

Statistically Controlling for Confounding Constructs Is Harder than You Think
- PMID: 27031707
- PMCID: PMC4816570
- DOI: 10.1371/journal.pone.0152719
Statistically Controlling for Confounding Constructs Is Harder than You Think
Abstract
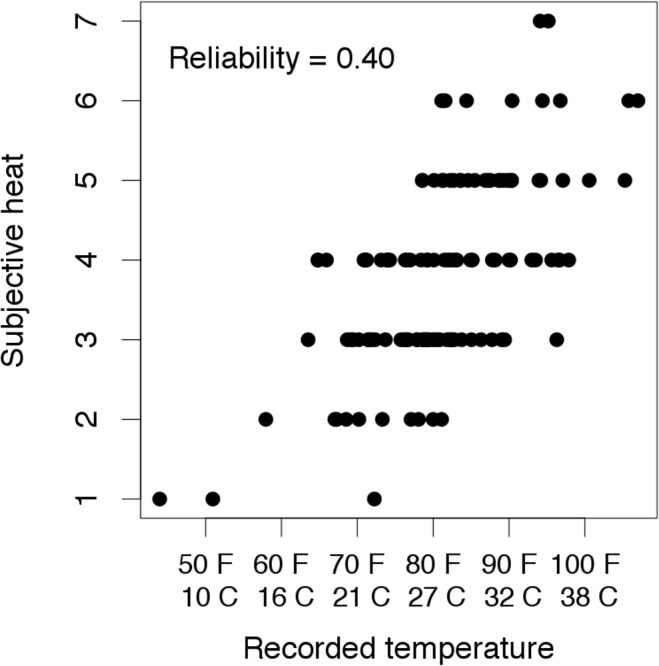
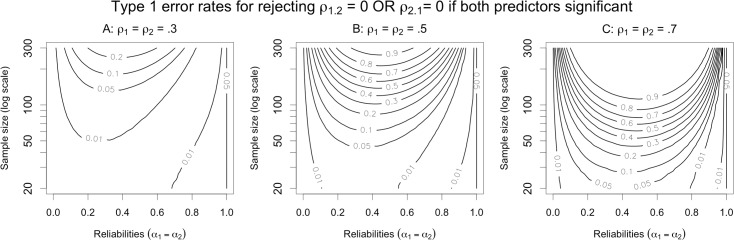
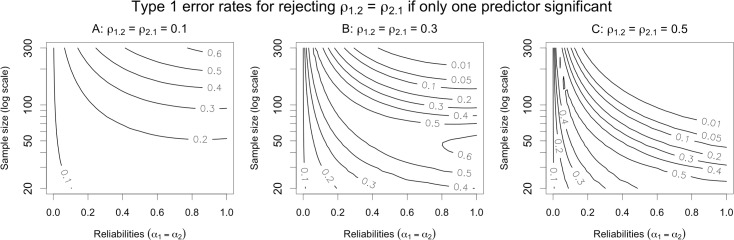
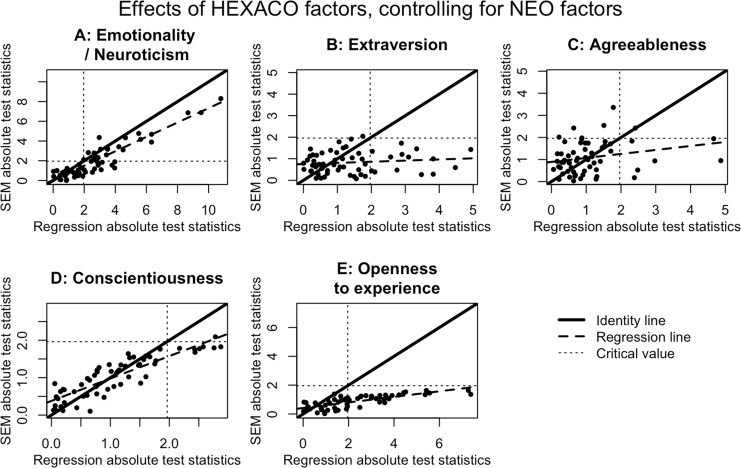
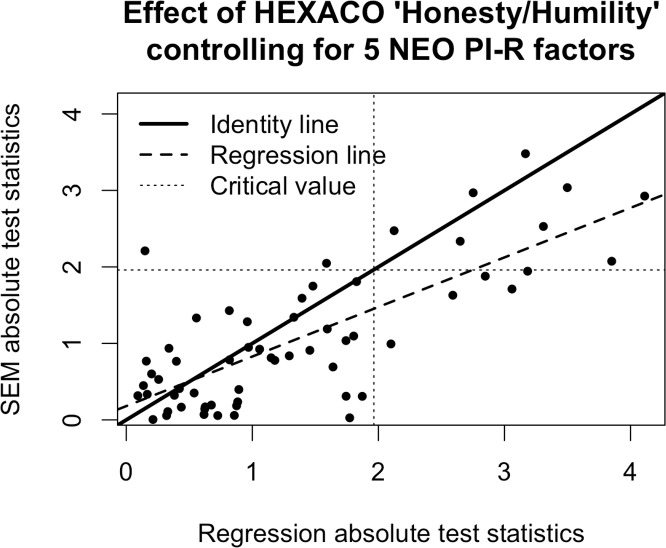
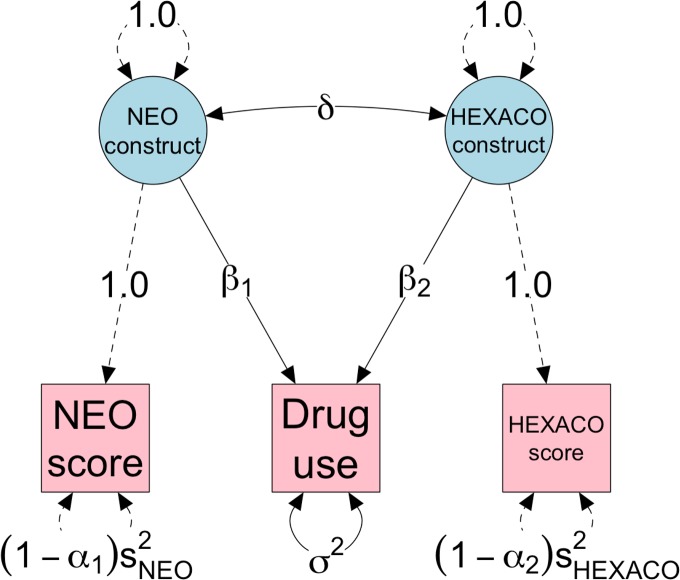
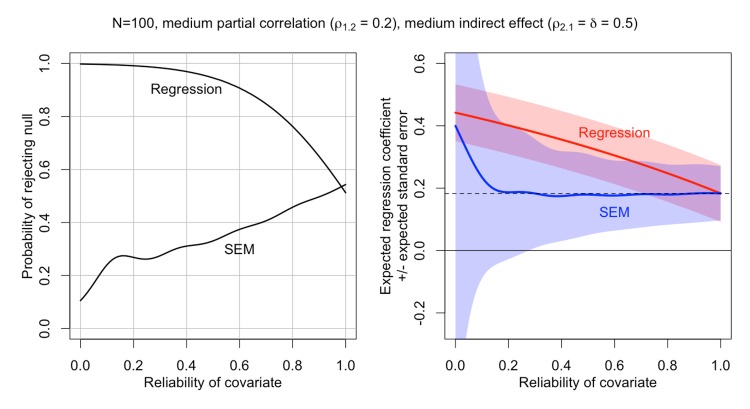
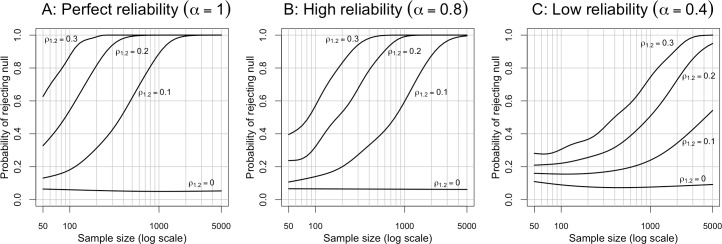
Social scientists often seek to demonstrate that a construct has incremental validity over and above other related constructs. However, these claims are typically supported by measurement-level models that fail to consider the effects of measurement (un)reliability. We use intuitive examples, Monte Carlo simulations, and a novel analytical framework to demonstrate that common strategies for establishing incremental construct validity using multiple regression analysis exhibit extremely high Type I error rates under parameter regimes common in many psychological domains. Counterintuitively, we find that error rates are highest--in some cases approaching 100%--when sample sizes are large and reliability is moderate. Our findings suggest that a potentially large proportion of incremental validity claims made in the literature are spurious. We present a web application (http://jakewestfall.org/ivy/) that readers can use to explore the statistical properties of these and other incremental validity arguments. We conclude by reviewing SEM-based statistical approaches that appropriately control the Type I error rate when attempting to establish incremental validity.
Conflict of interest statement
Figures




Similar articles
-
Testing for robustness in Monte Carlo studies.Psychol Methods. 2000 Jun;5(2):230-40. doi: 10.1037/1082-989x.5.2.230. Psychol Methods. 2000. PMID: 10937332
-
Reviewing the psychometric properties of contemporary circadian typology measures.Chronobiol Int. 2013 Dec;30(10):1261-71. doi: 10.3109/07420528.2013.817415. Epub 2013 Sep 3. Chronobiol Int. 2013. PMID: 24001393
-
Standard errors and confidence intervals for correlations corrected for indirect range restriction: A simulation study comparing analytic and bootstrap methods.Br J Math Stat Psychol. 2018 Feb;71(1):39-59. doi: 10.1111/bmsp.12105. Epub 2017 Jun 20. Br J Math Stat Psychol. 2018. PMID: 28631350
-
A psychometric toolbox for testing validity and reliability.J Nurs Scholarsh. 2007;39(2):155-64. doi: 10.1111/j.1547-5069.2007.00161.x. J Nurs Scholarsh. 2007. PMID: 17535316 Review.
-
The incremental validity of psychological testing and assessment: conceptual, methodological, and statistical issues.Psychol Assess. 2003 Dec;15(4):446-55. doi: 10.1037/1040-3590.15.4.446. Psychol Assess. 2003. PMID: 14692841 Review.
Cited by
-
Genetic and Environmental Factors of Non-Ability-Based Confidence.Soc Psychol Personal Sci. 2022 Apr;13(3):734-746. doi: 10.1177/19485506211036610. Epub 2021 Sep 6. Soc Psychol Personal Sci. 2022. PMID: 39006758 Free PMC article.
-
Predictors of well-being and productivity among software professionals during the COVID-19 pandemic - a longitudinal study.Empir Softw Eng. 2021;26(4):62. doi: 10.1007/s10664-021-09945-9. Epub 2021 Apr 28. Empir Softw Eng. 2021. PMID: 33942010 Free PMC article.
-
Valuing time over money predicts happiness after a major life transition: A preregistered longitudinal study of graduating students.Sci Adv. 2019 Sep 18;5(9):eaax2615. doi: 10.1126/sciadv.aax2615. eCollection 2019 Sep. Sci Adv. 2019. PMID: 31555738 Free PMC article.
-
The Social Brain Automatically Predicts Others' Future Mental States.J Neurosci. 2019 Jan 2;39(1):140-148. doi: 10.1523/JNEUROSCI.1431-18.2018. Epub 2018 Nov 2. J Neurosci. 2019. PMID: 30389840 Free PMC article.
-
The Association between Fast Food Outlets and Overweight in Adolescents Is Confounded by Neighbourhood Deprivation: A Longitudinal Analysis of the Millennium Cohort Study.Int J Environ Res Public Health. 2021 Dec 15;18(24):13212. doi: 10.3390/ijerph182413212. Int J Environ Res Public Health. 2021. PMID: 34948820 Free PMC article.
References
-
- Hunsley J, Meyer GJ. The Incremental Validity of Psychological Testing and Assessment: Conceptual, Methodological, and Statistical Issues. Psychol Assess. 2003;15(4):446–55. - PubMed
-
- Sechrest L. Incremental validity: A recommendation. Educ Psychol Meas. 1963;23(1):153–8.
-
- Christenfeld NJS, Sloan RP, Carroll D, Greenland S. Risk factors, confounding, and the illusion of statistical control. Psychosom Med. 2004. December;66(6):868–75. - PubMed
-
- Fewell Z, Smith GD, Sterne JAC. The impact of residual and unmeasured confounding in epidemiologic studies: a simulation study. Am J Epidemiol. 2007. September 15;166(6):646–55. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
