

Dynamics of scene representations in the human brain revealed by magnetoencephalography and deep neural networks
- PMID: 27039703
- PMCID: PMC5542416
- DOI: 10.1016/j.neuroimage.2016.03.063
Dynamics of scene representations in the human brain revealed by magnetoencephalography and deep neural networks
Abstract
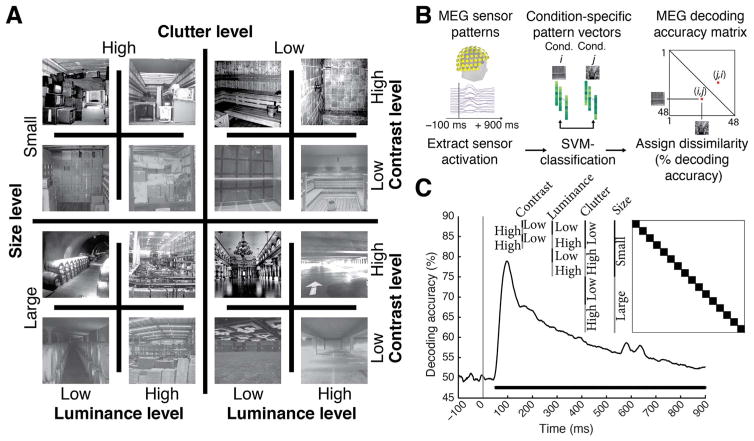
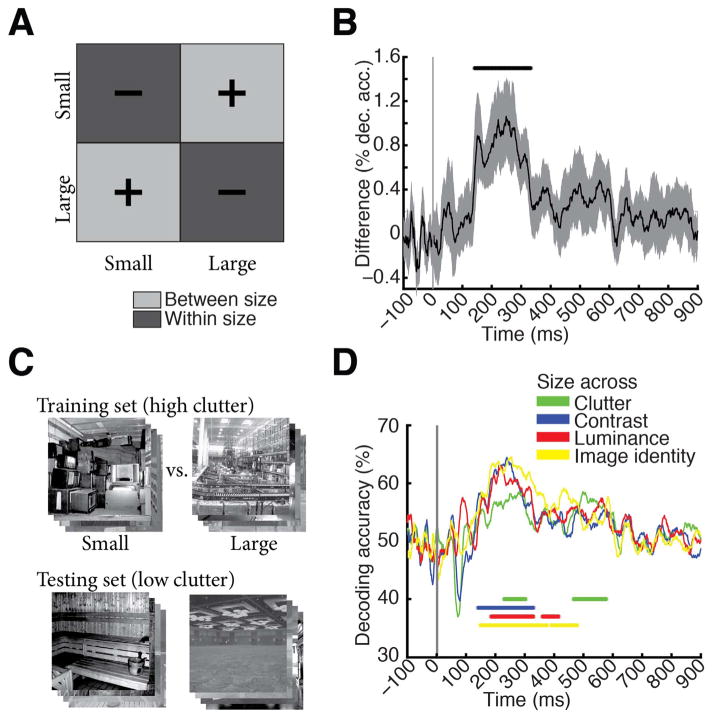
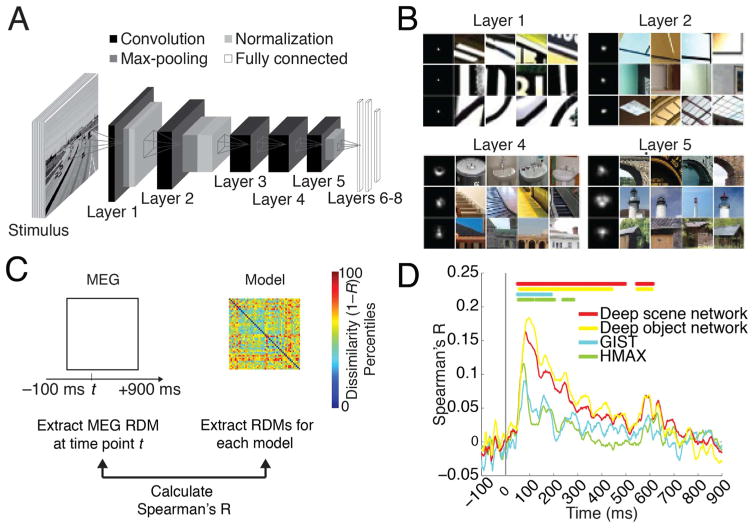
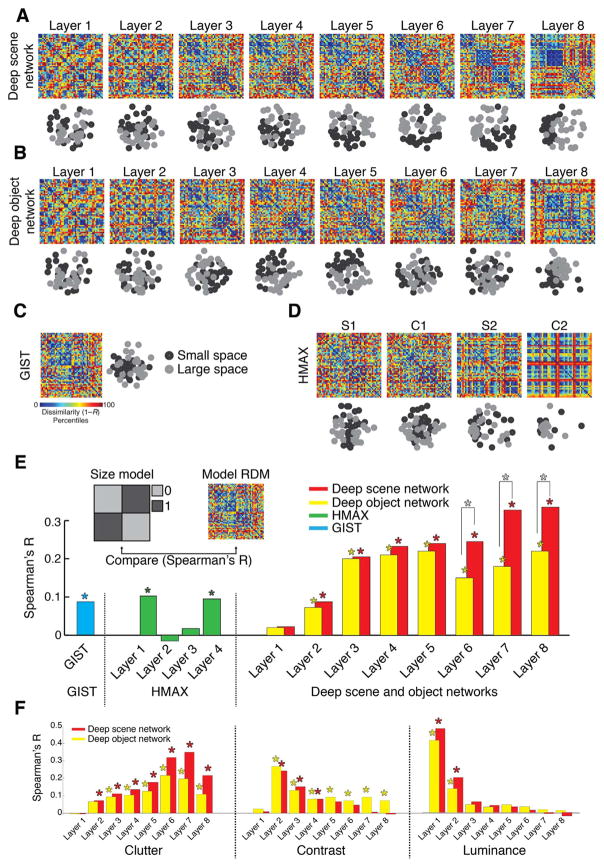
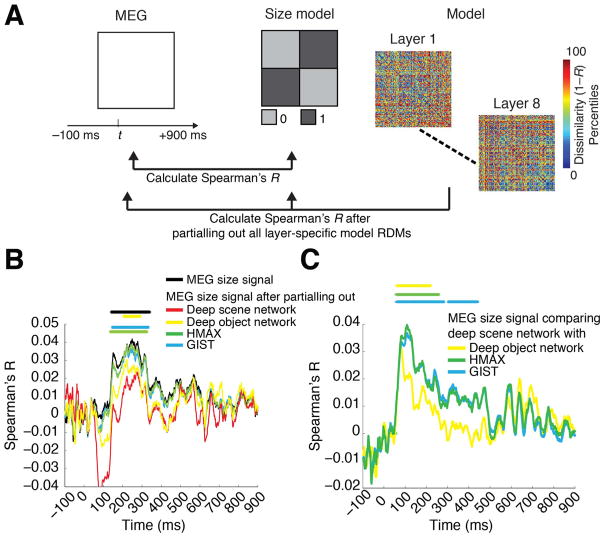
Human scene recognition is a rapid multistep process evolving over time from single scene image to spatial layout processing. We used multivariate pattern analyses on magnetoencephalography (MEG) data to unravel the time course of this cortical process. Following an early signal for lower-level visual analysis of single scenes at ~100ms, we found a marker of real-world scene size, i.e. spatial layout processing, at ~250ms indexing neural representations robust to changes in unrelated scene properties and viewing conditions. For a quantitative model of how scene size representations may arise in the brain, we compared MEG data to a deep neural network model trained on scene classification. Representations of scene size emerged intrinsically in the model, and resolved emerging neural scene size representation. Together our data provide a first description of an electrophysiological signal for layout processing in humans, and suggest that deep neural networks are a promising framework to investigate how spatial layout representations emerge in the human brain.
Keywords: Deep neural network; Magnetoencephalography; Representational similarity analysis; Scene perception; Spatial layout.
Copyright © 2017 The Authors. Published by Elsevier Inc. All rights reserved.
Figures
References
-
- Aguirre GK, Zarahn E, D’Esposito M. An area within human ventral cortex sensitive to “building” stimuli: evidence and implications. Neuron. 1998;21:373–383. - PubMed
-
- Allison T, Ginter H, McCarthy G, Nobre AC, Puce A, Luby M, Spencer DD. Face recognition in human extrastriate cortex. J Neurophysiol. 1994;71:821–825. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
