

Data-Driven Approach To Determine Popular Proteins for Targeted Proteomics Translation of Six Organ Systems
- PMID: 27356587
- PMCID: PMC5120959
- DOI: 10.1021/acs.jproteome.6b00095
Data-Driven Approach To Determine Popular Proteins for Targeted Proteomics Translation of Six Organ Systems
Abstract
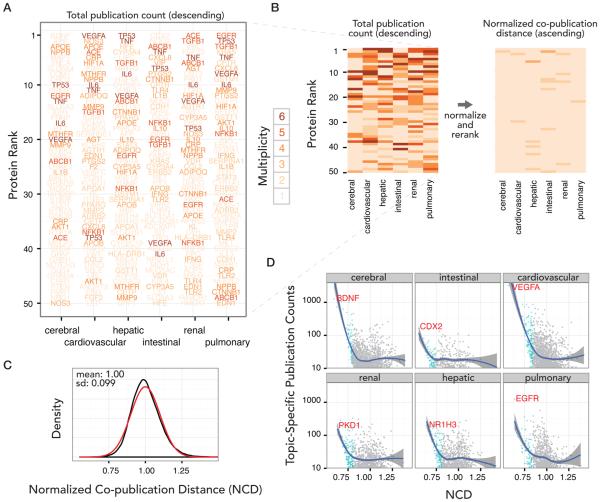
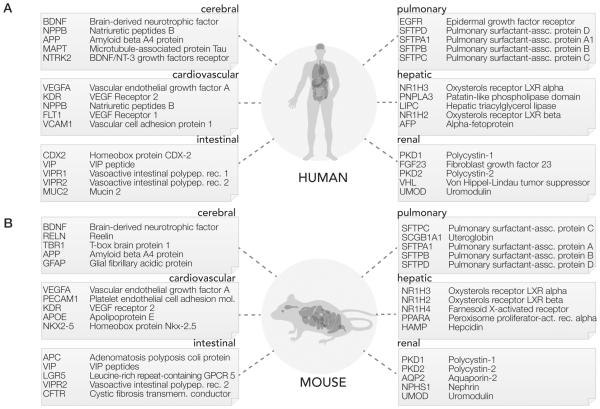
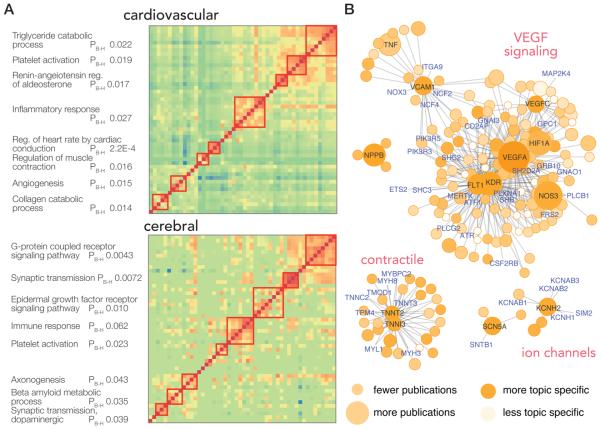
Amidst the proteomes of human tissues lie subsets of proteins that are closely involved in conserved pathophysiological processes. Much of biomedical research concerns interrogating disease signature proteins and defining their roles in disease mechanisms. With advances in proteomics technologies, it is now feasible to develop targeted proteomics assays that can accurately quantify protein abundance as well as their post-translational modifications; however, with rapidly accumulating number of studies implicating proteins in diseases, current resources are insufficient to target every protein without judiciously prioritizing the proteins with high significance and impact for assay development. We describe here a data science method to prioritize and expedite assay development on high-impact proteins across research fields by leveraging the biomedical literature record to rank and normalize proteins that are popularly and preferentially published by biomedical researchers. We demonstrate this method by finding priority proteins across six major physiological systems (cardiovascular, cerebral, hepatic, renal, pulmonary, and intestinal). The described method is data-driven and builds upon the collective knowledge of previous publications referenced on PubMed to lend objectivity to target selection. The method and resulting popular protein lists may also be useful for exploring biological processes associated with various physiological systems and research topics, in addition to benefiting ongoing efforts to facilitate the broad translation of proteomics technologies.
Keywords: bibliometrics; common proteins; data science; human tissue convergence; proteomics translation; semantics; targeted proteomics.
Figures

References
-
- Grote E, Fu Q, Ji W, Liu X, Van Eyk JE. Using pure protein to build a multiple reaction monitoring mass spectrometry assay for targeted detection and quantitation. Methods Mol. Biol. 2013;1005:199–213. - PubMed
-
- Li X.-j., Hayward C, Fong P-Y, Dominguez M, Hunsucker SW, Lee LW, McLean M, Law S, Butler H, Schirm M, Gingras O, Lamontagne J, Allard R, Chelsky D, Price ND, Lam S, Massion PP, Pass H, Rom WN, Vachani A, Fang KC, Hood L, Kearney P. A blood-based proteomic classifier for the molecular characterization of pulmonary nodules. Sci. Transl. Med. 2013;5:207ra142. - PMC - PubMed
-
- Huttenhain R, Soste M, Selevsek N, Rost H, Sethi A, Carapito C, Farrah T, Deutsch EW, Kusebauch U, Moritz RL, Nimeus-Malmstrom E, Rinner O, Aebersold R. Reproducible quantification of cancer-associated proteins in body fluids using targeted proteomics. Sci. Transl. Med. 2012;4:142ra94–142ra94. - PMC - PubMed
-
- Nanjappa V, Thomas JK, Marimuthu A, Muthusamy B, Radhakrishnan A, Sharma R, Ahmad Khan A, Balakrishnan L, Sahasrabuddhe NA, Kumar S, Jhaveri BN, Sheth KV, Kumar Khatana R, Shaw PG, Srikanth SM, Mathur PP, Shankar S, Nagaraja D, Christopher R, Mathivanan S, Raju R, Sirdeshmukh R, Chatterjee A, Simpson RJ, Harsha HC, Pandey A, Prasad TS. Plasma Proteome Database as a resource for proteomics research: 2014 update. Nucleic Acids Res. 2014;42:D959–65. - PMC - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
