

A Method to Exploit the Structure of Genetic Ancestry Space to Enhance Case-Control Studies
- PMID: 27087321
- PMCID: PMC4864319
- DOI: 10.1016/j.ajhg.2016.02.025
A Method to Exploit the Structure of Genetic Ancestry Space to Enhance Case-Control Studies
Abstract
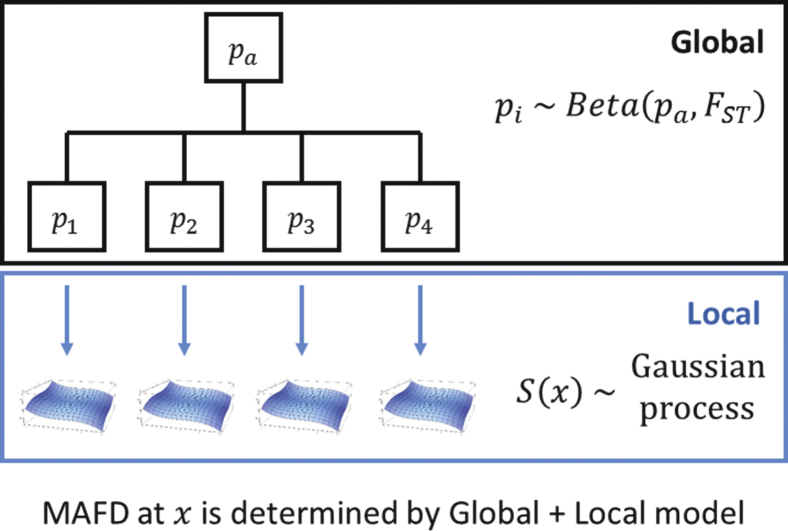
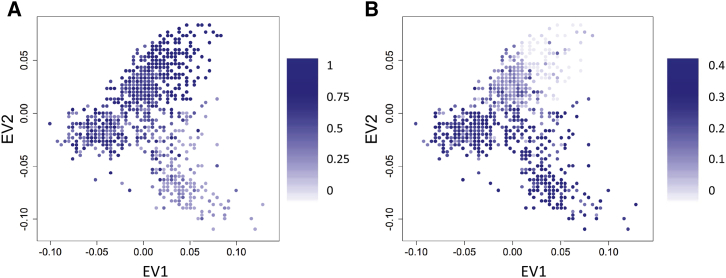
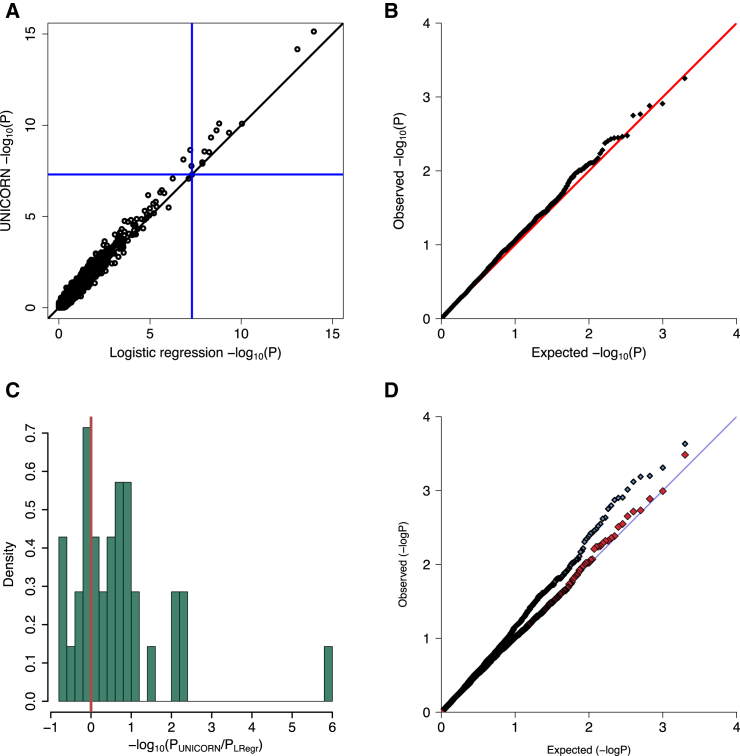
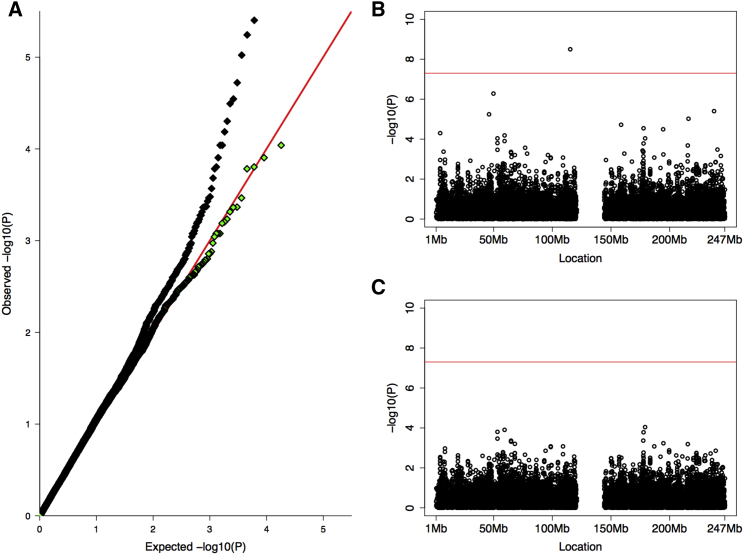
One goal of human genetics is to understand the genetic basis of disease, a challenge for diseases of complex inheritance because risk alleles are few relative to the vast set of benign variants. Risk variants are often sought by association studies in which allele frequencies in case subjects are contrasted with those from population-based samples used as control subjects. In an ideal world we would know population-level allele frequencies, releasing researchers to focus on case subjects. We argue this ideal is possible, at least theoretically, and we outline a path to achieving it in reality. If such a resource were to exist, it would yield ample savings and would facilitate the effective use of data repositories by removing administrative and technical barriers. We call this concept the Universal Control Repository Network (UNICORN), a means to perform association analyses without necessitating direct access to individual-level control data. Our approach to UNICORN uses existing genetic resources and various statistical tools to analyze these data, including hierarchical clustering with spectral analysis of ancestry; and empirical Bayesian analysis along with Gaussian spatial processes to estimate ancestry-specific allele frequencies. We demonstrate our approach using tens of thousands of control subjects from studies of Crohn disease, showing how it controls false positives, provides power similar to that achieved when all control data are directly accessible, and enhances power when control data are limiting or even imperfectly matched ancestrally. These results highlight how UNICORN can enable reliable, powerful, and convenient genetic association analyses without access to the individual-level data.
Copyright © 2016 The American Society of Human Genetics. Published by Elsevier Inc. All rights reserved.
Figures


References
-
- Koike A., Nishida N., Inoue I., Tsuji S., Tokunaga K. Genome-wide association database developed in the Japanese Integrated Database Project. J. Hum. Genet. 2009;54:543–546. - PubMed
Publication types
MeSH terms
Grants and funding
- J-0804/PUK_/Parkinson's UK/United Kingdom
- R37 MH057881/MH/NIMH NIH HHS/United States
- MC_G0901330/MRC_/Medical Research Council/United Kingdom
- R01 MH057881/MH/NIMH NIH HHS/United States
- MR/L501554/1/MRC_/Medical Research Council/United Kingdom
- MC_UU_12013/4/MRC_/Medical Research Council/United Kingdom
- CZB/4/540/CSO_/Chief Scientist Office/United Kingdom
- ETM/137/CSO_/Chief Scientist Office/United Kingdom
- G0800675/MRC_/Medical Research Council/United Kingdom
- U01 DK062420/DK/NIDDK NIH HHS/United States
- G0600329/MRC_/Medical Research Council/United Kingdom
- G0800759/MRC_/Medical Research Council/United Kingdom
- ETM/75/CSO_/Chief Scientist Office/United Kingdom
- G-1107/PUK_/Parkinson's UK/United Kingdom
- R01 MH101244/MH/NIMH NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
