

Controllability analysis of the directed human protein interaction network identifies disease genes and drug targets
- PMID: 27091990
- PMCID: PMC4983807
- DOI: 10.1073/pnas.1603992113
Controllability analysis of the directed human protein interaction network identifies disease genes and drug targets
Abstract
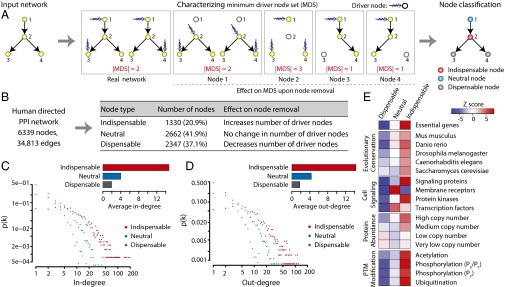
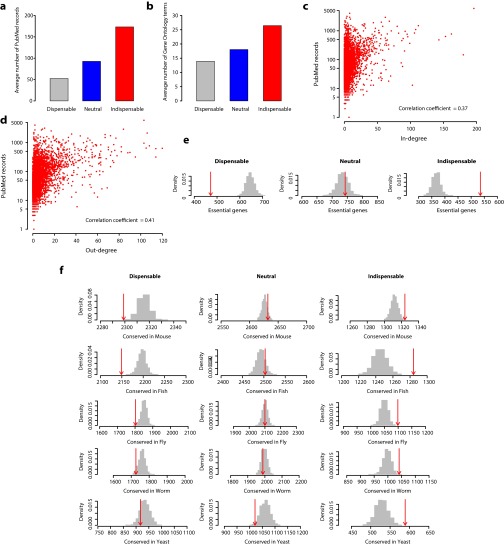
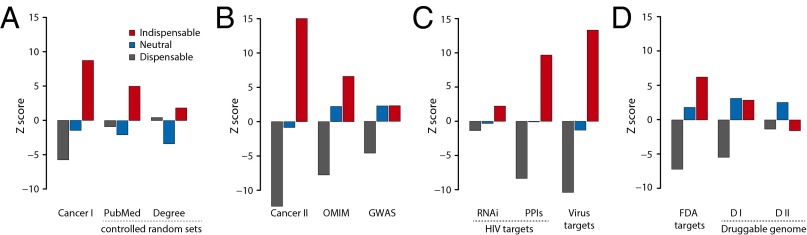
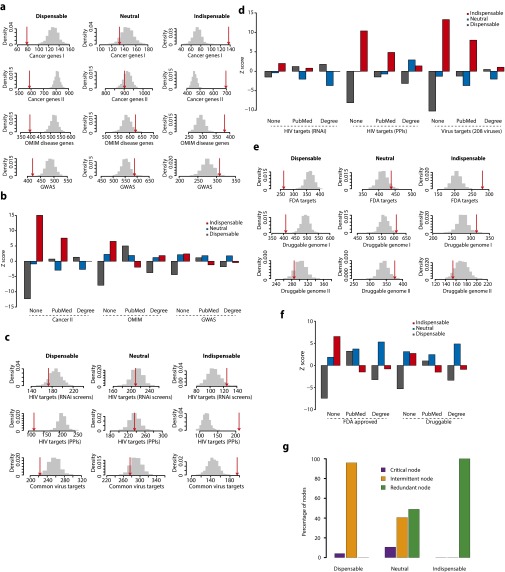
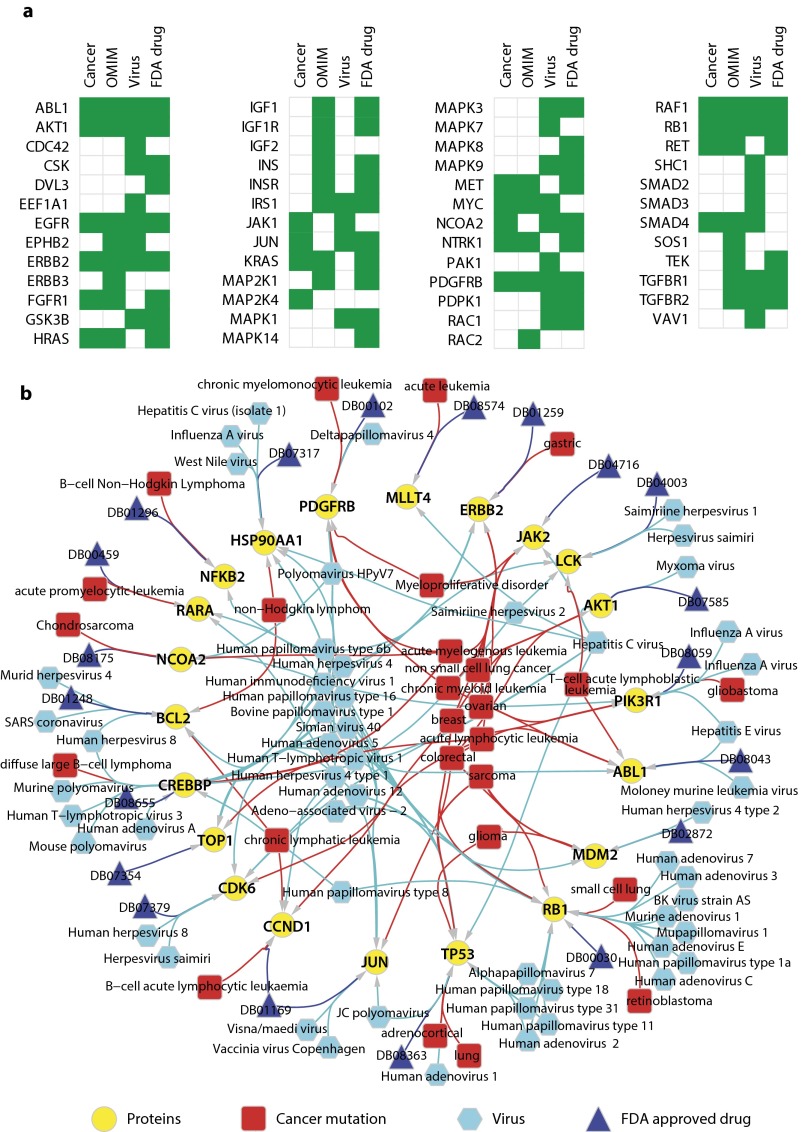
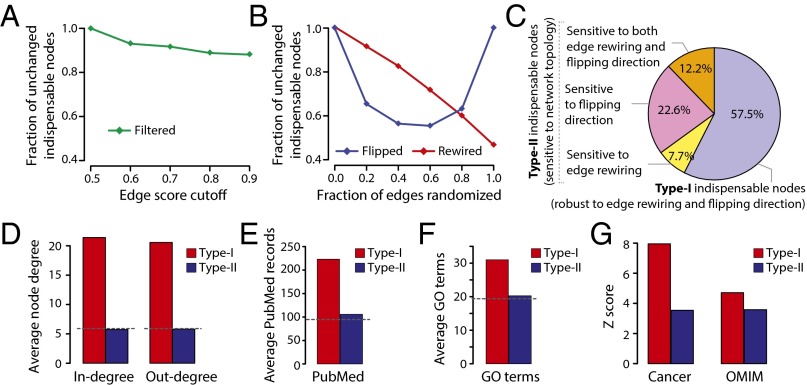
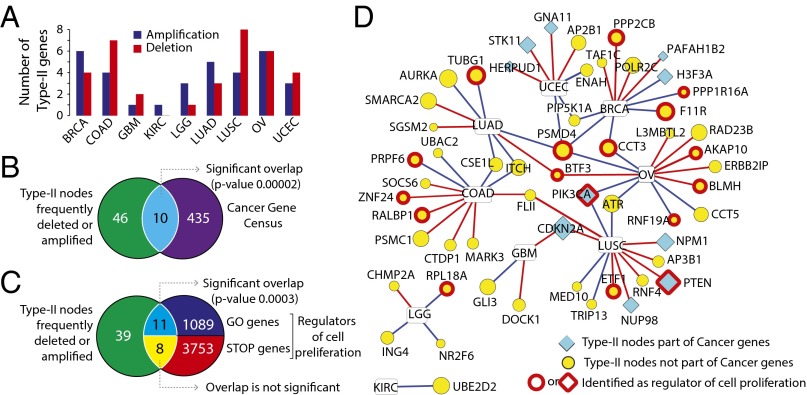
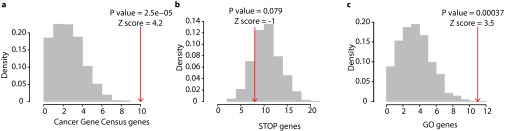
The protein-protein interaction (PPI) network is crucial for cellular information processing and decision-making. With suitable inputs, PPI networks drive the cells to diverse functional outcomes such as cell proliferation or cell death. Here, we characterize the structural controllability of a large directed human PPI network comprising 6,339 proteins and 34,813 interactions. This network allows us to classify proteins as "indispensable," "neutral," or "dispensable," which correlates to increasing, no effect, or decreasing the number of driver nodes in the network upon removal of that protein. We find that 21% of the proteins in the PPI network are indispensable. Interestingly, these indispensable proteins are the primary targets of disease-causing mutations, human viruses, and drugs, suggesting that altering a network's control property is critical for the transition between healthy and disease states. Furthermore, analyzing copy number alterations data from 1,547 cancer patients reveals that 56 genes that are frequently amplified or deleted in nine different cancers are indispensable. Among the 56 genes, 46 of them have not been previously associated with cancer. This suggests that controllability analysis is very useful in identifying novel disease genes and potential drug targets.
Keywords: controllability; disease genes; drug targets; network biology; protein–protein interaction network.
Conflict of interest statement
The authors declare no conflict of interest.
Figures


References
-
- Isidori A. 1995. Nonlinear Control Systems (Springer, Berlin, New York), 3rd Ed.
-
- Kalman RE. Mathematical description of linear dynamical systems. J Soc Indust Appl Math Ser A Control. 1963;1(2):152–192.
-
- Slotine JJE, Li W. 1991. Applied Nonlinear Control (Prentice Hall, Englewood Cliffs, NJ)
-
- Iglesias PA, Ingalls BP. 2010. Control Theory and Systems Biology (MIT Press, Cambridge, MA)
-
- Del Vecchio D, Murray RM. 2015. Biomolecular Feedback Systems (Princeton Univ Press, Princeton)
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
