

A Framework for the Comparative Assessment of Neuronal Spike Sorting Algorithms towards More Accurate Off-Line and On-Line Microelectrode Arrays Data Analysis
- PMID: 27239191
- PMCID: PMC4863096
- DOI: 10.1155/2016/8416237
A Framework for the Comparative Assessment of Neuronal Spike Sorting Algorithms towards More Accurate Off-Line and On-Line Microelectrode Arrays Data Analysis
Abstract
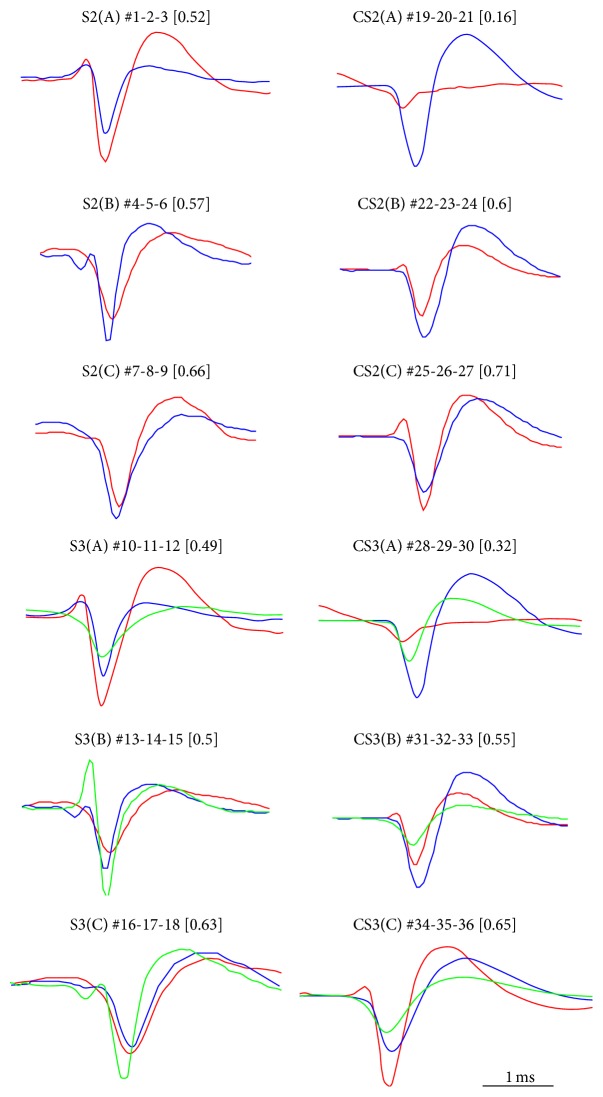
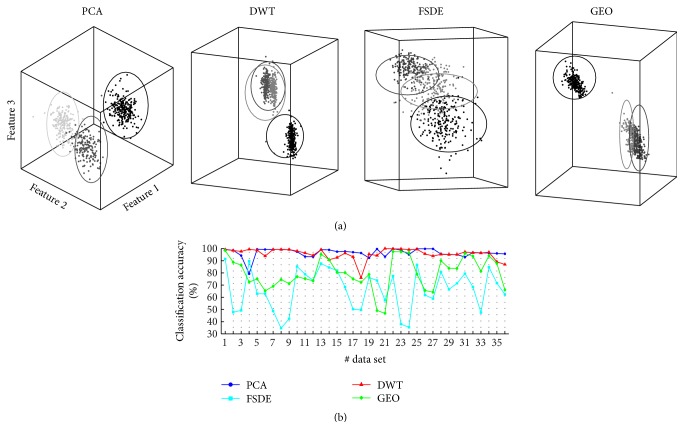
Neuronal spike sorting algorithms are designed to retrieve neuronal network activity on a single-cell level from extracellular multiunit recordings with Microelectrode Arrays (MEAs). In typical analysis of MEA data, one spike sorting algorithm is applied indiscriminately to all electrode signals. However, this approach neglects the dependency of algorithms' performances on the neuronal signals properties at each channel, which require data-centric methods. Moreover, sorting is commonly performed off-line, which is time and memory consuming and prevents researchers from having an immediate glance at ongoing experiments. The aim of this work is to provide a versatile framework to support the evaluation and comparison of different spike classification algorithms suitable for both off-line and on-line analysis. We incorporated different spike sorting "building blocks" into a Matlab-based software, including 4 feature extraction methods, 3 feature clustering methods, and 1 template matching classifier. The framework was validated by applying different algorithms on simulated and real signals from neuronal cultures coupled to MEAs. Moreover, the system has been proven effective in running on-line analysis on a standard desktop computer, after the selection of the most suitable sorting methods. This work provides a useful and versatile instrument for a supported comparison of different options for spike sorting towards more accurate off-line and on-line MEA data analysis.
Figures








References
-
- Gibson S., Judy J. W., Marković D. Spike sorting: the first step in decoding the brain: the first step in decoding the brain. IEEE Signal Processing Magazine. 2012;29(1):124–143. doi: 10.1109/msp.2011.941880. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
