

Simultaneous prediction of enzyme orthologs from chemical transformation patterns for de novo metabolic pathway reconstruction
- PMID: 27307627
- PMCID: PMC4908344
- DOI: 10.1093/bioinformatics/btw260
Simultaneous prediction of enzyme orthologs from chemical transformation patterns for de novo metabolic pathway reconstruction
Abstract
Motivation: Metabolic pathways are an important class of molecular networks consisting of compounds, enzymes and their interactions. The understanding of global metabolic pathways is extremely important for various applications in ecology and pharmacology. However, large parts of metabolic pathways remain unknown, and most organism-specific pathways contain many missing enzymes.
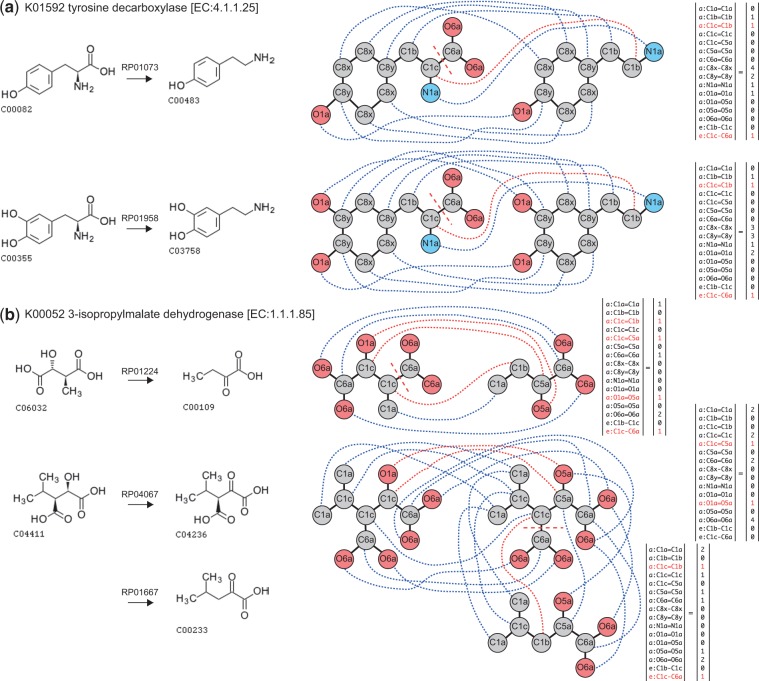
Results: In this study we propose a novel method to predict the enzyme orthologs that catalyze the putative reactions to facilitate the de novo reconstruction of metabolic pathways from metabolome-scale compound sets. The algorithm detects the chemical transformation patterns of substrate-product pairs using chemical graph alignments, and constructs a set of enzyme-specific classifiers to simultaneously predict all the enzyme orthologs that could catalyze the putative reactions of the substrate-product pairs in the joint learning framework. The originality of the method lies in its ability to make predictions for thousands of enzyme orthologs simultaneously, as well as its extraction of enzyme-specific chemical transformation patterns of substrate-product pairs. We demonstrate the usefulness of the proposed method by applying it to some ten thousands of metabolic compounds, and analyze the extracted chemical transformation patterns that provide insights into the characteristics and specificities of enzymes. The proposed method will open the door to both primary (central) and secondary metabolism in genomics research, increasing research productivity to tackle a wide variety of environmental and public health matters.
Contact: : maskot@bio.titech.ac.jp.
© The Author 2016. Published by Oxford University Press.
Figures





References
-
- Afendi F. et al. (2012) KNApSAcK family databases: integrated metabolite-plant species databases for multifaceted plant research Plant Cell Physiol., 53, e1.. - PubMed
-
- Darvas F. (1988) Predicting metabolic pathways by logic programming. J. Mol. Graphics, 6, 80–86.
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
