

Detection of Significant Groups in Hierarchical Clustering by Resampling
- PMID: 27551289
- PMCID: PMC4976109
- DOI: 10.3389/fgene.2016.00144
Detection of Significant Groups in Hierarchical Clustering by Resampling
Abstract
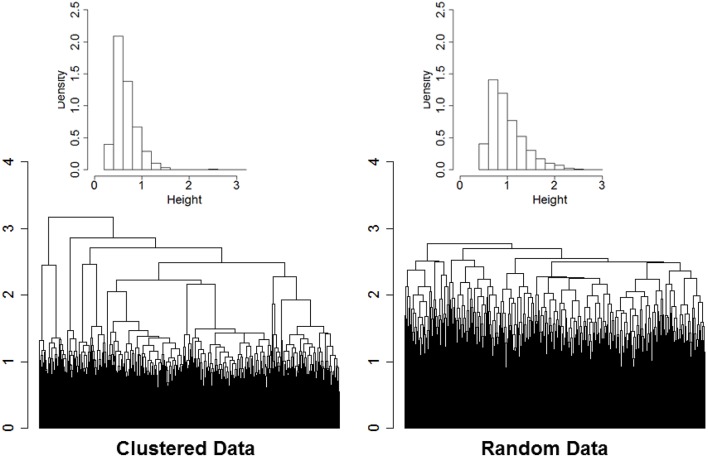
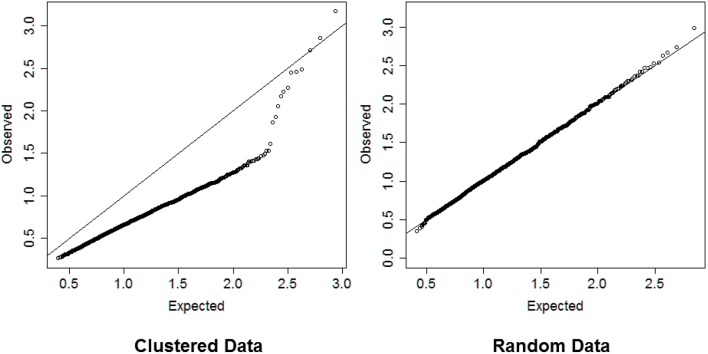
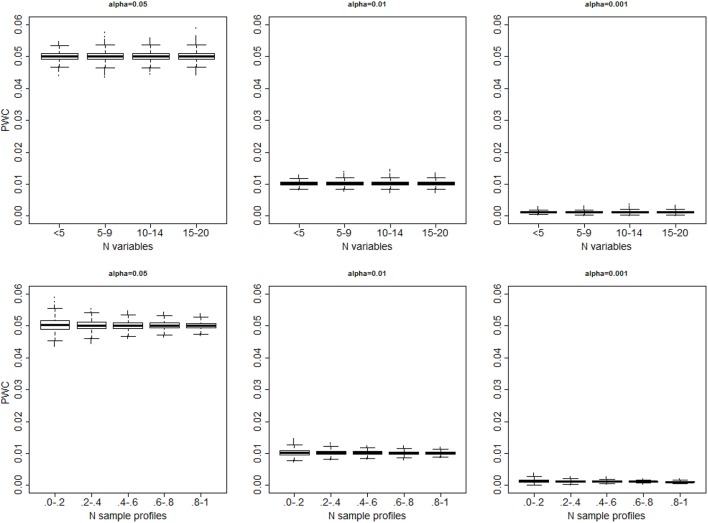
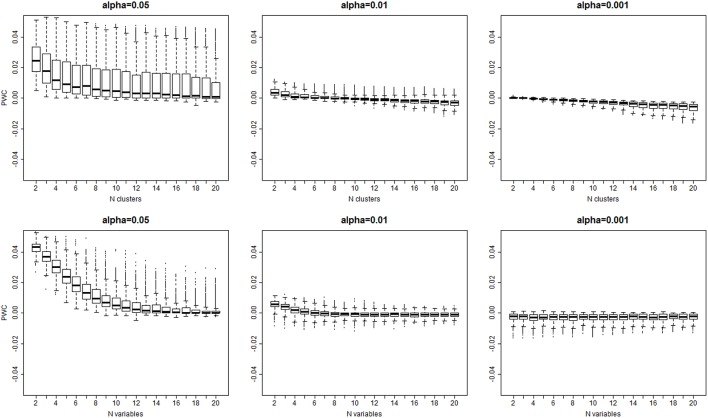
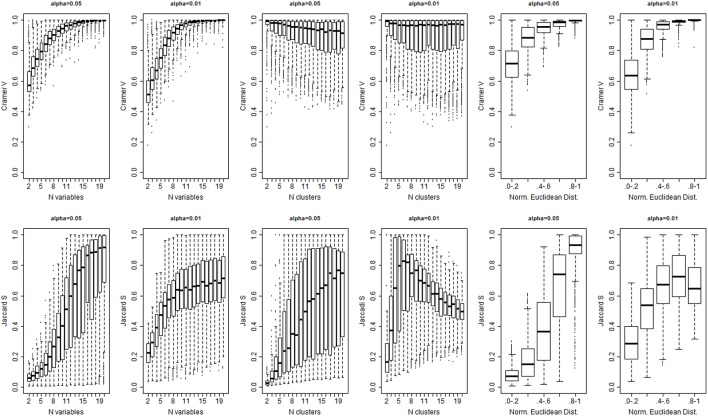
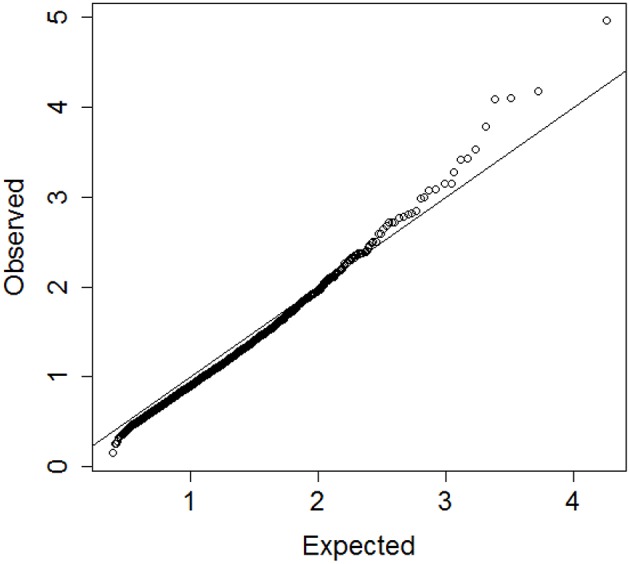
Hierarchical clustering is a simple and reproducible technique to rearrange data of multiple variables and sample units and visualize possible groups in the data. Despite the name, hierarchical clustering does not provide clusters automatically, and "tree-cutting" procedures are often used to identify subgroups in the data by cutting the dendrogram that represents the similarities among groups used in the agglomerative procedure. We introduce a resampling-based technique that can be used to identify cut-points of a dendrogram with a significance level based on a reference distribution for the heights of the branch points. The evaluation on synthetic data shows that the technique is robust in a variety of situations. An example with real biomarker data from the Long Life Family Study shows the usefulness of the method.
Keywords: dendrogram; resampling techniques; tree-cutting procedures.
Figures

References
-
- Beale E. M. L. (1969). Cluster Analysis. London: Scientific Control Systems.
-
- Caliński T., Harabasz J. (1974). A dendrite method for cluster analysis. Comm. Statist. 3, 1–27. 10.1080/03610927408827101 - DOI
-
- Charrad M., Ghazzali N., Boiteau V., Niknafs A. (2014). Nbclust: an r package for determining the relevant number of clusters in a data set. J. Stat. Softw. 61, 1–36. 10.18637/jss.v061.i06 - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources