

Boosting medical diagnostics by pooling independent judgments
- PMID: 27432950
- PMCID: PMC4978286
- DOI: 10.1073/pnas.1601827113
Boosting medical diagnostics by pooling independent judgments
Abstract
Collective intelligence refers to the ability of groups to outperform individual decision makers when solving complex cognitive problems. Despite its potential to revolutionize decision making in a wide range of domains, including medical, economic, and political decision making, at present, little is known about the conditions underlying collective intelligence in real-world contexts. We here focus on two key areas of medical diagnostics, breast and skin cancer detection. Using a simulation study that draws on large real-world datasets, involving more than 140 doctors making more than 20,000 diagnoses, we investigate when combining the independent judgments of multiple doctors outperforms the best doctor in a group. We find that similarity in diagnostic accuracy is a key condition for collective intelligence: Aggregating the independent judgments of doctors outperforms the best doctor in a group whenever the diagnostic accuracy of doctors is relatively similar, but not when doctors' diagnostic accuracy differs too much. This intriguingly simple result is highly robust and holds across different group sizes, performance levels of the best doctor, and collective intelligence rules. The enabling role of similarity, in turn, is explained by its systematic effects on the number of correct and incorrect decisions of the best doctor that are overruled by the collective. By identifying a key factor underlying collective intelligence in two important real-world contexts, our findings pave the way for innovative and more effective approaches to complex real-world decision making, and to the scientific analyses of those approaches.
Keywords: collective intelligence; dermatology; groups; mammography; medical diagnostics.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
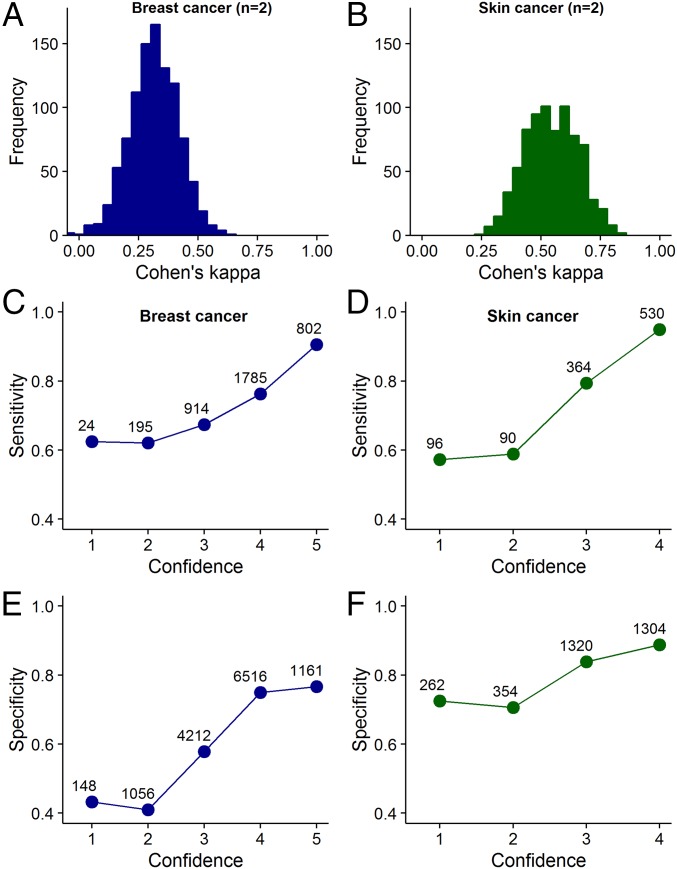
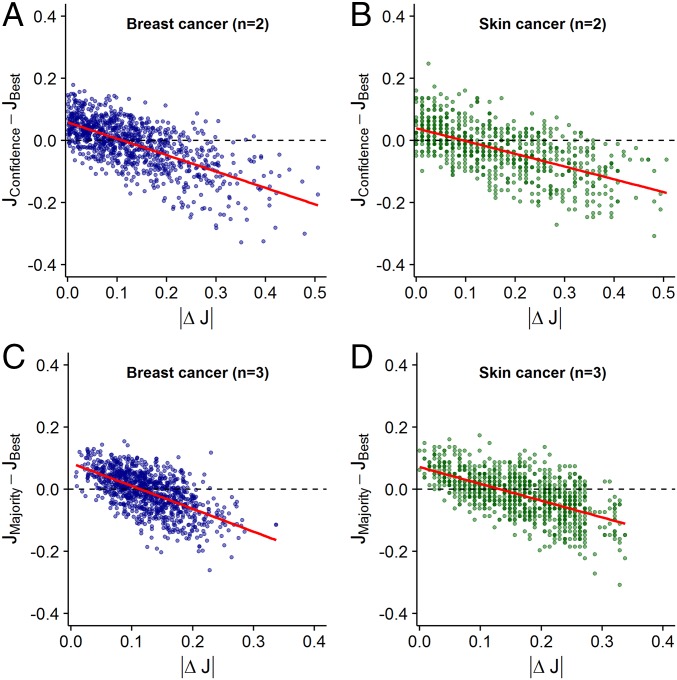
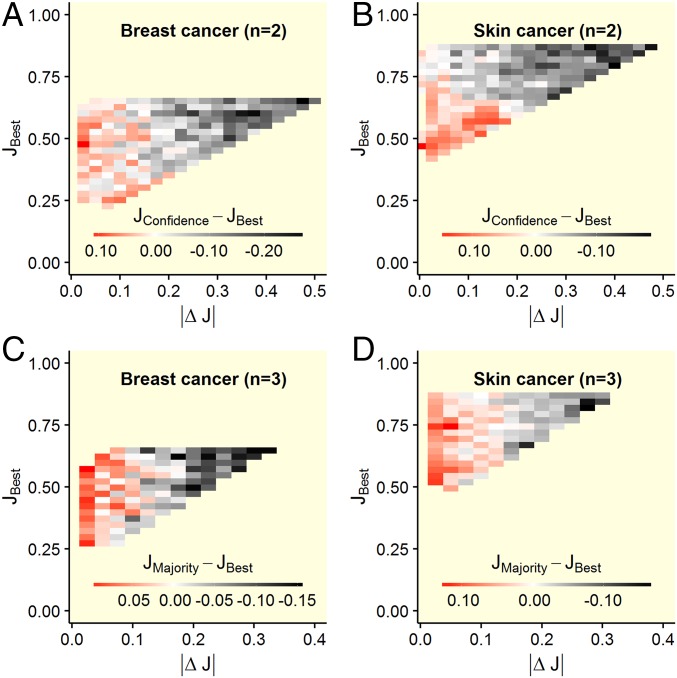
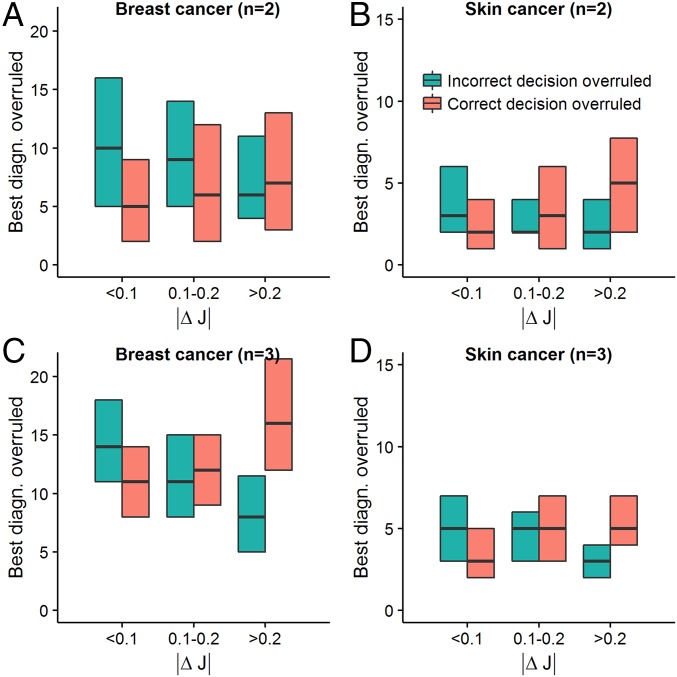
References
-
- Krause J, Ruxton GD, Krause S. Swarm intelligence in animals and humans. Trends Ecol Evol. 2010;25(1):28–34. - PubMed
-
- Woolley AW, Chabris CF, Pentland A, Hashmi N, Malone TW. Evidence for a collective intelligence factor in the performance of human groups. Science. 2010;330(6004):686–688. - PubMed
-
- Bonabeau E, Dorigo M, Theraulaz G. Swarm Intelligence: From Natural to Artificial Systems. Oxford Univ Press; Oxford: 1999.
-
- Surowiecki J. The Wisdom of Crowds: Why the Many Are Smarter Than the Few and How Collective Wisdom Shapes Business, Economies, Societies and Nations. Knopf Doubleday Publishing Group; New York: 2004.
-
- Couzin ID. Collective cognition in animal groups. Trends Cogn Sci. 2009;13(1):36–43. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
