

A detailed comparison of optimality and simplicity in perceptual decision making
- PMID: 27177259
- PMCID: PMC5452626
- DOI: 10.1037/rev0000028
A detailed comparison of optimality and simplicity in perceptual decision making
Abstract
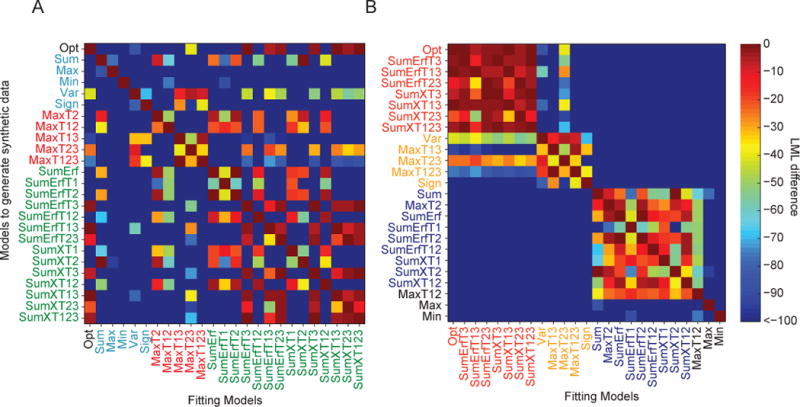
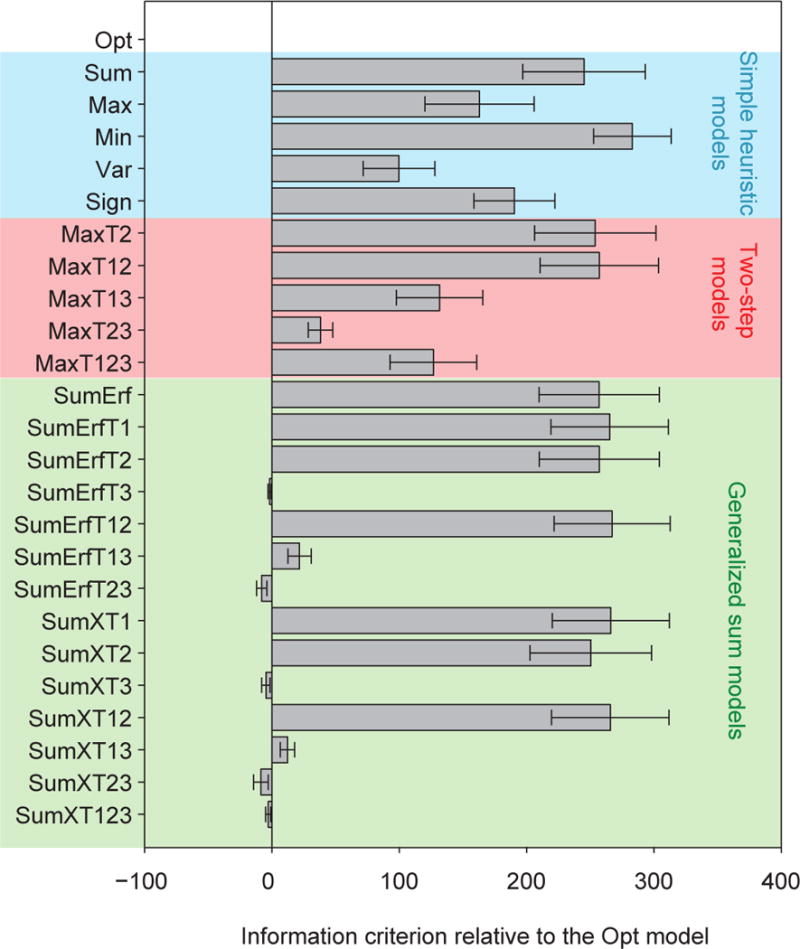
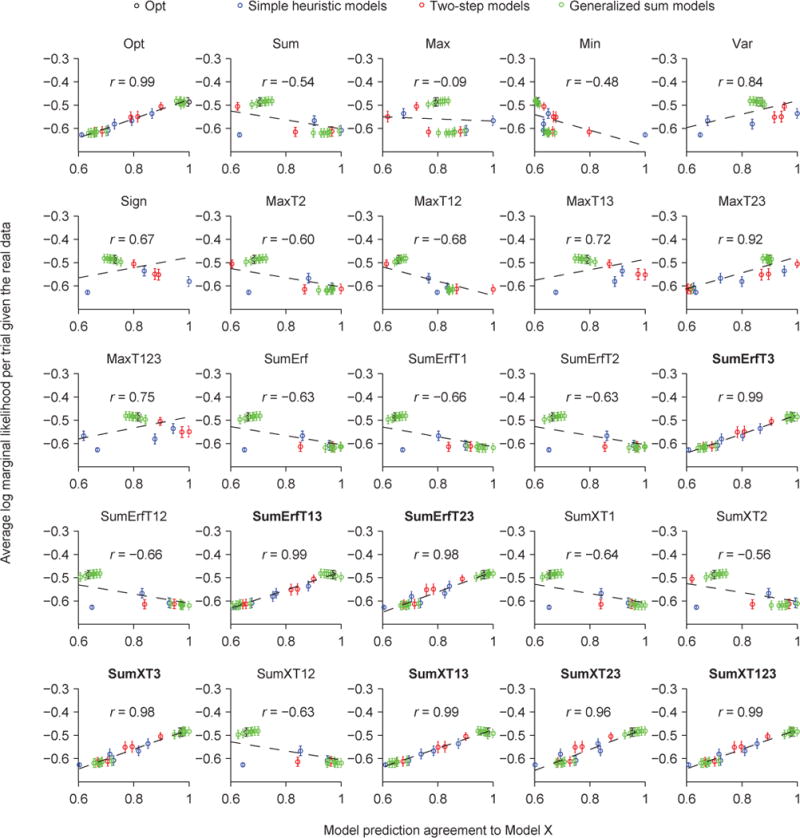
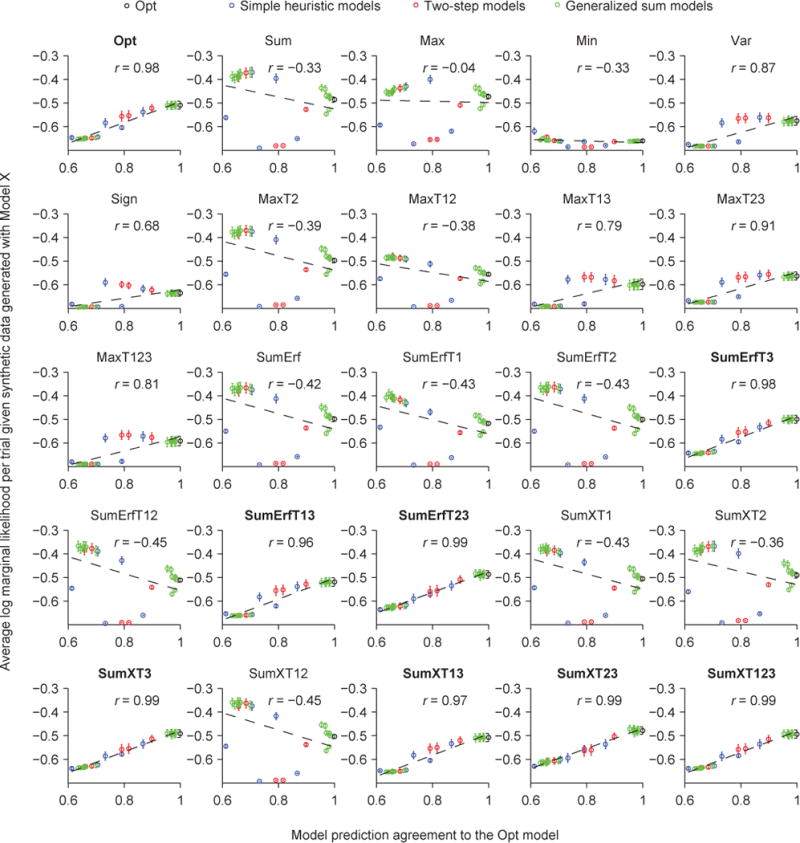
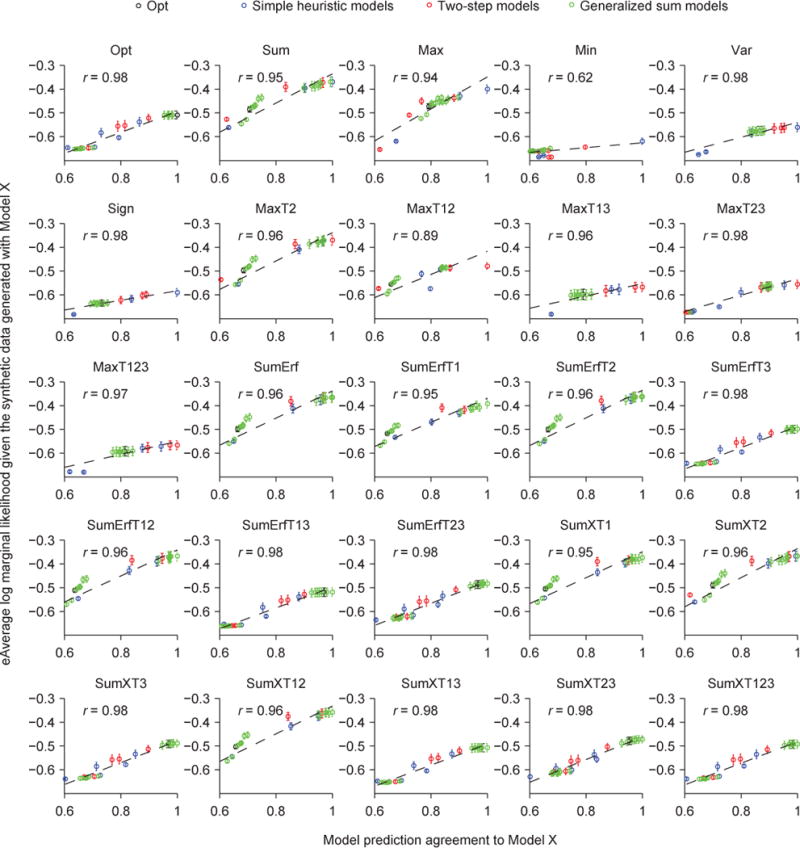
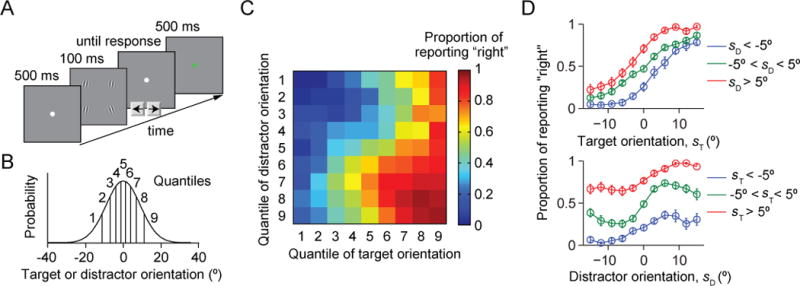
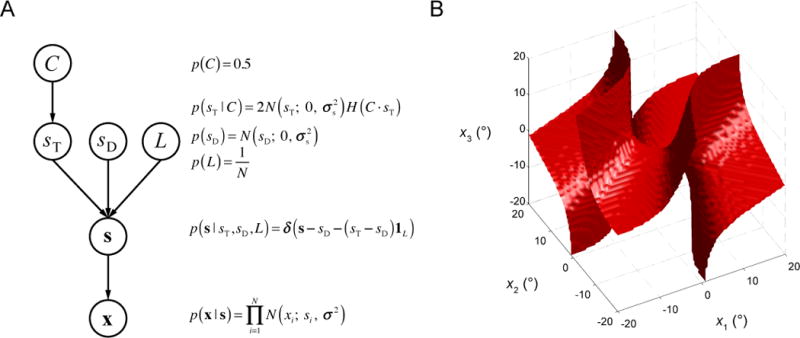
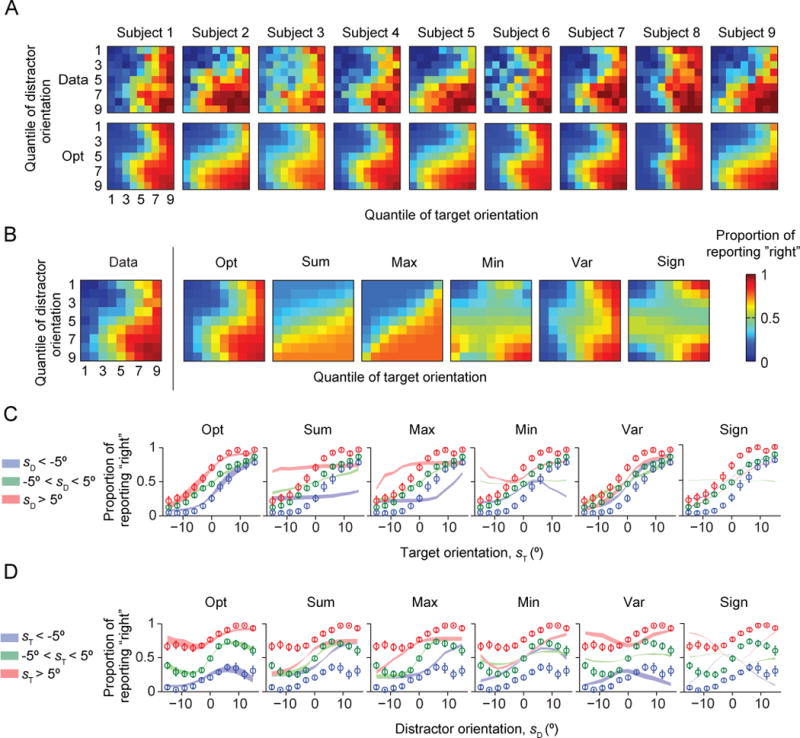
Two prominent ideas in the study of decision making have been that organisms behave near-optimally, and that they use simple heuristic rules. These principles might be operating in different types of tasks, but this possibility cannot be fully investigated without a direct, rigorous comparison within a single task. Such a comparison was lacking in most previous studies, because (a) the optimal decision rule was simple, (b) no simple suboptimal rules were considered, (c) it was unclear what was optimal, or (d) a simple rule could closely approximate the optimal rule. Here, we used a perceptual decision-making task in which the optimal decision rule is well-defined and complex, and makes qualitatively distinct predictions from many simple suboptimal rules. We find that all simple rules tested fail to describe human behavior, that the optimal rule accounts well for the data, and that several complex suboptimal rules are indistinguishable from the optimal one. Moreover, we found evidence that the optimal model is close to the true model: First, the better the trial-to-trial predictions of a suboptimal model agree with those of the optimal model, the better that suboptimal model fits; second, our estimate of the Kullback-Leibler divergence between the optimal model and the true model is not significantly different from zero. When observers receive no feedback, the optimal model still describes behavior best, suggesting that sensory uncertainty is implicitly represented and taken into account. Beyond the task and models studied here, our results have implications for best practices of model comparison. (PsycINFO Database Record
(c) 2016 APA, all rights reserved).
Conflict of interest statement
Conflict of interest: The authors declare no competing financial interests.
Figures
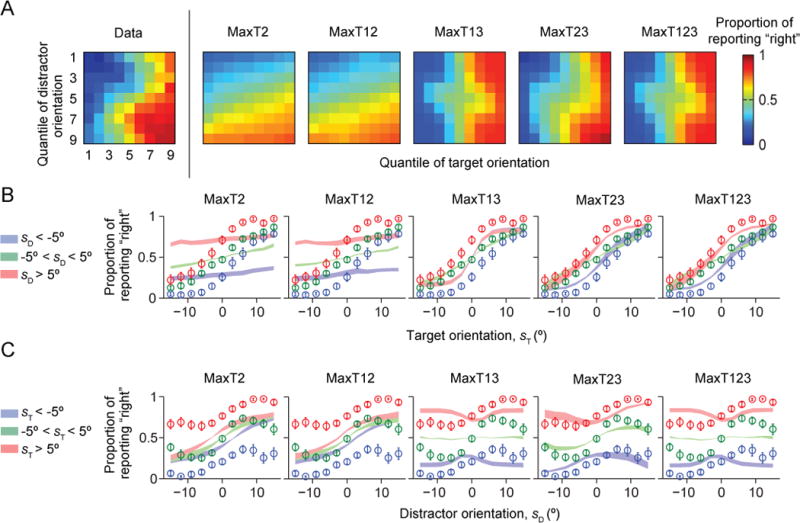
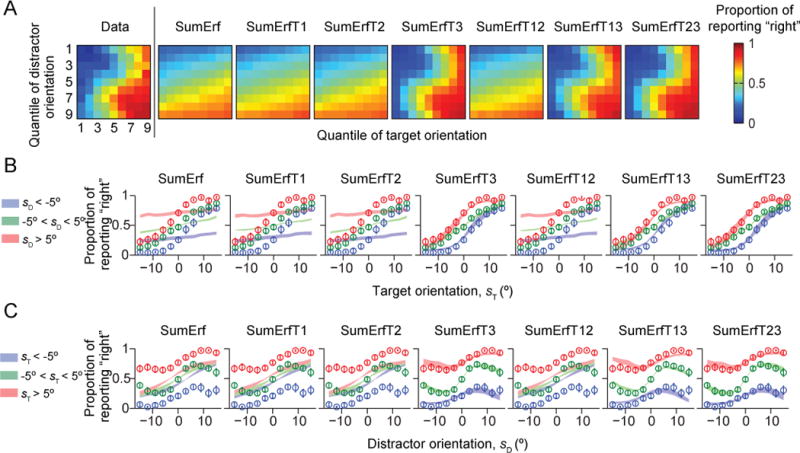
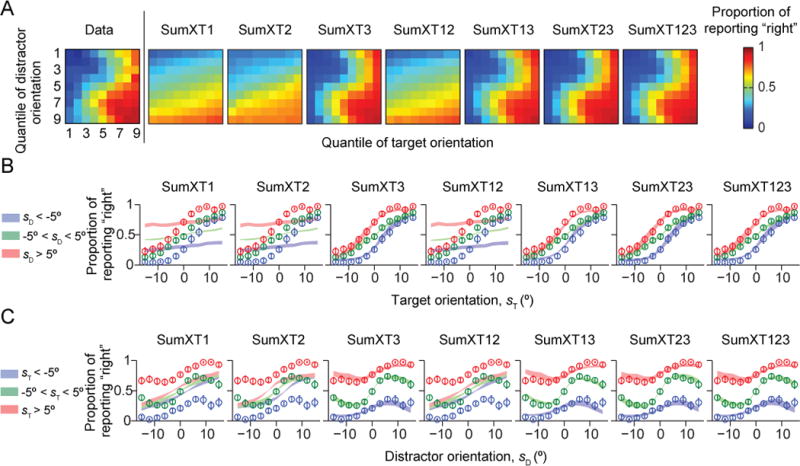
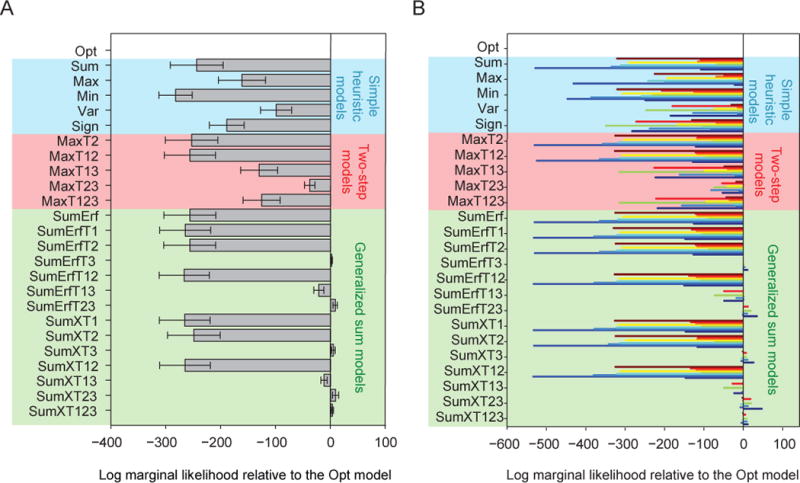
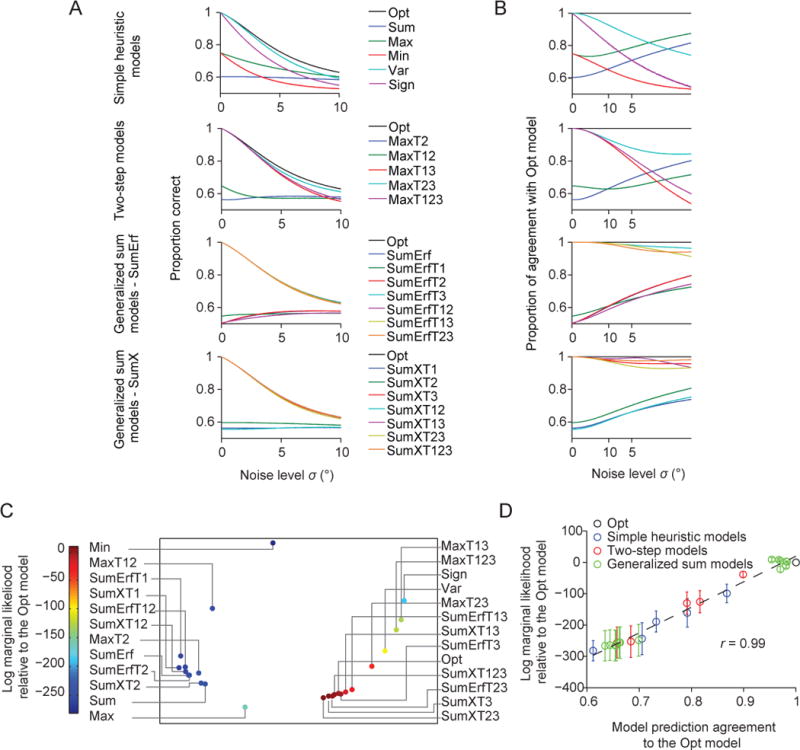
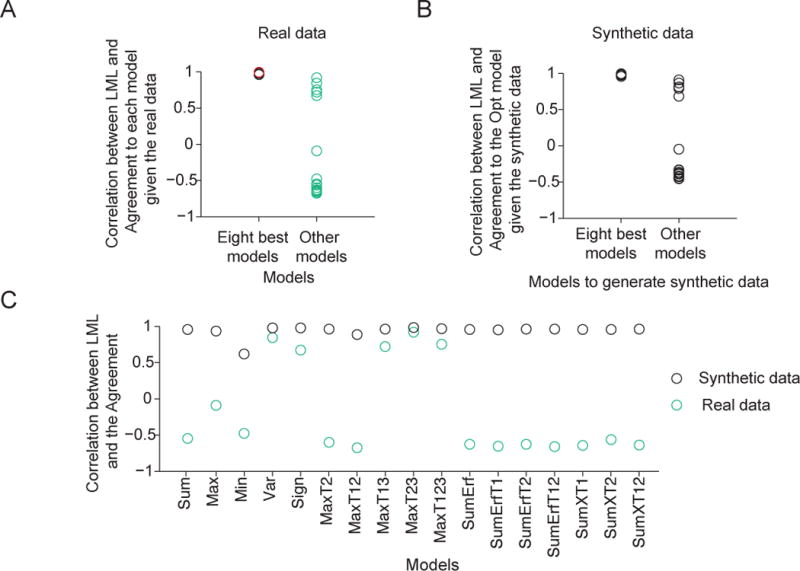
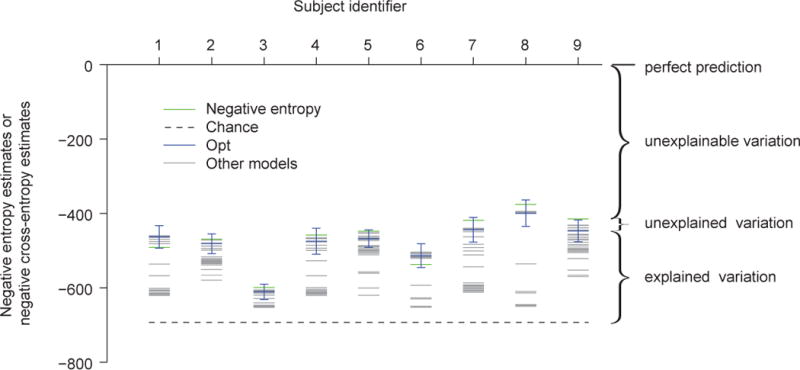
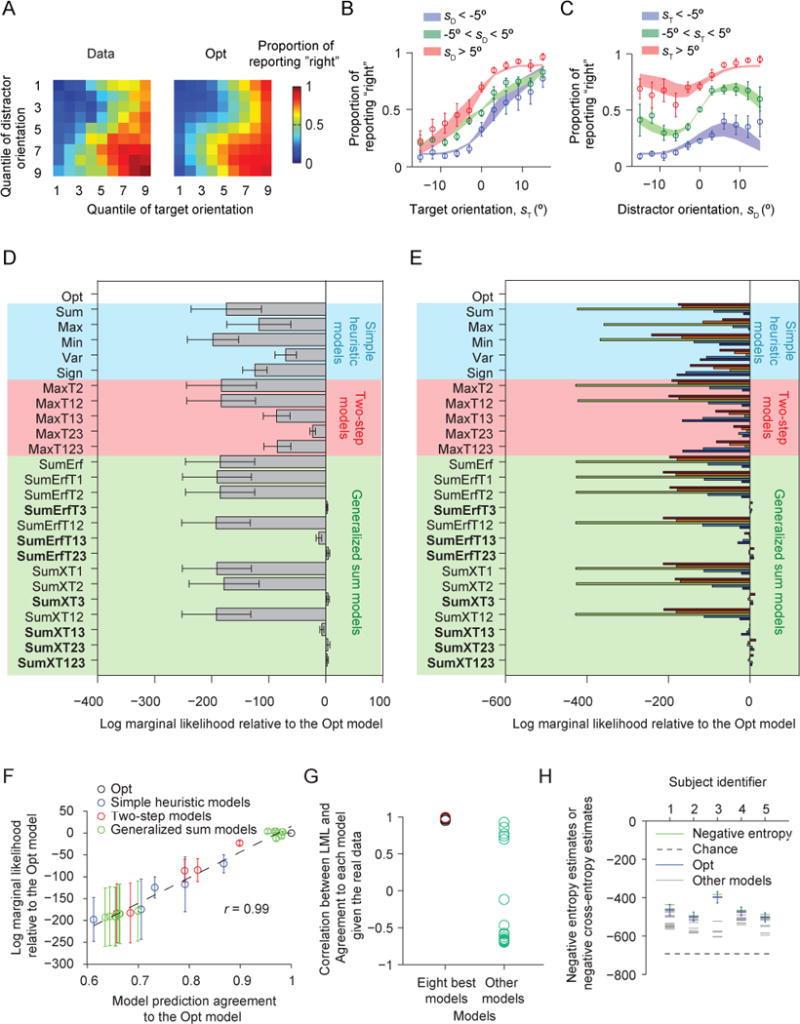
Similar articles
-
Optimality and heuristics in perceptual neuroscience.Nat Neurosci. 2019 Apr;22(4):514-523. doi: 10.1038/s41593-019-0340-4. Epub 2019 Feb 25. Nat Neurosci. 2019. PMID: 30804531 Review.
-
Requiem for the max rule?Vision Res. 2015 Nov;116(Pt B):179-93. doi: 10.1016/j.visres.2014.12.019. Epub 2015 Jan 10. Vision Res. 2015. PMID: 25584425 Free PMC article.
-
Adaptive sampling of information in perceptual decision-making.PLoS One. 2013 Nov 27;8(11):e78993. doi: 10.1371/journal.pone.0078993. eCollection 2013. PLoS One. 2013. PMID: 24312172 Free PMC article.
-
Breaking the rules in perceptual information integration.Cogn Psychol. 2017 Jun;95:1-16. doi: 10.1016/j.cogpsych.2017.03.001. Epub 2017 Apr 6. Cogn Psychol. 2017. PMID: 28391054
-
Bayesian Decision Models: A Primer.Neuron. 2019 Oct 9;104(1):164-175. doi: 10.1016/j.neuron.2019.09.037. Neuron. 2019. PMID: 31600512 Review.
Cited by
-
The Importance of Social Support in Recovery Populations: Toward a Multilevel Understanding.Alcohol Treat Q. 2023;41(2):222-236. doi: 10.1080/07347324.2023.2181119. Epub 2023 Feb 28. Alcohol Treat Q. 2023. PMID: 37312815 Free PMC article.
-
Circular inference in bistable perception.J Vis. 2020 Apr 9;20(4):12. doi: 10.1167/jov.20.4.12. J Vis. 2020. PMID: 32315404 Free PMC article.
-
Using the past to estimate sensory uncertainty.Elife. 2020 Dec 15;9:e54172. doi: 10.7554/eLife.54172. Elife. 2020. PMID: 33319749 Free PMC article.
-
Optimality and heuristics in perceptual neuroscience.Nat Neurosci. 2019 Apr;22(4):514-523. doi: 10.1038/s41593-019-0340-4. Epub 2019 Feb 25. Nat Neurosci. 2019. PMID: 30804531 Review.
-
Imperfect Bayesian inference in visual perception.PLoS Comput Biol. 2019 Apr 18;15(4):e1006465. doi: 10.1371/journal.pcbi.1006465. eCollection 2019 Apr. PLoS Comput Biol. 2019. PMID: 30998675 Free PMC article.
References
-
- Alais D, Burr D. Ventriloquist Effect Results from Near-Optimal Bimodal Integration. Current Biology. 2004;14(3):257–262. - PubMed
-
- Ashby FG, Maddox WT. Human category learning. Annual Review of Psychology. 2005;56:149–178. - PubMed
-
- Baldassi S, Burr DC. Feature-based integration of orientation signals in visual search. Vision Research. 2000;40:1293–1300. - PubMed
-
- Baldassi S, Verghese P. Comparing integration rules in visual search. Journal of Vision. 2002;2:559–570. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
