

Dirichlet-Laplace priors for optimal shrinkage
- PMID: 27019543
- PMCID: PMC4803119
- DOI: 10.1080/01621459.2014.960967
Dirichlet-Laplace priors for optimal shrinkage
Abstract
Penalized regression methods, such as L1 regularization, are routinely used in high-dimensional applications, and there is a rich literature on optimality properties under sparsity assumptions. In the Bayesian paradigm, sparsity is routinely induced through two-component mixture priors having a probability mass at zero, but such priors encounter daunting computational problems in high dimensions. This has motivated continuous shrinkage priors, which can be expressed as global-local scale mixtures of Gaussians, facilitating computation. In contrast to the frequentist literature, little is known about the properties of such priors and the convergence and concentration of the corresponding posterior distribution. In this article, we propose a new class of Dirichlet-Laplace priors, which possess optimal posterior concentration and lead to efficient posterior computation. Finite sample performance of Dirichlet-Laplace priors relative to alternatives is assessed in simulated and real data examples.
Keywords: Bayesian; Convergence rate; High dimensional; L1; Lasso; Penalized regression; Regularization; Shrinkage prior.
Figures
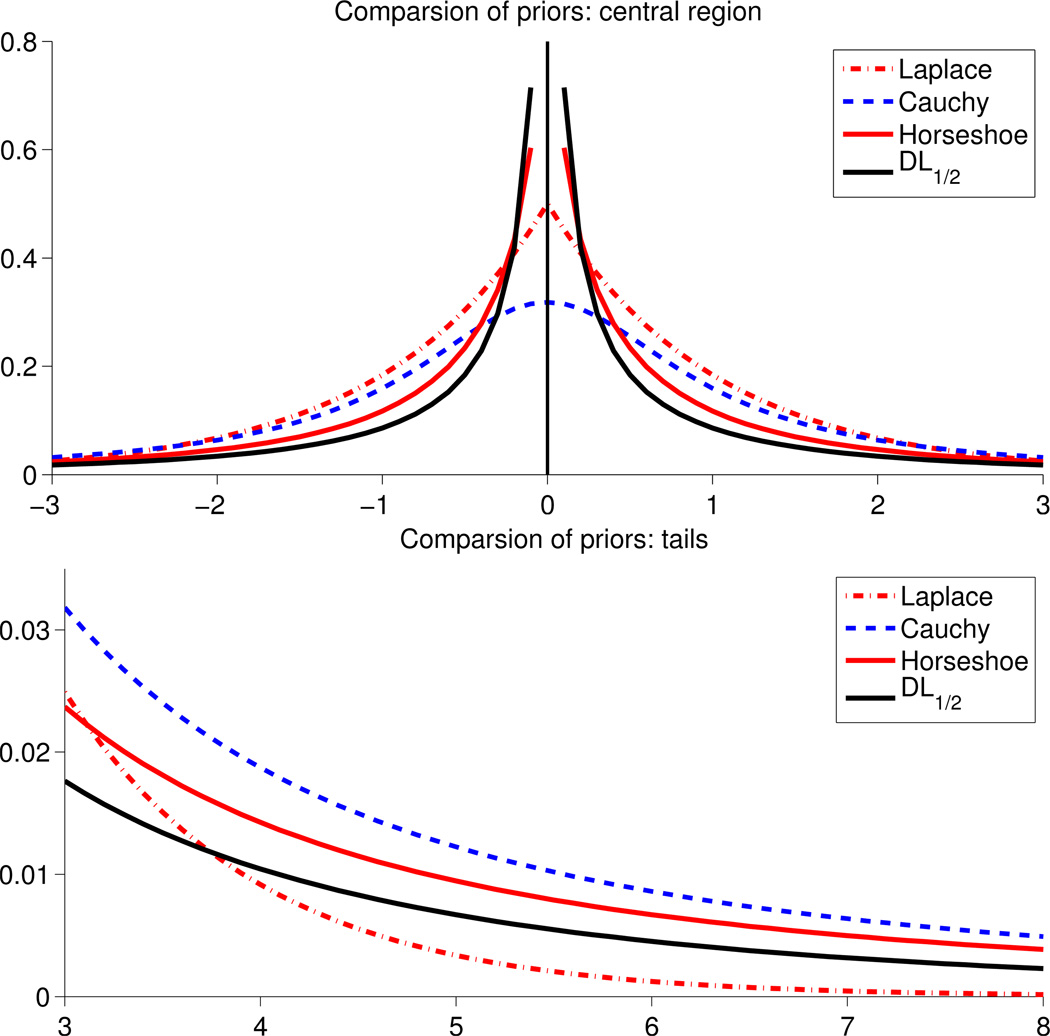
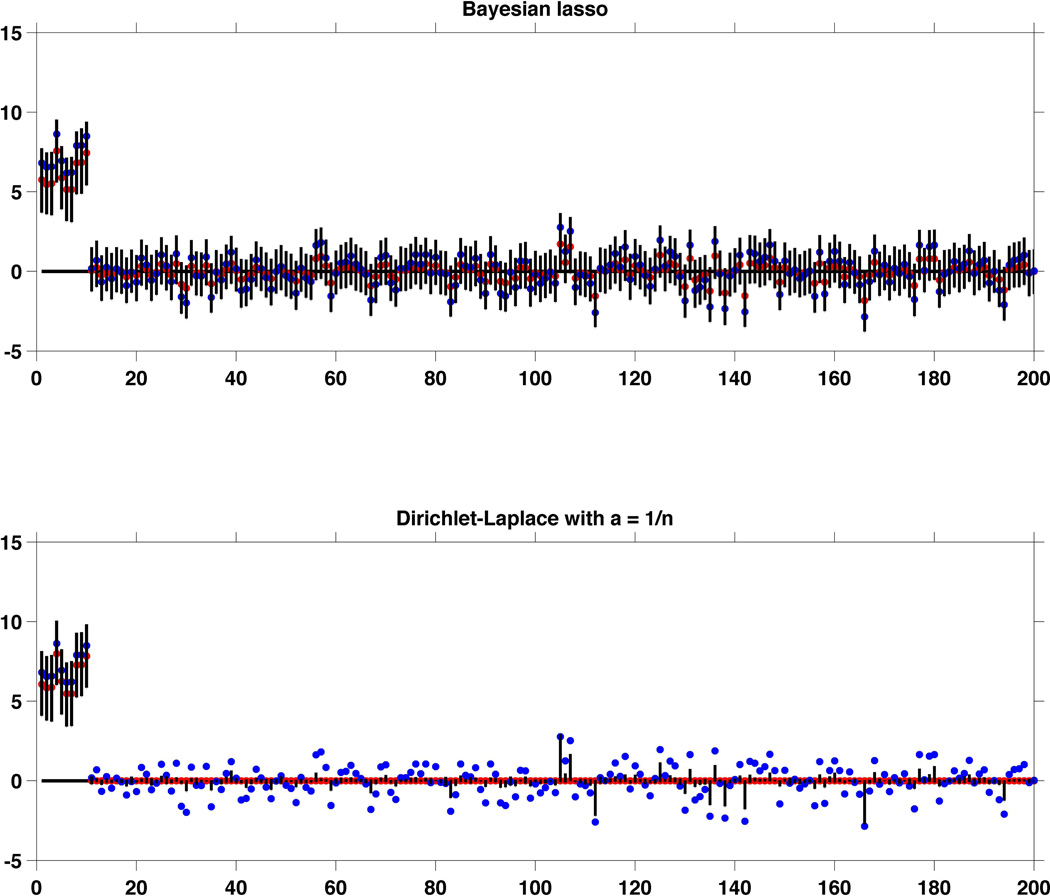
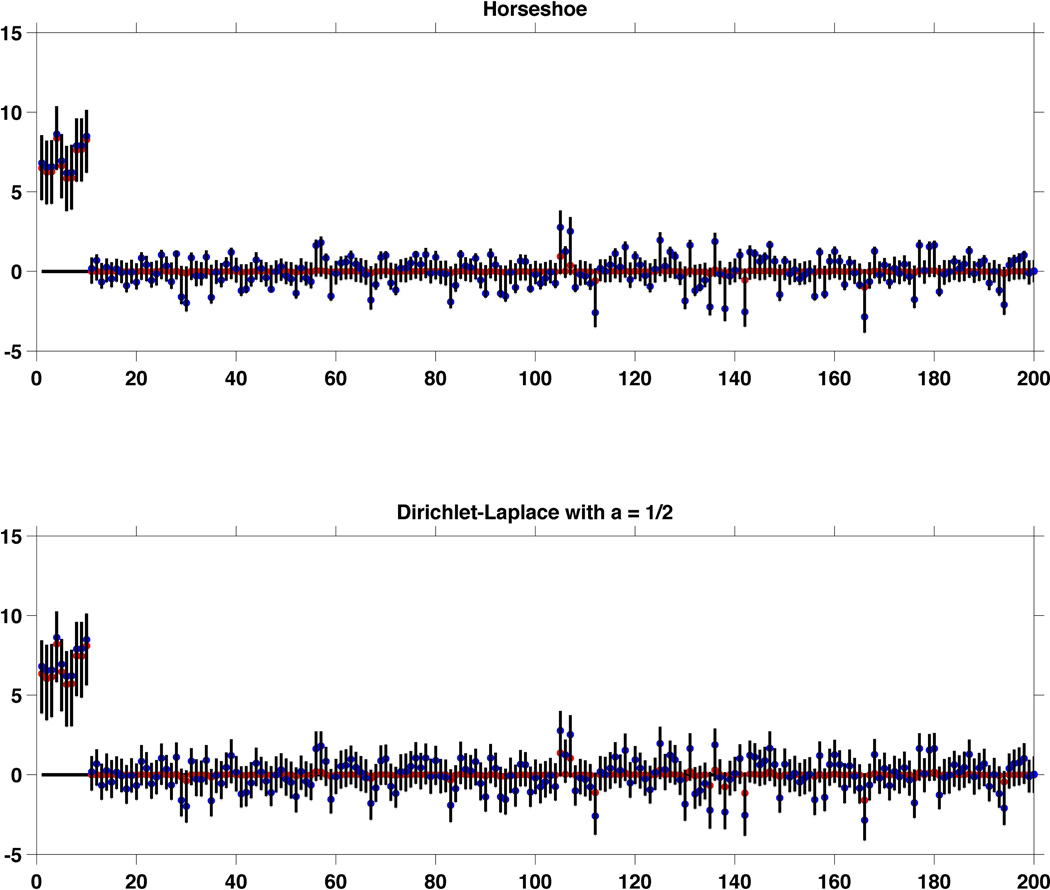

References
-
- Abramowitz M, Stegun IA. Handbook of mathematical functions: with formulas, graphs, and mathematical tables. Vol. 55. Dover publications; 1965.
-
- Alzer H. On some inequalities for the incomplete gamma function. Mathematics of Computation. 1997;66(218):771–778.
-
- Armagan Artin, Dunson David B, Lee Jaeyong, Bajwa Waheed U, Strawn Nate. Posterior consistency in linear models under shrinkage priors. Biometrika. 2013;100(4):1011–1018.
-
- Benjamini Yoav, Hochberg Yosef. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society. Series B (Methodological) 1995:289–300.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources