

Dopamine reward prediction error coding
- PMID: 27069377
- PMCID: PMC4826767
- DOI: 10.31887/DCNS.2016.18.1/wschultz
Dopamine reward prediction error coding
Abstract
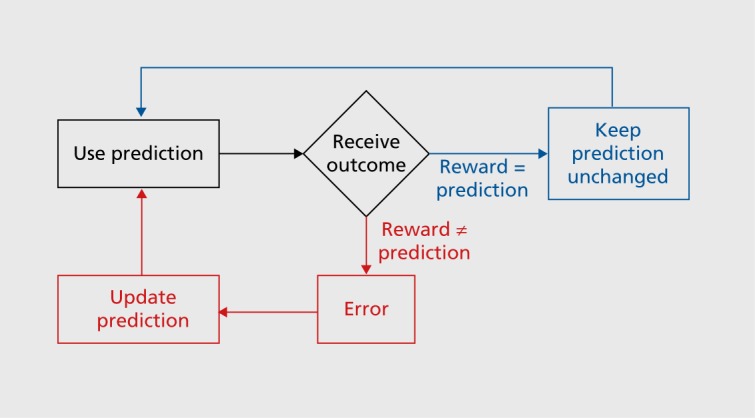
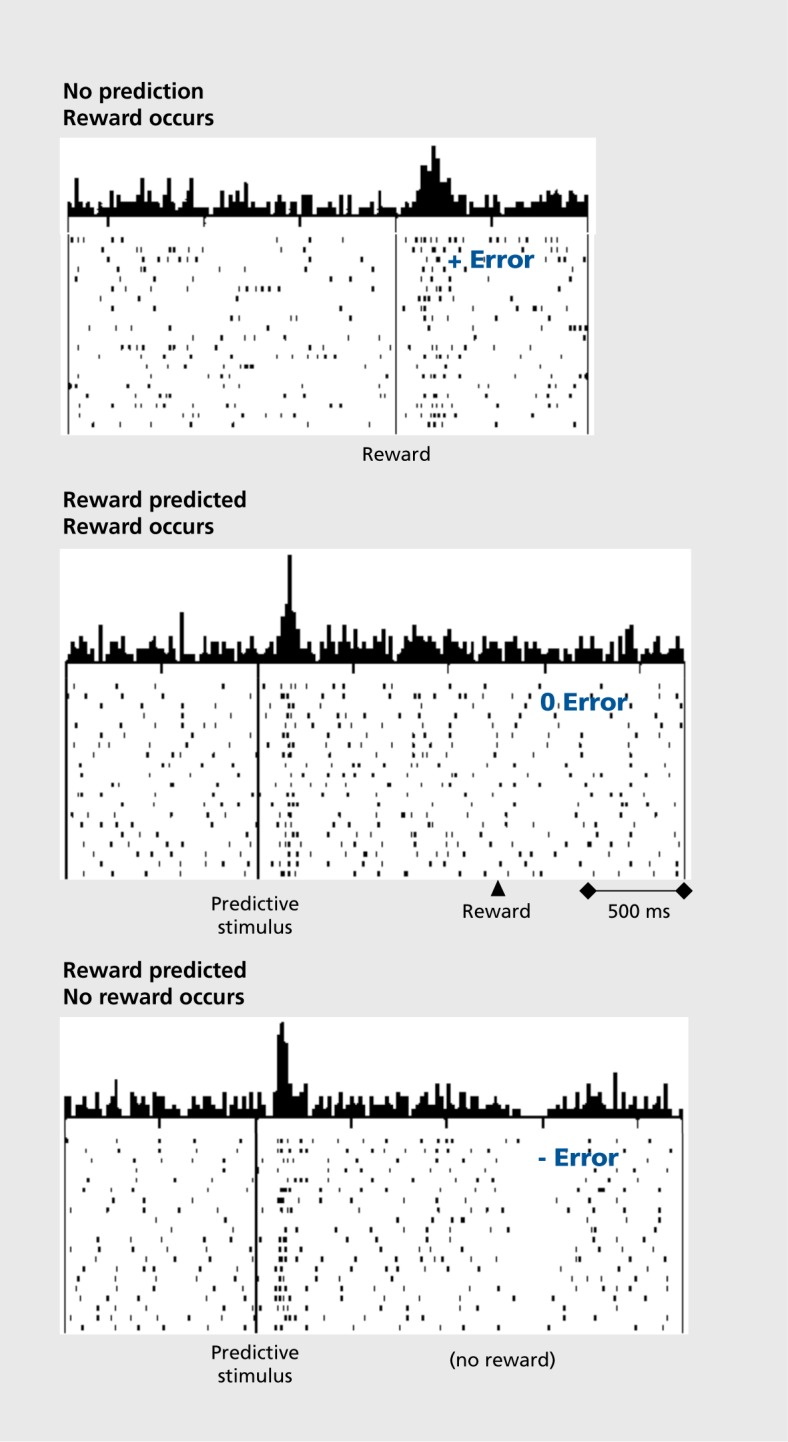
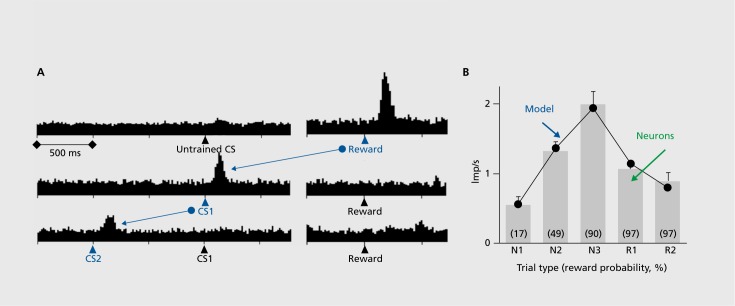
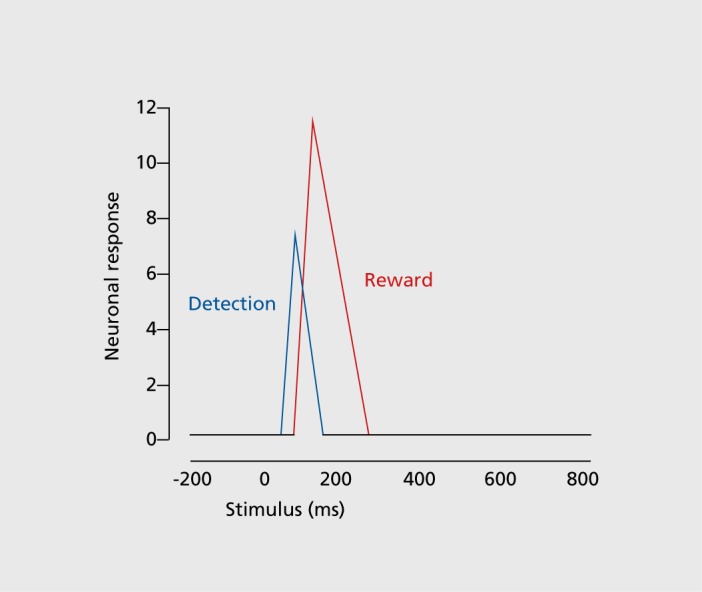
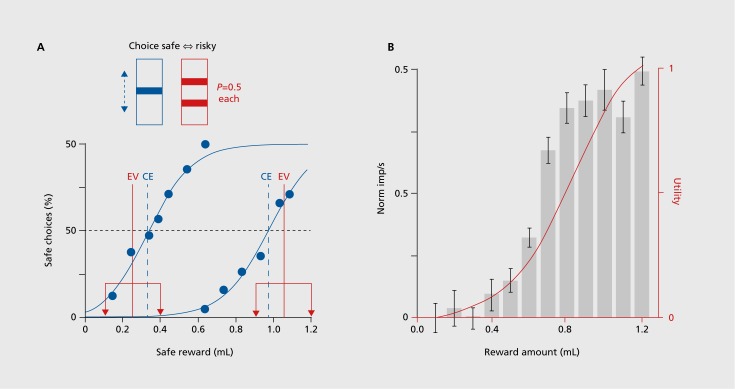
Reward prediction errors consist of the differences between received and predicted rewards. They are crucial for basic forms of learning about rewards and make us strive for more rewards-an evolutionary beneficial trait. Most dopamine neurons in the midbrain of humans, monkeys, and rodents signal a reward prediction error; they are activated by more reward than predicted (positive prediction error), remain at baseline activity for fully predicted rewards, and show depressed activity with less reward than predicted (negative prediction error). The dopamine signal increases nonlinearly with reward value and codes formal economic utility. Drugs of addiction generate, hijack, and amplify the dopamine reward signal and induce exaggerated, uncontrolled dopamine effects on neuronal plasticity. The striatum, amygdala, and frontal cortex also show reward prediction error coding, but only in subpopulations of neurons. Thus, the important concept of reward prediction errors is implemented in neuronal hardware.
Los errores en la predicción de la recompensa se deben a las diferencias entre las recompensas recibidas y predichas. Ellos son cruciales para las formas básicas de aprendizaje acerca de las recompensas y nos hacen esforzarnos por más recompensas, lo que constituye un rasgo evolucionario beneficioso. La mayoría de las neuronas dopaminérgicas en el mesencéfalo de los humanos, monos y roedores dan información sobre el error en la predicción de la recompensa; ellas son activadas por más recompensa que la predicha (error de predicción positivo); se mantienen en una actividad basal para el total de las recompensas predichas, y muestran una actividad disminuida con menos recompensa que la predicha (error de predicción negativo). La señal de dopamina aumenta de forma no lineal con el valor de la recompensa y da claves sobre la utilidad económica formal. Las drogas adictivas generan, secuestran y amplifican la señal de recompensa dopaminérgica e inducen efectos dopaminérgicos exagerados y descontrolados en la plasticidad neuronal. El estriado, la amígdala y la corteza frontal también codifican errores en la predicción de la recompensa, pero solo en ciertas subpoblaciones de neuronas. Por lo tanto, el concepto importante de errores en la predicción de recompensa está implementado en el hardware neuronal.
Les erreurs de prédiction de la récompense consistent en différences entre la récompense reçue et celle prévue. Elles sont déterminates pour les formes basiques d'apprentissage concernant la récompense et nous font lutter pour plus de récompense, une caractéristique bénéfique de l'évolution. La plupart des neurones dopaminergiques du mésencéphale des humains, des singes et des rongeurs indiquent une erreur de prédiction de la récompense ; ils sont activés par plus de récompense que prévu (erreur de prédiction positive), restent dans l'activité initiale pour une récompense complètement prévue et montrent une activité diminuée en cas de moins de récompense que prévu (erreur de prédiction négative). Le signal dopaminergique augmente de façon non linéaire avec la récompense et code I'utilité économique formelle. Les médicaments addictifs génèrent, détournent et amplifient le signal de la récompense dopaminergique et induisent des effets dopaminergiques exagérés et non controlés sur la plasticité neuronale. Le striatum, I'amygdale et le cortex frontal manifestent aussi le codage erroné de la prédiction de la récompense, mais seulement dans des sous-populations de neurones. L'important concept d'erreurs de prédiction de la récompense est donc mis en œuvre dans le matériel neuronal.
Keywords: dopamine; neuro-physiology; neuron; prediction; reward; striatum; substantia nigra; ventral tegmental area.
Figures
References
-
- Pavlov PI. Conditioned Reflexes. London, UK: Oxford University Press: 1927
-
- Thorndike EL. Animal Intelligence: Experimental Studies. New York, NY: MacMillan: 1911
-
- Rescorla RA., Wagner AR. A theory of Pavlovian conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In: Black AH, Prokasy WF, eds. Classical Conditioning II: Current Research and Theory. New York, NY: Appleton Century Crofts: 1972:64–99.
-
- Olds J., Milner P. Positive reinforcement produced by electrical stimulation of septal area and other regions of rat brain. J Comp Physiol Psychol. 1954;47:419–427. - PubMed
-
- Corbett D., Wise RA. Intracranial self-stimulation in relation to the ascending dopaminergic systems of the midbrain: A moveable microelectrode study. Brain Res. 1980;185:1–15. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources