

Causal inference and the data-fusion problem
- PMID: 27382148
- PMCID: PMC4941504
- DOI: 10.1073/pnas.1510507113
Causal inference and the data-fusion problem
Abstract
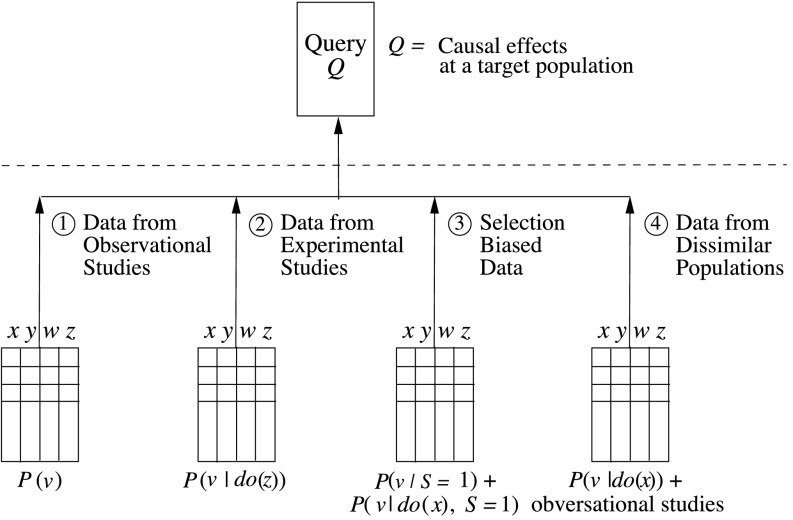
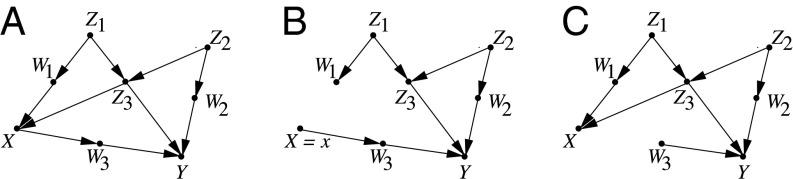
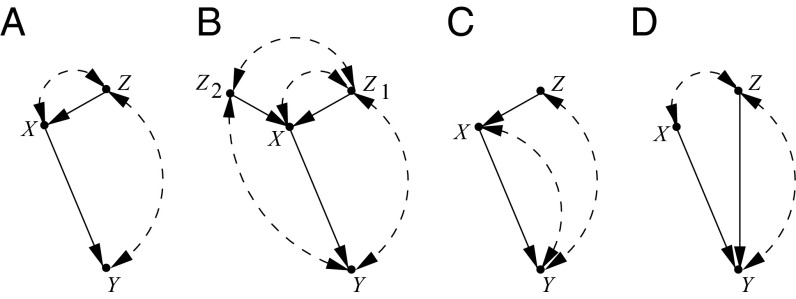
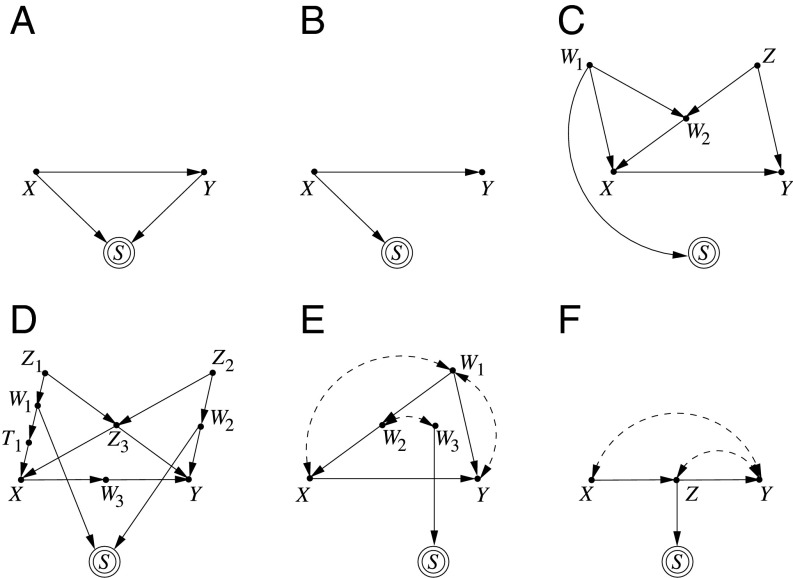
We review concepts, principles, and tools that unify current approaches to causal analysis and attend to new challenges presented by big data. In particular, we address the problem of data fusion-piecing together multiple datasets collected under heterogeneous conditions (i.e., different populations, regimes, and sampling methods) to obtain valid answers to queries of interest. The availability of multiple heterogeneous datasets presents new opportunities to big data analysts, because the knowledge that can be acquired from combined data would not be possible from any individual source alone. However, the biases that emerge in heterogeneous environments require new analytical tools. Some of these biases, including confounding, sampling selection, and cross-population biases, have been addressed in isolation, largely in restricted parametric models. We here present a general, nonparametric framework for handling these biases and, ultimately, a theoretical solution to the problem of data fusion in causal inference tasks.
Keywords: causal inference; counterfactuals; external validity; selection bias; transportability.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Pearl J. 2009. Causality: Models, Reasoning, and Inference (Cambridge Univ Press, New York), 2nd Ed.
-
- Pearl J. Causal inference in statistics: An overview. Stat Surv. 2009;3:96–146.
-
- Pearl J, Glymour M, Jewell NP. 2016 Causal Inference in Statistics: A Primer (Wiley, New York)
-
- Angrist J, Imbens G, Rubin D. Identification of causal effects using instrumental variables (with comments) J Am Stat Assoc. 1996;91(434):444–472.
-
- Greenland S, Lash T. In: Bias Analysis in Modern Epidemiology. 3rd Ed. Rothman K, Greenland S, Lash T, editors. Lippincott Williams & Wilkins; Philadelphia: 2008. pp. 345–380.
LinkOut - more resources
Full Text Sources
Other Literature Sources
