

Mining 3D genome structure populations identifies major factors governing the stability of regulatory communities
- PMID: 27240697
- PMCID: PMC4895025
- DOI: 10.1038/ncomms11549
Mining 3D genome structure populations identifies major factors governing the stability of regulatory communities
Abstract
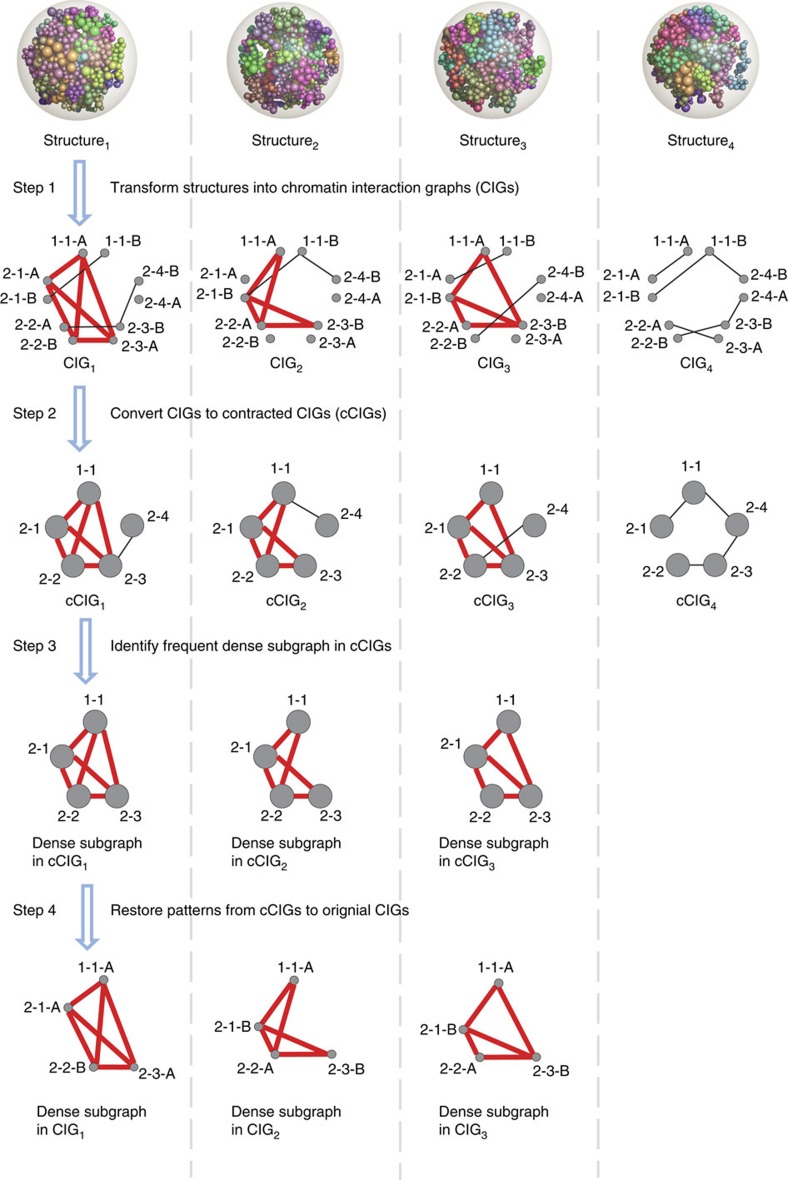
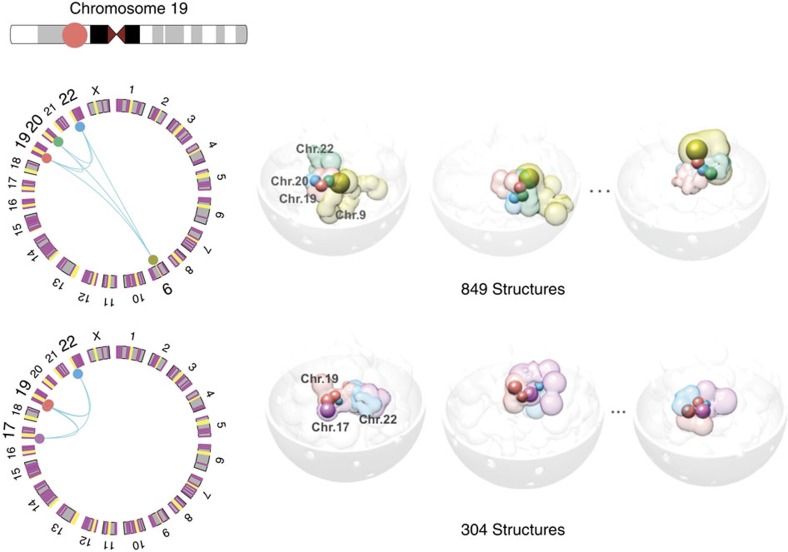
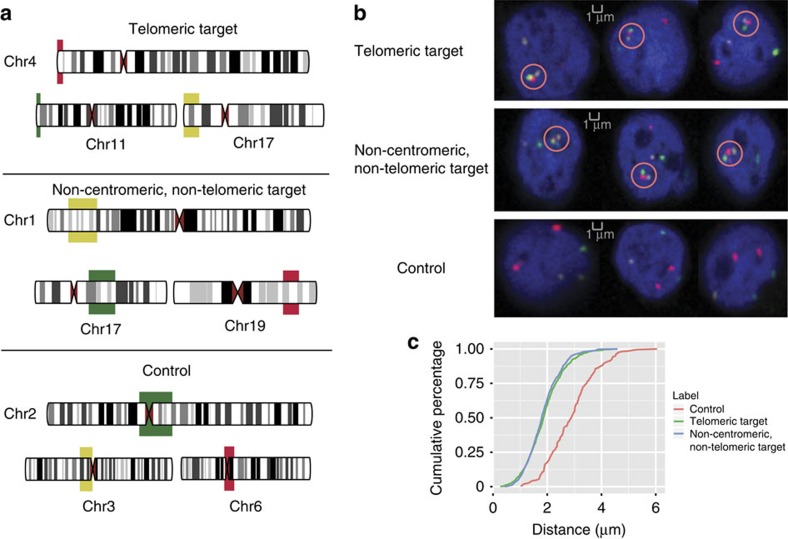
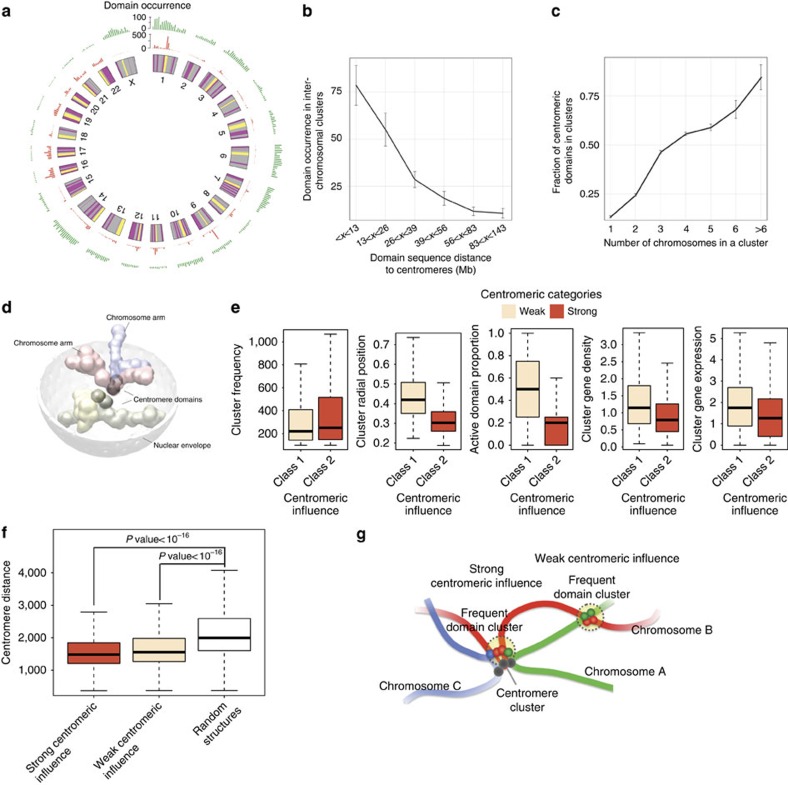
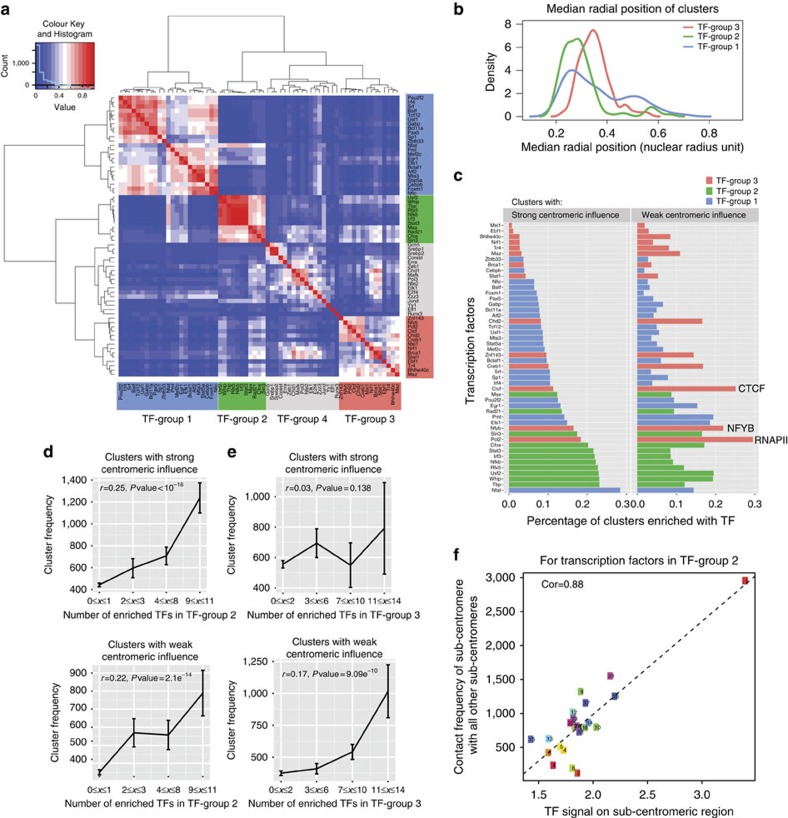
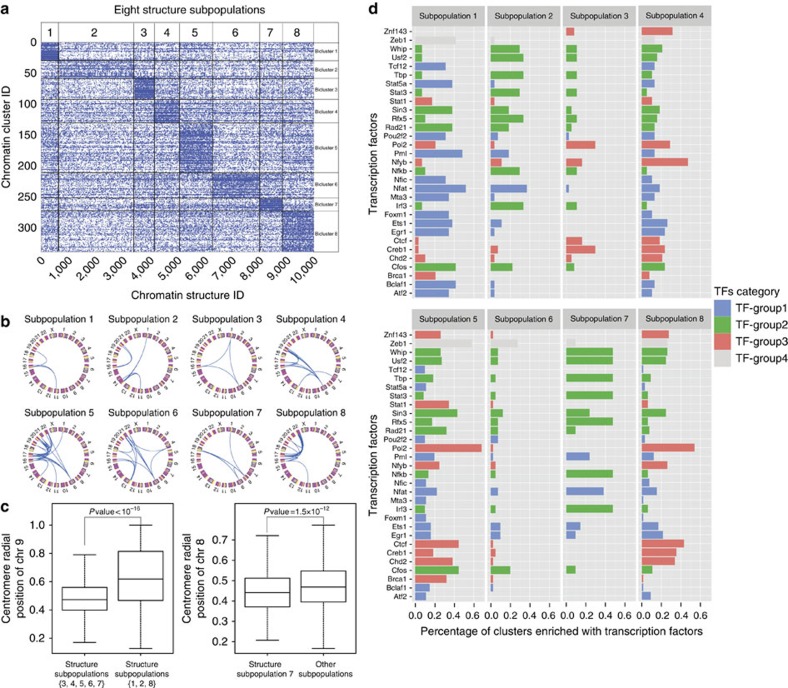
Three-dimensional (3D) genome structures vary from cell to cell even in an isogenic sample. Unlike protein structures, genome structures are highly plastic, posing a significant challenge for structure-function mapping. Here we report an approach to comprehensively identify 3D chromatin clusters that each occurs frequently across a population of genome structures, either deconvoluted from ensemble-averaged Hi-C data or from a collection of single-cell Hi-C data. Applying our method to a population of genome structures (at the macrodomain resolution) of lymphoblastoid cells, we identify an atlas of stable inter-chromosomal chromatin clusters. A large number of these clusters are enriched in binding of specific regulatory factors and are therefore defined as 'Regulatory Communities.' We reveal two major factors, centromere clustering and transcription factor binding, which significantly stabilize such communities. Finally, we show that the regulatory communities differ substantially from cell to cell, indicating that expression variability could be impacted by genome structures.
Figures
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
