

Active inference and learning
- PMID: 27375276
- PMCID: PMC5167251
- DOI: 10.1016/j.neubiorev.2016.06.022
Active inference and learning
Abstract
This paper offers an active inference account of choice behaviour and learning. It focuses on the distinction between goal-directed and habitual behaviour and how they contextualise each other. We show that habits emerge naturally (and autodidactically) from sequential policy optimisation when agents are equipped with state-action policies. In active inference, behaviour has explorative (epistemic) and exploitative (pragmatic) aspects that are sensitive to ambiguity and risk respectively, where epistemic (ambiguity-resolving) behaviour enables pragmatic (reward-seeking) behaviour and the subsequent emergence of habits. Although goal-directed and habitual policies are usually associated with model-based and model-free schemes, we find the more important distinction is between belief-free and belief-based schemes. The underlying (variational) belief updating provides a comprehensive (if metaphorical) process theory for several phenomena, including the transfer of dopamine responses, reversal learning, habit formation and devaluation. Finally, we show that active inference reduces to a classical (Bellman) scheme, in the absence of ambiguity.
Keywords: Active inference; Bayesian inference; Bayesian surprise; Epistemic value; Exploitation; Exploration; Free energy; Goal-directed; Habit learning; Information gain.
Copyright © 2016 The Authors. Published by Elsevier Ltd.. All rights reserved.
Figures
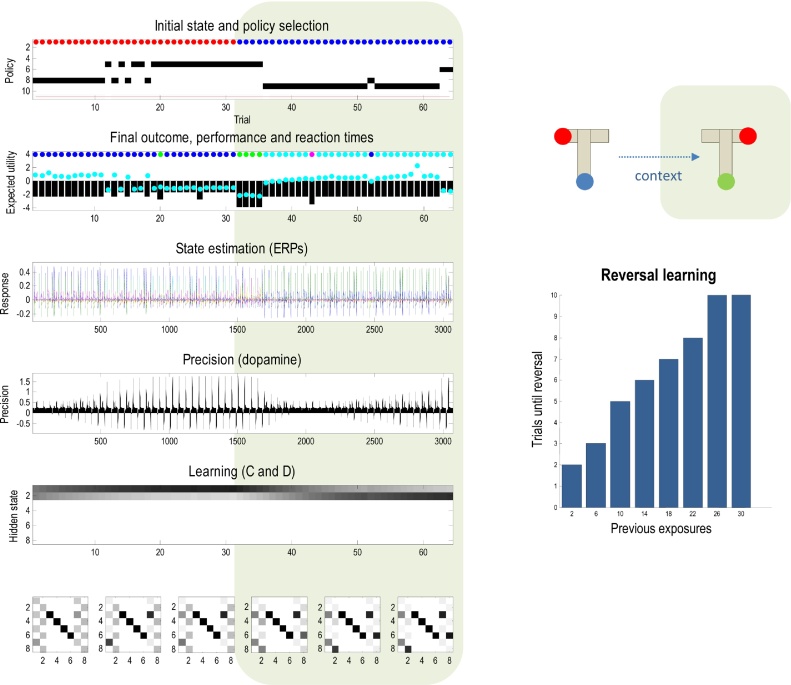
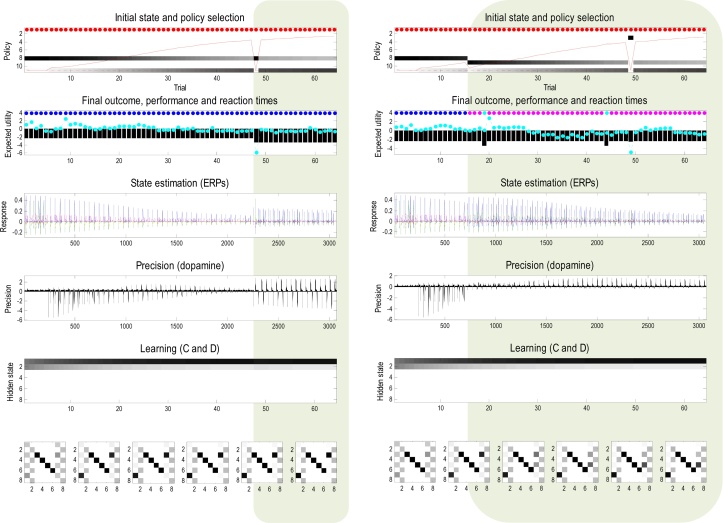
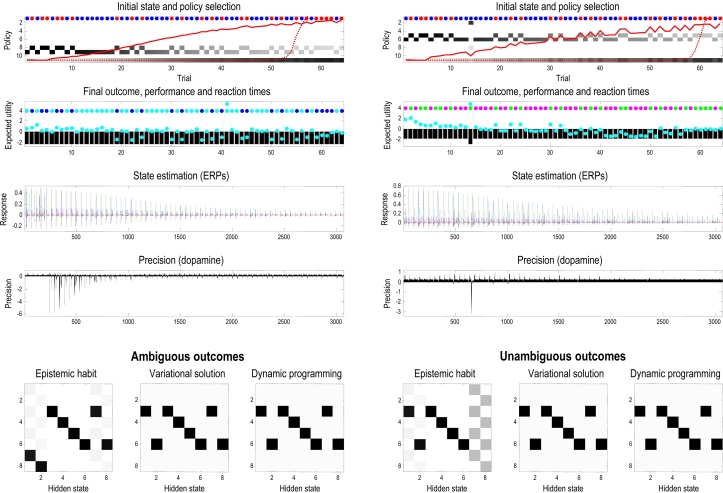
References
-
- Abbott L.F., Nelson S. Synaptic plasticity: taming the beast. Nat. Neurosci. 2000;3:1178–1183. - PubMed
-
- Attias H. Planning by probabilistic inference. Proceedings of the 9th International Workshop on Artificial Intelligence and Statistics. 2003
-
- Balleine B.W., Dickinson A. Goal-directed instrumental action: contingency and incentive learning and their cortical substrates. Neuropharmacology. 1998;37(4-5):407–419. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
