

Predictive decision making driven by multiple time-linked reward representations in the anterior cingulate cortex
- PMID: 27477632
- PMCID: PMC4974652
- DOI: 10.1038/ncomms12327
Predictive decision making driven by multiple time-linked reward representations in the anterior cingulate cortex
Abstract
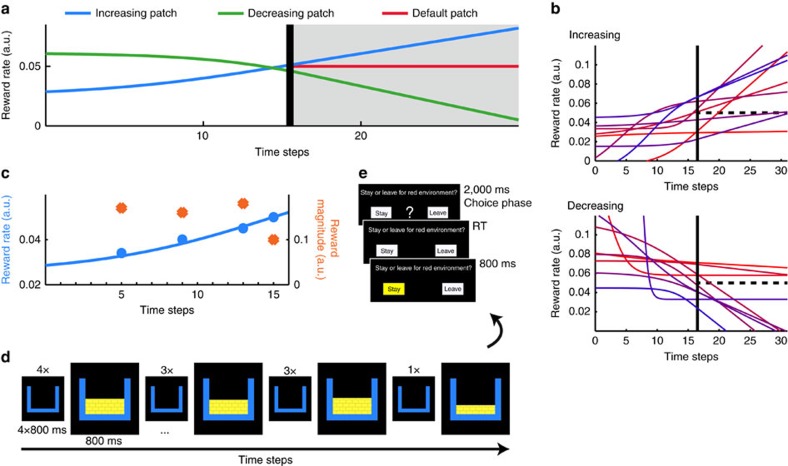
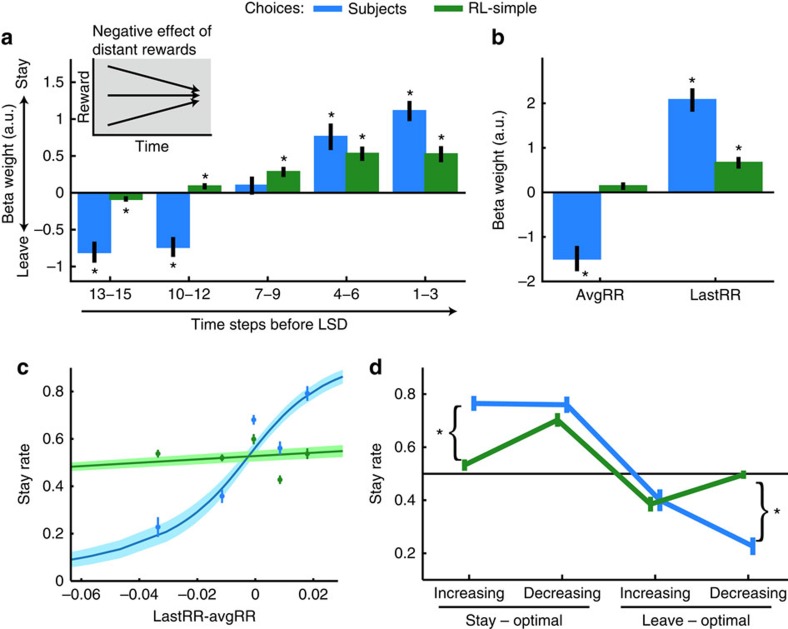
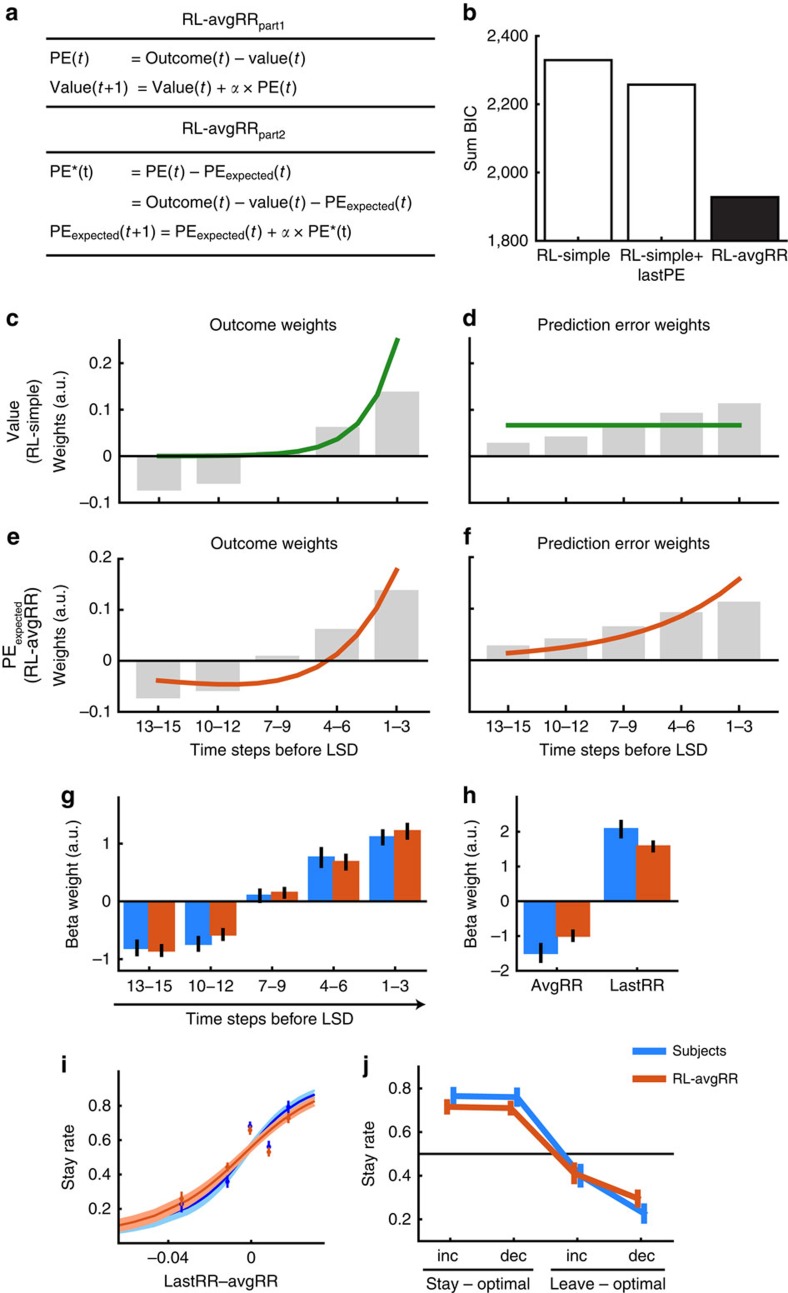
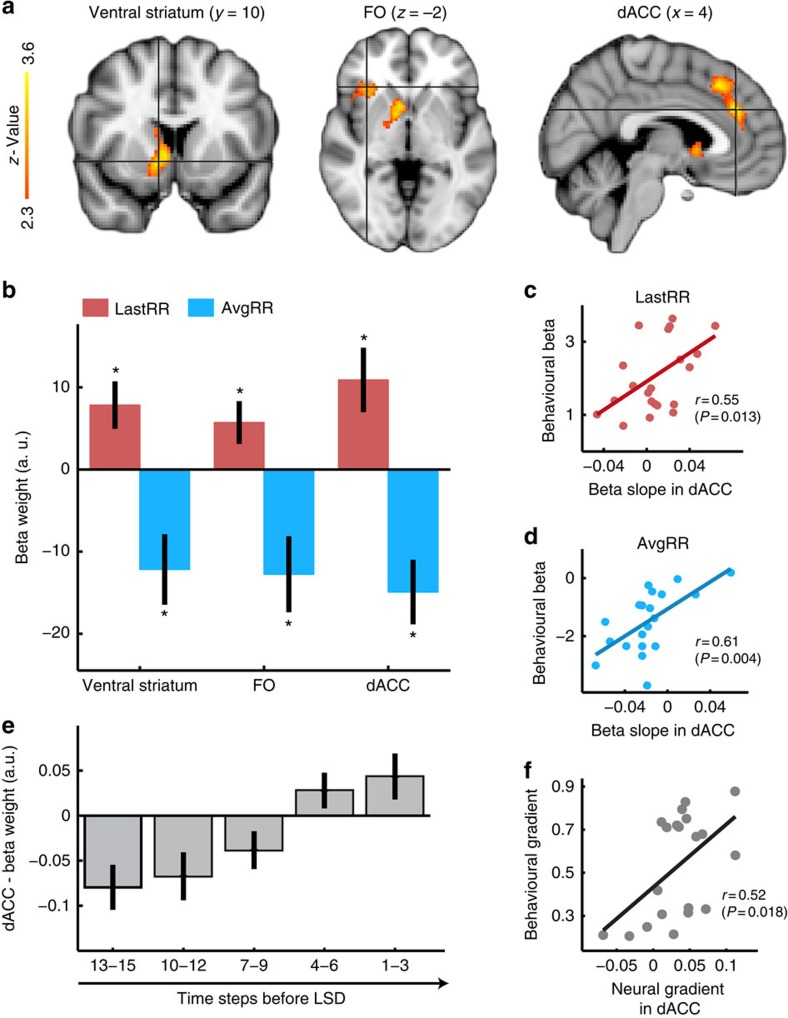
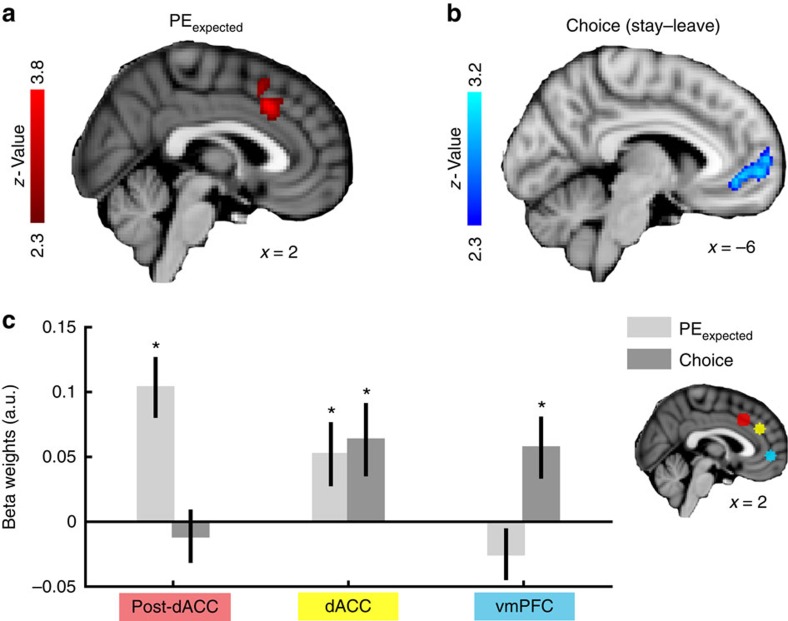
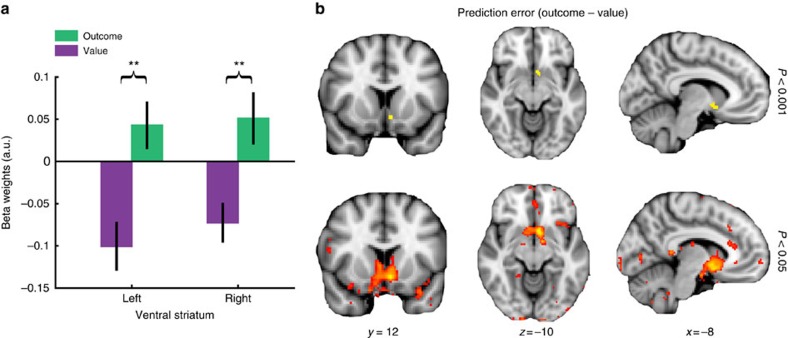
In many natural environments the value of a choice gradually gets better or worse as circumstances change. Discerning such trends makes predicting future choice values possible. We show that humans track such trends by comparing estimates of recent and past reward rates, which they are able to hold simultaneously in the dorsal anterior cingulate cortex (dACC). Comparison of recent and past reward rates with positive and negative decision weights is reflected by opposing dACC signals indexing these quantities. The relative strengths of time-linked reward representations in dACC predict whether subjects persist in their current behaviour or switch to an alternative. Computationally, trend-guided choice can be modelled by using a reinforcement-learning mechanism that computes a longer-term estimate (or expectation) of prediction errors. Using such a model, we find a relative predominance of expected prediction errors in dACC, instantaneous prediction errors in the ventral striatum and choice signals in the ventromedial prefrontal cortex.
Figures
References
-
- Charnov E. Optimal foraging: the marginal value theorem. Theor. Popul. Biol. 9, 129–136 (1976). - PubMed
-
- Stephens D. W. & Krebs J. R. Foraging Theory Princeton University Press (1986).
-
- Boorman E. D., Behrens T. E. J., Woolrich M. W. & Rushworth M. F. S. How green is the grass on the other side? Frontopolar cortex and the evidence in favor of alternative courses of action. Neuron 62, 733–743 (2009). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
