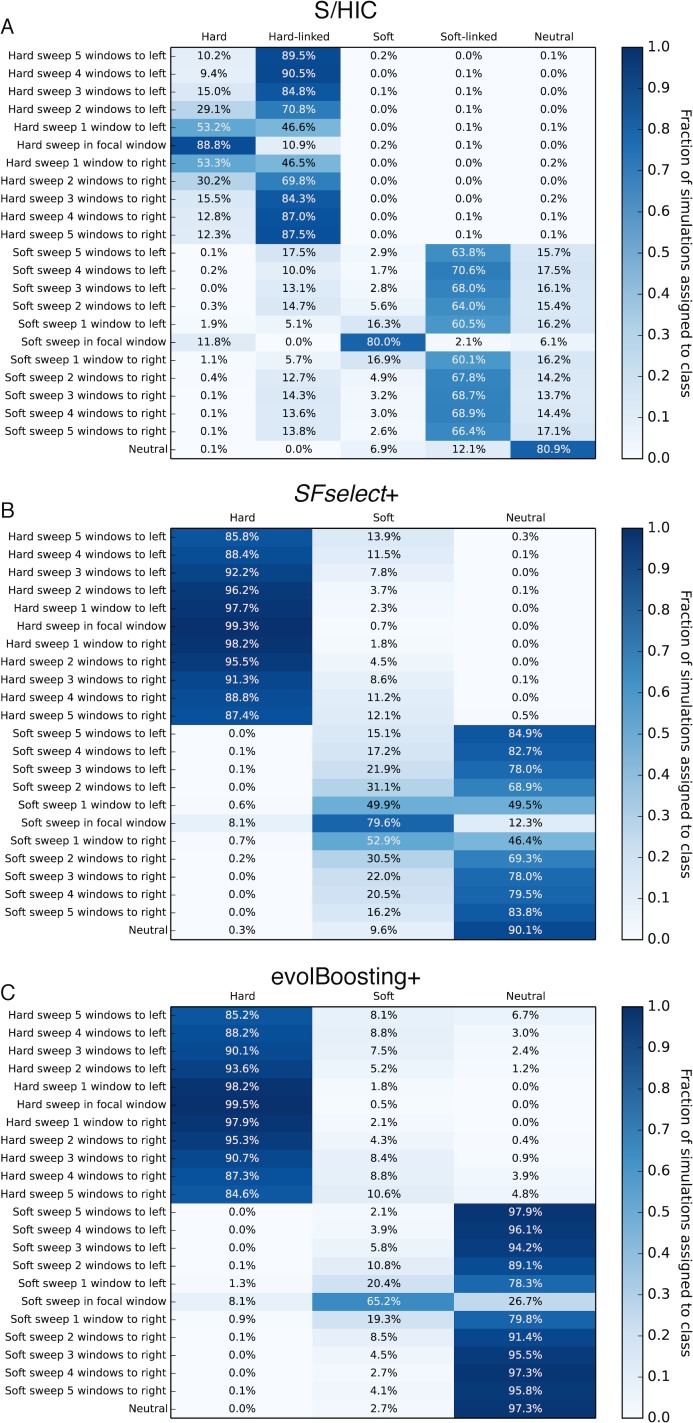
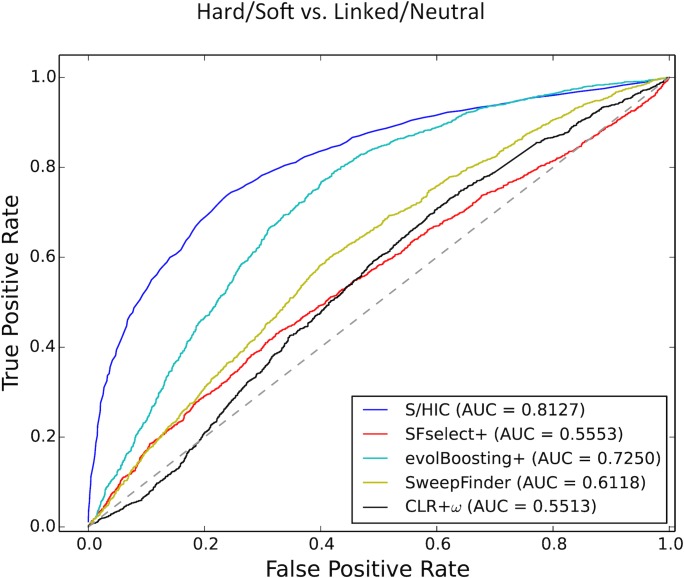
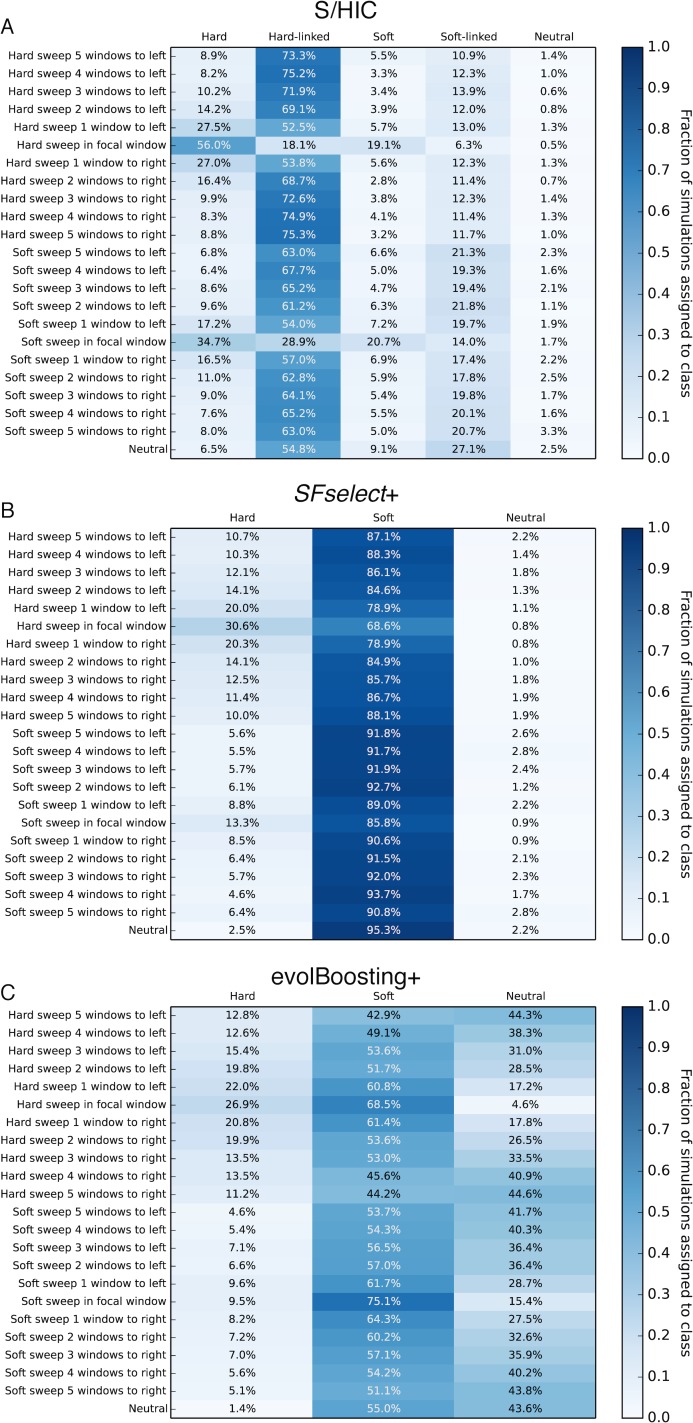
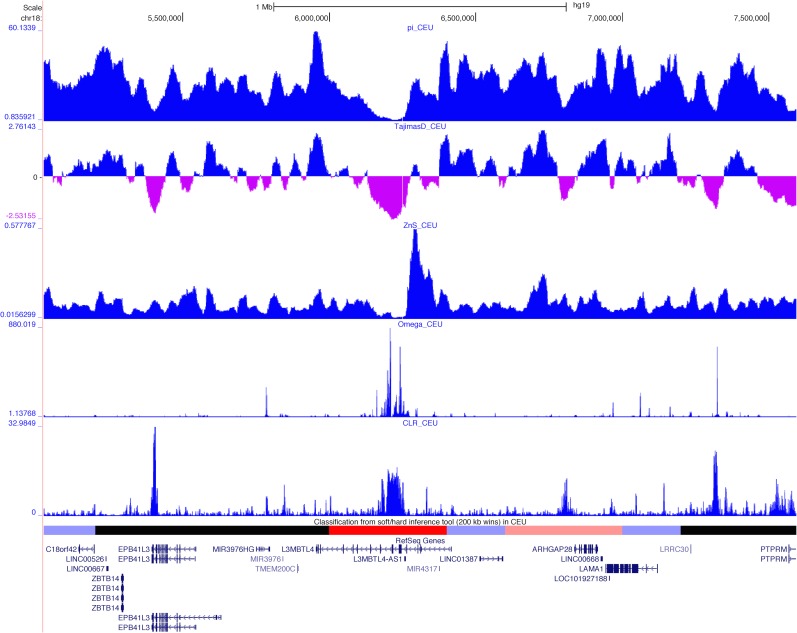
References
-
- Maynard Smith J, Haigh J. The hitch-hiking effect of a favourable gene. Genet Res. 1974;23(1):23–35. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
